
利用python写出这个问题的代码,或许要用到anaconda中的其他库,希望能具体一点,能解释一下每个步骤的意思更好
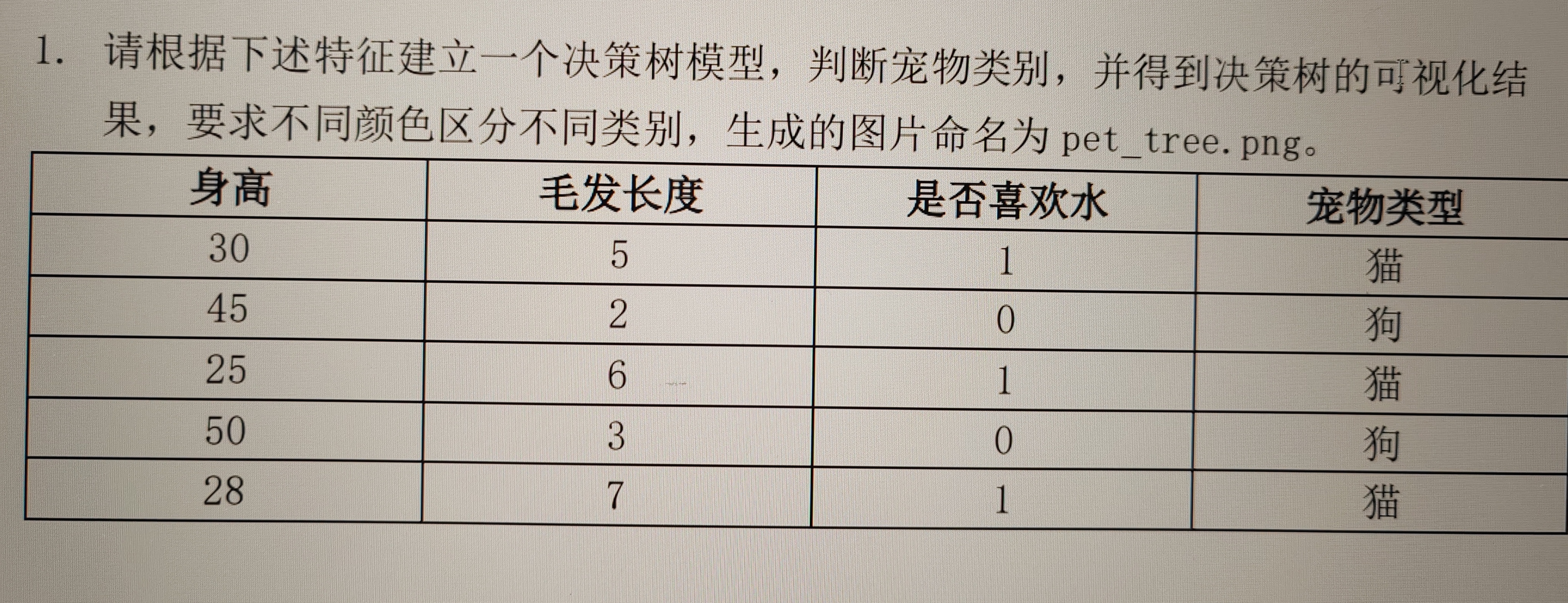

利用python写出这个问题的代码,或许要用到anaconda中的其他库,希望能具体一点,能解释一下每个步骤的意思更好
 分享
分享
 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
根据您的要求,我将提供一个完整的Python代码示例,用于构建决策树模型来判断宠物类别,并使用不同颜色区分不同类别,最后将生成的决策树可视化保存为图片。
首先确保您已安装以下库:
可以使用Anaconda安装这些库:
conda install scikit-learn graphviz python-graphviz matplotlib
# 导入必要的库
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.preprocessing import LabelEncoder
import graphviz
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# 1. 创建示例数据集(假设数据)
# 这里我们创建一个包含宠物特征的虚拟数据集
data = {
'体重': ['轻', '中', '重', '轻', '中', '重', '轻', '中'],
'毛发长度': ['短', '长', '短', '长', '短', '长', '短', '长'],
'叫声': ['高', '低', '高', '低', '高', '低', '高', '低'],
'宠物类别': ['猫', '狗', '猫', '狗', '猫', '狗', '猫', '狗']
}
# 转换为DataFrame
df = pd.DataFrame(data)
# 2. 数据预处理 - 将分类特征转换为数值
label_encoders = {}
for column in df.columns:
le = LabelEncoder()
df[column] = le.fit_transform(df[column])
label_encoders[column] = le
# 3. 准备特征和目标变量
X = df.drop('宠物类别', axis=1) # 特征
y = df['宠物类别'] # 目标变量
# 4. 创建决策树模型
# 设置max_depth控制树深度,避免过拟合
model = DecisionTreeClassifier(max_depth=3, random_state=42)
model.fit(X, y)
# 5. 可视化决策树
# 导出为dot文件
dot_data = export_graphviz(
model,
out_file=None,
feature_names=X.columns,
class_names=label_encoders['宠物类别'].classes_,
filled=True, # 填充颜色
rounded=True, # 圆角
special_characters=True
)
# 使用graphviz渲染
graph = graphviz.Source(dot_data)
# 6. 保存为png文件
graph.render(filename='net_te', format='png', cleanup=True)
print("决策树已保存为 net_te.png")
数据准备:
数据预处理:
模型构建:
可视化:
运行代码后,将在当前目录生成一个名为net_te.png的图片文件,其中:
如果需要使用真实数据,只需替换代码中的data字典为您自己的数据集即可。
分享 系统已结题
5月19日
系统已结题
5月19日 专家已采纳回答
5月11日
专家已采纳回答
5月11日 创建了问题
5月8日
创建了问题
5月8日


