我搞了一个石碑碑刻的文字识别系统,但是识别出来的文字准确率很低如图一,

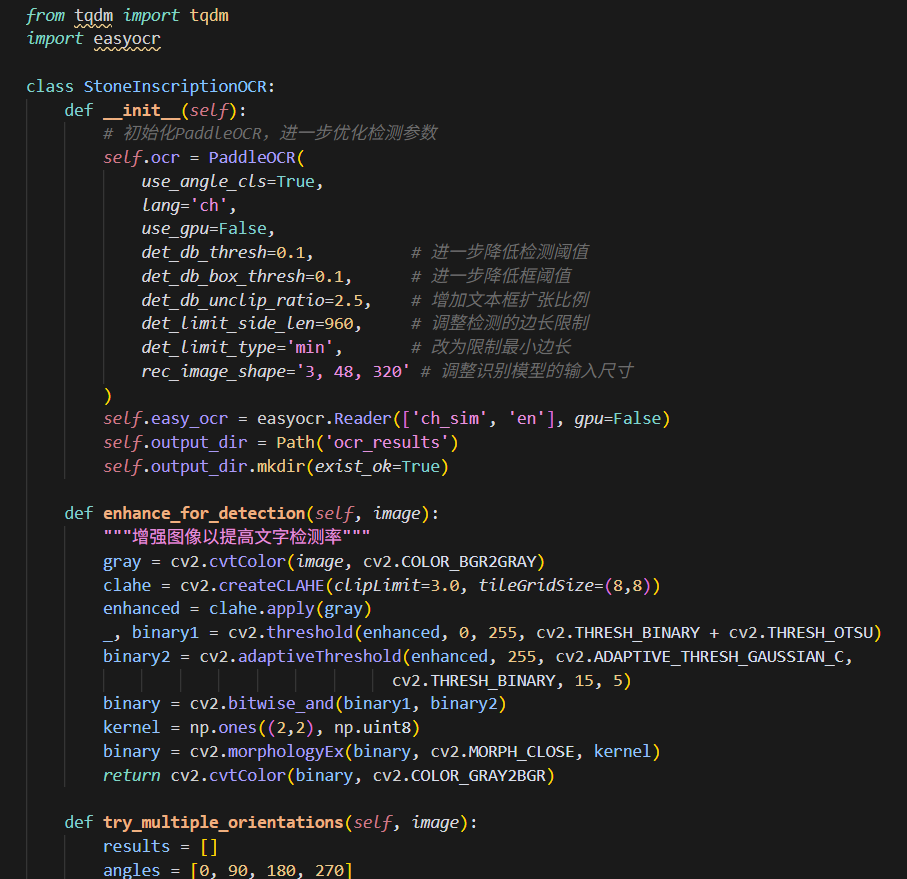
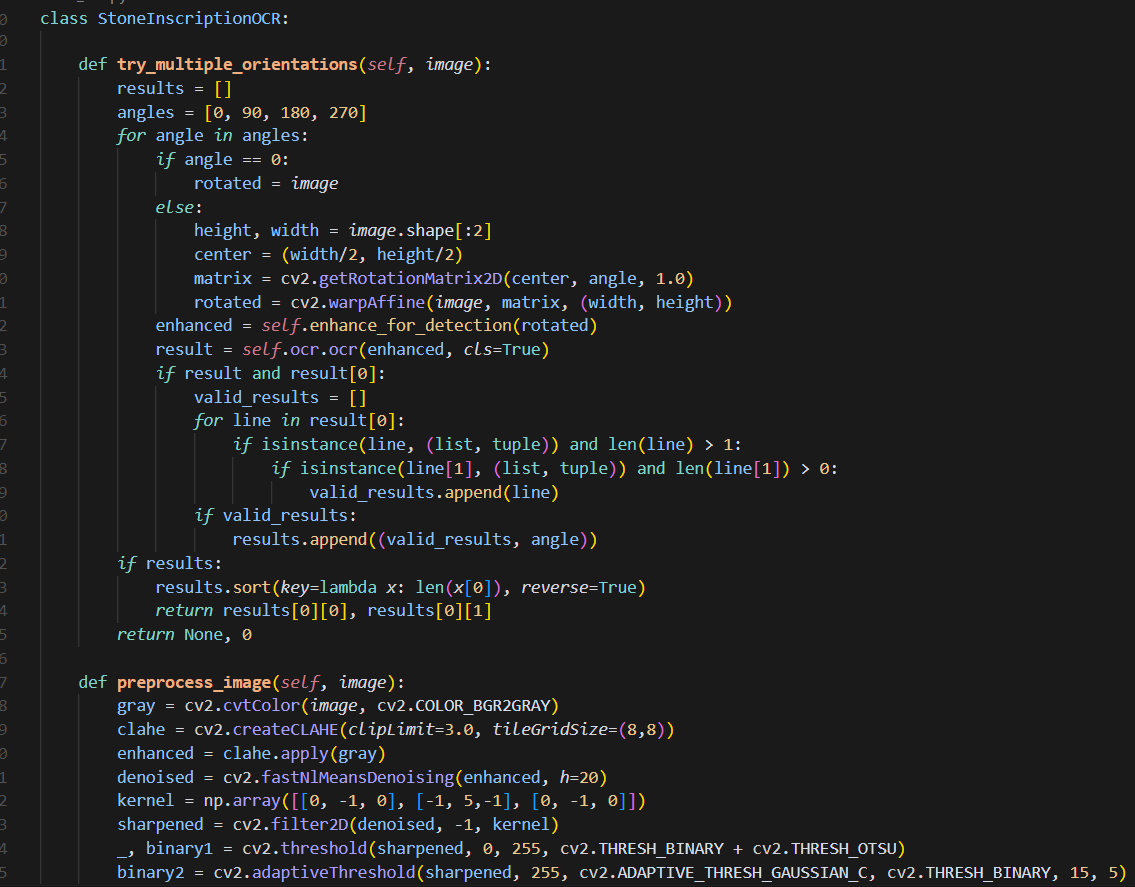
我的识别部分代码如图二
图三
大家能不能帮忙解决一下准确率的问题 谢谢大家啦

我搞了一个石碑碑刻的文字识别系统,但是识别出来的文字准确率很低如图一,
 分享
分享
 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
根据您提供的代码和识别结果,我看到了几个可以改进的地方来提高石碑碑刻文字的识别准确率。
您的预处理方法已经很不错,但还可以进一步优化:
def preprocess_image(self, image):
# 转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用更强的CLAHE增强对比度
clahe = cv2.createCLAHE(clipLimit=4.0, tileGridSize=(16,16))
enhanced = clahe.apply(gray)
# 非局部均值去噪
denoised = cv2.fastNlMeansDenoising(enhanced, h=30, templateWindowSize=7, searchWindowSize=21)
# 锐化处理
kernel = np.array([[-1,-1,-1], [-1,9,-1], [-1,-1,-1]])
sharpened = cv2.filter2D(denoised, -1, kernel)
# 结合全局和局部二值化
_, binary1 = cv2.threshold(sharpened, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
binary2 = cv2.adaptiveThreshold(sharpened, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 31, 5)
# 结合两种二值化结果
binary = cv2.bitwise_and(binary1, binary2)
# 形态学操作
kernel = np.ones((3,3), np.uint8)
binary = cv2.morphologyEx(binary, cv2.MORPH_CLOSE, kernel)
return cv2.cvtColor(binary, cv2.COLOR_GRAY2BGR)
建议结合多个OCR引擎的结果来提高准确率:
def ocr_fusion(self, image):
# PaddleOCR结果
paddle_result = self.ocr.ocr(image, cls=True)
# EasyOCR结果
easy_result = self.easyocr.readtext(image)
# 结果融合逻辑
final_result = []
# 这里可以添加更复杂的结果融合算法
# 例如投票机制、置信度加权等
return final_result
石碑文字通常有这些特点,需要特别处理:
def stone_specific_enhance(self, image):
# 增强浅色文字
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
# 增强亮度通道
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
l = clahe.apply(l)
# 合并通道
enhanced_lab = cv2.merge((l, a, b))
enhanced = cv2.cvtColor(enhanced_lab, cv2.COLOR_LAB2BGR)
# 边缘增强
edges = cv2.Canny(enhanced, 50, 150)
edges = cv2.cvtColor(edges, cv2.COLOR_GRAY2BGR)
# 结合原图和边缘
result = cv2.addWeighted(enhanced, 0.7, edges, 0.3, 0)
return result
添加后处理步骤来提高识别结果质量:
def postprocess_results(self, results):
# 去除低置信度结果
filtered = [r for r in results if r[1][1] > 0.6] # 置信度阈值
# 文字校正
corrected = []
for text, confidence in filtered:
# 这里可以添加基于规则的校正
# 例如常见石碑文字替换
corrected_text = text.replace('三', '王') if confidence < 0.7 else text
corrected.append((corrected_text, confidence))
return corrected
建议的完整识别流程:
希望这些建议能帮助您提高识别准确率!如果需要更具体的实现细节,可以提供更多关于您的数据和具体问题的信息。
分享 创建了问题
5月8日
创建了问题
5月8日


