阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
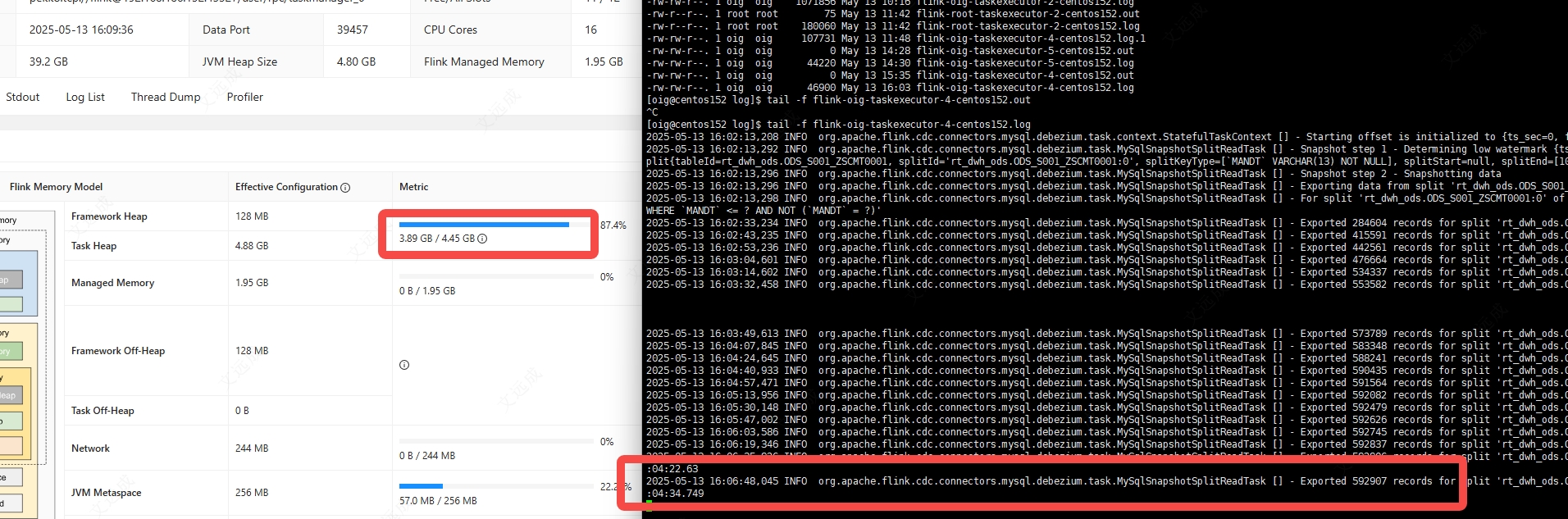
FlinkCDC exported 数据库日志记录内存不释放
你遇到的问题是 FlinkCDC 在 Exported 数据库日志记录时,内存不释放,导致内存占用增加。
可能的原因是 FlinkCDC 在 Exported 数据库日志记录时,使用了大量的内存来存储数据,而没有及时地释放内存。
解决方案:
- 优化 FlinkCDC 的配置,例如:
flink.cdc.max-queue-size: 100000
flink.cdc.max-queue-size-per-fragment: 10000
这两个配置可以控制 FlinkCDC 的队列大小和每个 fragment 的队列大小,从而减少内存占用。
- 使用 FlinkCDC 的
async-commit 机制,例如:
flink.cdc.async-commit.enabled: true
flink.cdc.async-commit.queue-size: 10000
这两个配置可以使 FlinkCDC 在 Exported 数据库日志记录时,使用异步提交机制,从而减少内存占用。
- 使用 FlinkCDC 的
batch-commit 机制,例如:
flink.cdc.batch-commit.enabled: true
flink.cdc.batch-commit.queue-size: 10000
这两个配置可以使 FlinkCDC 在 Exported 数据库日志记录时,使用批量提交机制,从而减少内存占用。
- 优化 FlinkCDC 的数据处理逻辑,例如:
FlinkCDC cdc = FlinkCDC.create()
.setSource("your-source")
.setSink("your-sink")
.setBatchSize(10000)
.setBatchInterval(1000)
.start();
这段代码可以控制 FlinkCDC 的批量处理大小和批量处理间隔,从而减少内存占用。
- monitor FlinkCDC 的内存占用情况,使用 Flink 的监控工具,例如:
flink monitor -n <your-job-name> -m memory
这条命令可以监控 FlinkCDC 的内存占用情况,从而快速发现内存占用增加的原因。
需要注意的是,这些解决方案可能需要根据你的实际情况进行调整和组合。