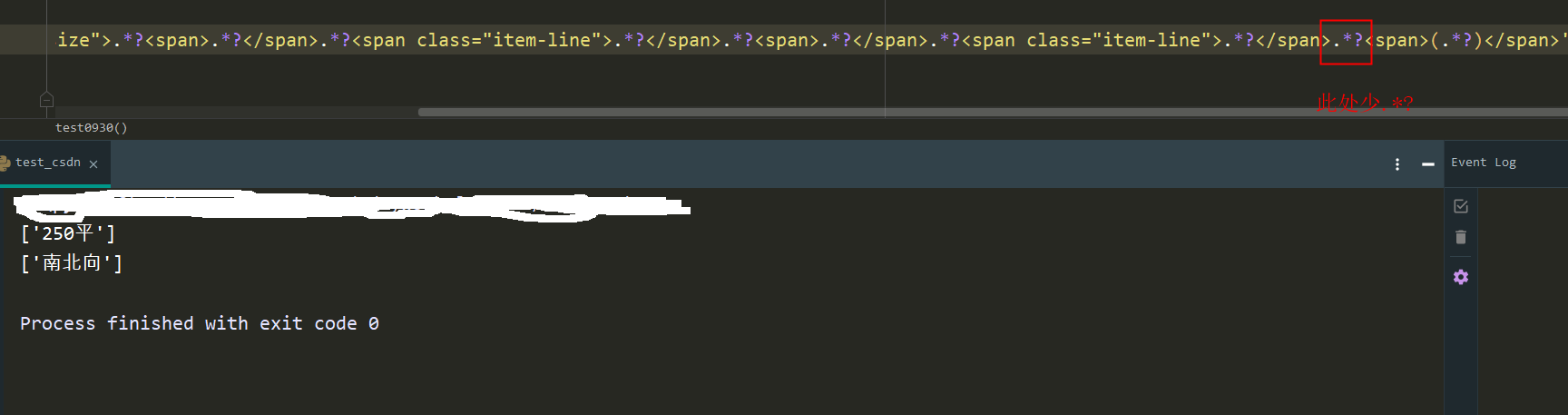
我在利用python正则表达式爬取网页内文本时(如下图所示)遇到了一些问题:
比如爬取250平方米吧,实现代码如下:
area = re.findall(r'<dd class="dd-item size">.*?<span>.*?</span>.*?<span class="item-line">.*?</span>.*?<span>(.*?)</span>', resp, re.DOTALL)
但是如果想按照上面的思路继续追加正则表达式爬取“南北向”这个文本就爬取不出来了:
area = re.findall(r'<dd class="dd-item size">.*?<span>.*?</span>.*?<span class="item-line">.*?</span>.*?<span>.*?</span>.*?<span class="item-line">.*?</span><span>(.*?)</span>', resp, re.DOTALL)
请问问题出在哪里啊?