
不知道有人遇到过吗?想知道如何解决。
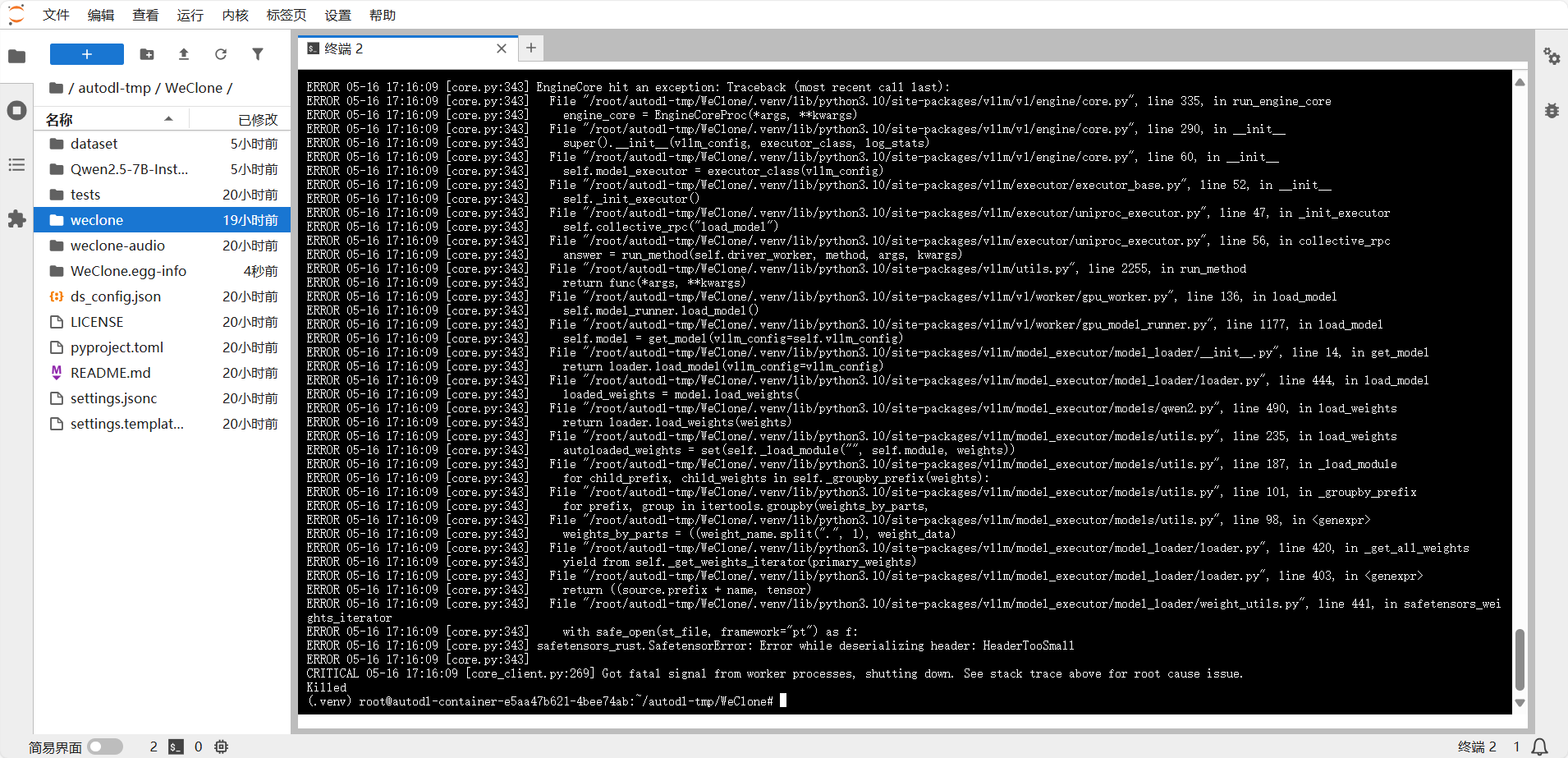
完整日志为
(.venv) root@autodl-container-e5aa47b621-4bee74ab:~/autodl-tmp/WeClone# weclone-cli make-dataset
INFO 05-16 17:15:48 [__init__.py:239] Automatically detected platform cuda.
[WeClone] I | 17:15:50 | Loading configuration from: ./settings.jsonc
[WeClone] I | 17:15:50 | 聊天记录禁用词: ['例如 密码', '例如 姓名', '//.....']
[WeClone] I | 17:15:50 | 开始使用llm对数据打分
[INFO|configuration_utils.py:697] 2025-05-16 17:15:50,895 >> loading configuration file ./Qwen2.5-7B-Instruct/config.json
[INFO|configuration_utils.py:771] 2025-05-16 17:15:50,897 >> Model config Qwen2Config {
"_name_or_path": "./Qwen2.5-7B-Instruct",
"architectures": [
"Qwen2ForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"hidden_act": "silu",
"hidden_size": 3584,
"initializer_range": 0.02,
"intermediate_size": 18944,
"max_position_embeddings": 32768,
"max_window_layers": 28,
"model_type": "qwen2",
"num_attention_heads": 28,
"num_hidden_layers": 28,
"num_key_value_heads": 4,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000.0,
"sliding_window": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.49.0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 152064
}
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:50,935 >> loading file vocab.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:50,935 >> loading file merges.txt
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:50,935 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:50,935 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:50,935 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:50,935 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:50,935 >> loading file chat_template.jinja
[INFO|tokenization_utils_base.py:2313] 2025-05-16 17:15:51,266 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|configuration_utils.py:697] 2025-05-16 17:15:51,267 >> loading configuration file ./Qwen2.5-7B-Instruct/config.json
[INFO|configuration_utils.py:771] 2025-05-16 17:15:51,269 >> Model config Qwen2Config {
"_name_or_path": "./Qwen2.5-7B-Instruct",
"architectures": [
"Qwen2ForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"hidden_act": "silu",
"hidden_size": 3584,
"initializer_range": 0.02,
"intermediate_size": 18944,
"max_position_embeddings": 32768,
"max_window_layers": 28,
"model_type": "qwen2",
"num_attention_heads": 28,
"num_hidden_layers": 28,
"num_key_value_heads": 4,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000.0,
"sliding_window": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.49.0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 152064
}
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:51,270 >> loading file vocab.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:51,270 >> loading file merges.txt
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:51,270 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:51,270 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:51,270 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:51,270 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:15:51,270 >> loading file chat_template.jinja
[INFO|tokenization_utils_base.py:2313] 2025-05-16 17:15:51,584 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|2025-05-16 17:15:51] llamafactory.data.template:157 >> Add <|im_end|> to stop words.
[INFO|configuration_utils.py:697] 2025-05-16 17:15:51,618 >> loading configuration file ./Qwen2.5-7B-Instruct/config.json
[INFO|configuration_utils.py:697] 2025-05-16 17:15:51,618 >> loading configuration file ./Qwen2.5-7B-Instruct/config.json
[INFO|configuration_utils.py:771] 2025-05-16 17:15:51,619 >> Model config Qwen2Config {
"_name_or_path": "./Qwen2.5-7B-Instruct",
"architectures": [
"Qwen2ForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"hidden_act": "silu",
"hidden_size": 3584,
"initializer_range": 0.02,
"intermediate_size": 18944,
"max_position_embeddings": 32768,
"max_window_layers": 28,
"model_type": "qwen2",
"num_attention_heads": 28,
"num_hidden_layers": 28,
"num_key_value_heads": 4,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 1000000.0,
"sliding_window": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.49.0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 152064
}
[INFO|image_processing_auto.py:301] 2025-05-16 17:15:51,621 >> Could not locate the image processor configuration file, will try to use the model config instead.
INFO 05-16 17:15:59 [config.py:585] This model supports multiple tasks: {'generate', 'embed', 'score', 'reward', 'classify'}. Defaulting to 'generate'.
INFO 05-16 17:15:59 [config.py:1697] Chunked prefill is enabled with max_num_batched_tokens=8192.
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:16:00,833 >> loading file vocab.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:16:00,833 >> loading file merges.txt
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:16:00,833 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:16:00,833 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:16:00,833 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:16:00,833 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2048] 2025-05-16 17:16:00,833 >> loading file chat_template.jinja
[INFO|tokenization_utils_base.py:2313] 2025-05-16 17:16:01,136 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|configuration_utils.py:1093] 2025-05-16 17:16:01,230 >> loading configuration file ./Qwen2.5-7B-Instruct/generation_config.json
[INFO|configuration_utils.py:1140] 2025-05-16 17:16:01,231 >> Generate config GenerationConfig {
"bos_token_id": 151643,
"do_sample": true,
"eos_token_id": [
151645,
151643
],
"pad_token_id": 151643,
"repetition_penalty": 1.05,
"temperature": 0.7,
"top_k": 20,
"top_p": 0.8
}
WARNING 05-16 17:16:01 [utils.py:2181] We must use the `spawn` multiprocessing start method. Overriding VLLM_WORKER_MULTIPROC_METHOD to 'spawn'. See https://docs.vllm.ai/en/latest/getting_started/troubleshooting.html#python-multiprocessing for more information. Reason: CUDA is initialized
INFO 05-16 17:16:05 [__init__.py:239] Automatically detected platform cuda.
INFO 05-16 17:16:07 [core.py:54] Initializing a V1 LLM engine (v0.8.2) with config: model='./Qwen2.5-7B-Instruct', speculative_config=None, tokenizer='./Qwen2.5-7B-Instruct', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.bfloat16, max_seq_len=3072, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=./Qwen2.5-7B-Instruct, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"level":3,"custom_ops":["none"],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"use_inductor":true,"compile_sizes":[],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":512}
WARNING 05-16 17:16:08 [utils.py:2321] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7f54bb068c10>
INFO 05-16 17:16:09 [parallel_state.py:954] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 05-16 17:16:09 [cuda.py:220] Using Flash Attention backend on V1 engine.
INFO 05-16 17:16:09 [gpu_model_runner.py:1174] Starting to load model ./Qwen2.5-7B-Instruct...
WARNING 05-16 17:16:09 [topk_topp_sampler.py:63] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
ERROR 05-16 17:16:09 [core.py:343] EngineCore hit an exception: Traceback (most recent call last):
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/v1/engine/core.py", line 335, in run_engine_core
ERROR 05-16 17:16:09 [core.py:343] engine_core = EngineCoreProc(*args, **kwargs)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/v1/engine/core.py", line 290, in __init__
ERROR 05-16 17:16:09 [core.py:343] super().__init__(vllm_config, executor_class, log_stats)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/v1/engine/core.py", line 60, in __init__
ERROR 05-16 17:16:09 [core.py:343] self.model_executor = executor_class(vllm_config)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/executor/executor_base.py", line 52, in __init__
ERROR 05-16 17:16:09 [core.py:343] self._init_executor()
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/executor/uniproc_executor.py", line 47, in _init_executor
ERROR 05-16 17:16:09 [core.py:343] self.collective_rpc("load_model")
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/executor/uniproc_executor.py", line 56, in collective_rpc
ERROR 05-16 17:16:09 [core.py:343] answer = run_method(self.driver_worker, method, args, kwargs)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/utils.py", line 2255, in run_method
ERROR 05-16 17:16:09 [core.py:343] return func(*args, **kwargs)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/v1/worker/gpu_worker.py", line 136, in load_model
ERROR 05-16 17:16:09 [core.py:343] self.model_runner.load_model()
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/v1/worker/gpu_model_runner.py", line 1177, in load_model
ERROR 05-16 17:16:09 [core.py:343] self.model = get_model(vllm_config=self.vllm_config)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/model_loader/__init__.py", line 14, in get_model
ERROR 05-16 17:16:09 [core.py:343] return loader.load_model(vllm_config=vllm_config)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/model_loader/loader.py", line 444, in load_model
ERROR 05-16 17:16:09 [core.py:343] loaded_weights = model.load_weights(
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/models/qwen2.py", line 490, in load_weights
ERROR 05-16 17:16:09 [core.py:343] return loader.load_weights(weights)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/models/utils.py", line 235, in load_weights
ERROR 05-16 17:16:09 [core.py:343] autoloaded_weights = set(self._load_module("", self.module, weights))
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/models/utils.py", line 187, in _load_module
ERROR 05-16 17:16:09 [core.py:343] for child_prefix, child_weights in self._groupby_prefix(weights):
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/models/utils.py", line 101, in _groupby_prefix
ERROR 05-16 17:16:09 [core.py:343] for prefix, group in itertools.groupby(weights_by_parts,
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/models/utils.py", line 98, in <genexpr>
ERROR 05-16 17:16:09 [core.py:343] weights_by_parts = ((weight_name.split(".", 1), weight_data)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/model_loader/loader.py", line 420, in _get_all_weights
ERROR 05-16 17:16:09 [core.py:343] yield from self._get_weights_iterator(primary_weights)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/model_loader/loader.py", line 403, in <genexpr>
ERROR 05-16 17:16:09 [core.py:343] return ((source.prefix + name, tensor)
ERROR 05-16 17:16:09 [core.py:343] File "/root/autodl-tmp/WeClone/.venv/lib/python3.10/site-packages/vllm/model_executor/model_loader/weight_utils.py", line 441, in safetensors_weights_iterator
ERROR 05-16 17:16:09 [core.py:343] with safe_open(st_file, framework="pt") as f:
ERROR 05-16 17:16:09 [core.py:343] safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooSmall
ERROR 05-16 17:16:09 [core.py:343]
CRITICAL 05-16 17:16:09 [core_client.py:269] Got fatal signal from worker processes, shutting down. See stack trace above for root cause issue.
Killed






