python使用pyspark运行报错
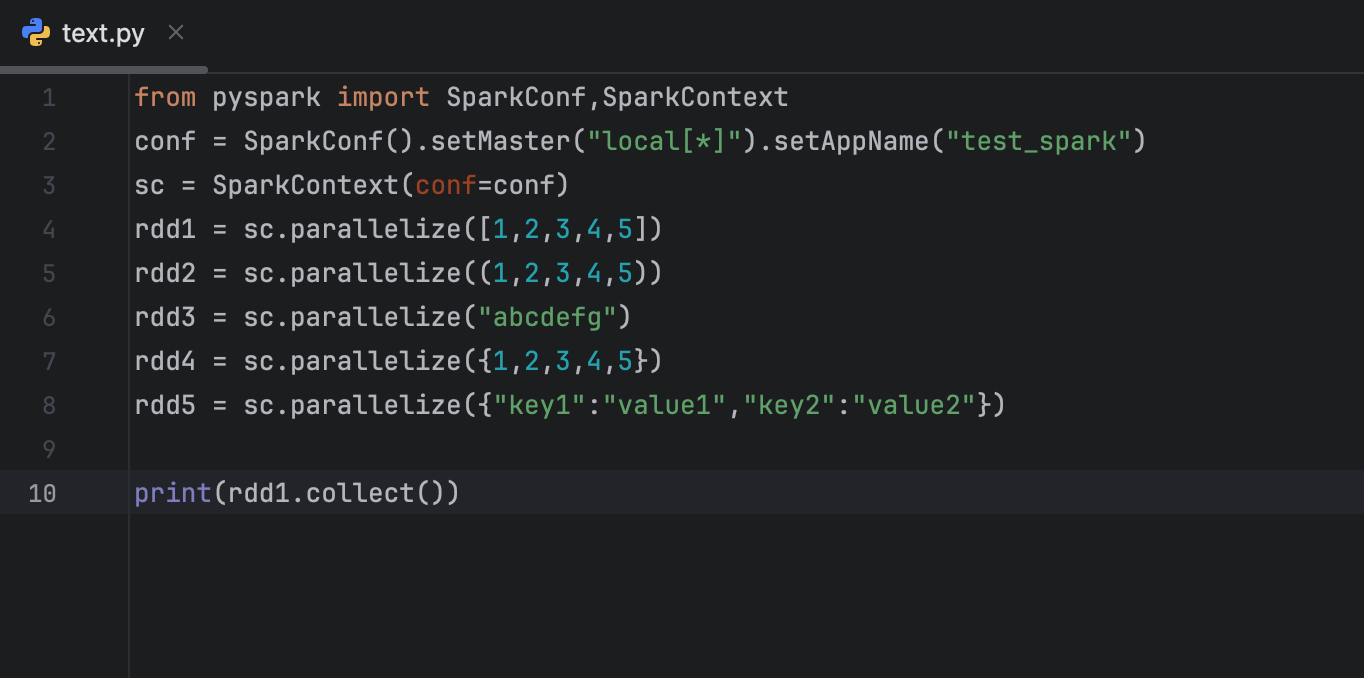
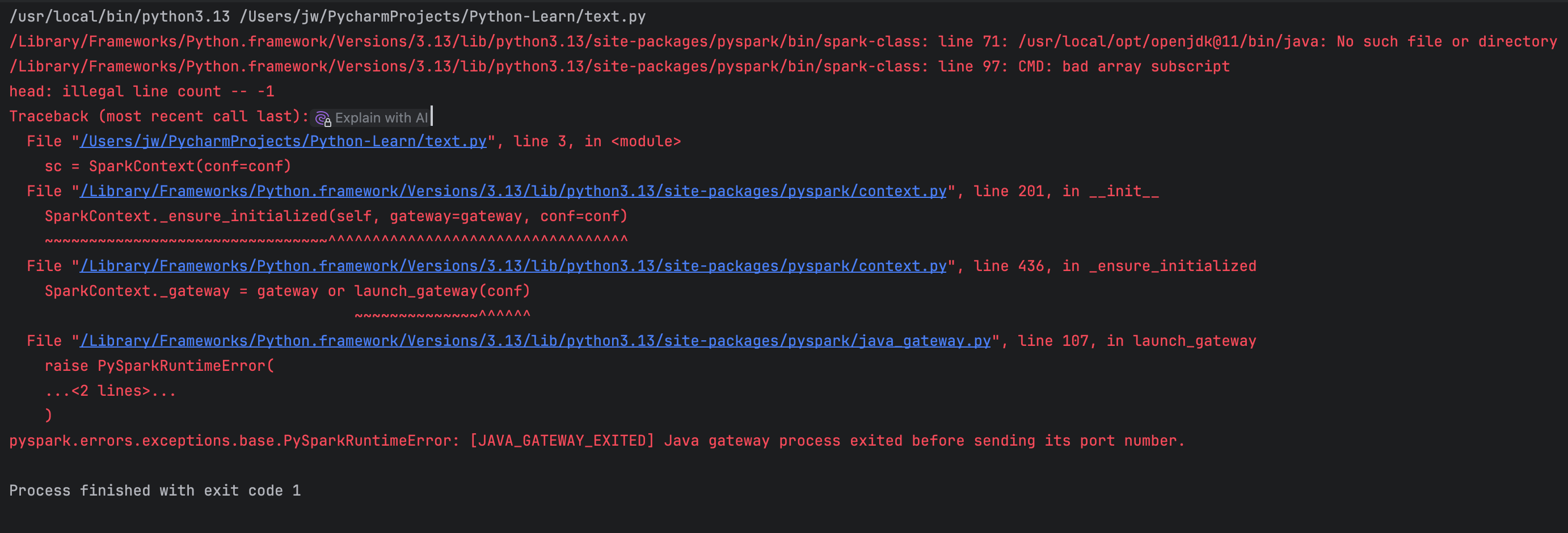
报错如上图,已经安装了java8,之前连包都导不进去,现在能导pyspark,但就是报错很多,网上搜索还解决不了,请帮忙解决下,谢谢

python使用pyspark运行报错
 分享
分享
上午好☀️☀️☀️️
本答案参考通义千问
根据你的描述,Python 使用 PySpark 运行时出现了错误,虽然能够导入 PySpark 模块,但仍然存在一些问题。为了帮助你解决问题,我们需要进一步分析报错信息。以下是解决问题的步骤和可能的原因:
确保你的环境变量和依赖项正确配置。
PySpark 需要 Java 环境支持。你需要确保以下几点:
JAVA_HOME 环境变量,指向 Java 的安装路径。检查方法:
# 查看 Java 版本
java -version
# 查看 JAVA_HOME 是否设置正确
echo $JAVA_HOME
如果 JAVA_HOME 没有设置,可以临时设置:
export JAVA_HOME=/path/to/java
export PATH=$JAVA_HOME/bin:$PATH
确保 Spark 和 PySpark 已正确安装,并且版本兼容。
检查方法:
pip show pyspark
如果你是通过源码安装的 Spark,确保 SPARK_HOME 环境变量已设置:
export SPARK_HOME=/path/to/spark
export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
export PYSPARK_PYTHON=python
请提供完整的报错信息(截图或文字),这样我们可以更准确地定位问题。常见的报错包括:
确保 PySpark 能够正常导入:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
print(spark.version)
如果导入失败,可能是以下原因:
pyspark 包未正确安装。PYTHONPATH 配置错误。修复方法:
pip install pyspark
如果你使用的是集群模式,需要检查 spark-defaults.conf 文件中的配置是否正确。
Spark 的日志文件通常位于 $SPARK_HOME/logs 目录下,查看日志文件可以帮助定位问题。
PySpark 可能依赖一些额外的库,例如 py4j。可以通过以下命令安装:
pip install py4j
PySpark 支持的 Python 版本为 3.6+。确保你的 Python 版本符合要求。
以下是一个简单的 PySpark 示例代码,用于测试环境是否正常工作:
from pyspark.sql import SparkSession
# 创建 SparkSession
spark = SparkSession.builder \
.appName("Test") \
.master("local[*]") \
.getOrCreate()
# 创建一个简单的 DataFrame
data = [(1, "Alice"), (2, "Bob")]
columns = ["id", "name"]
df = spark.createDataFrame(data, columns)
# 打印 DataFrame
df.show()
# 停止 SparkSession
spark.stop()
| 问题描述 | 解决方案 |
|----------|----------|
| java.lang.NoSuchMethodError | 检查 Java 版本是否兼容,推荐使用 Java 8。 |
| ModuleNotFoundError: No module named 'pyspark' | 确保 pyspark 包已正确安装,执行 pip install pyspark。 |
| ImportError: cannot import name 'SparkContext' | 检查 PySpark 版本是否与 Spark 版本兼容。 |
| java.io.IOException | 检查 Hadoop 相关依赖是否安装,执行 pip install pyarrow。 |
请提供具体的报错信息,以便我们更精确地帮助你解决问题。按照上述步骤逐一排查,通常可以解决大部分问题。如果仍有疑问,请补充更多细节,我们会继续协助!
分享 创建了问题
5月19日
创建了问题
5月19日

