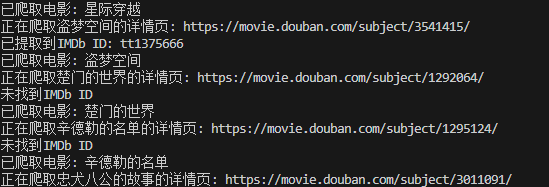
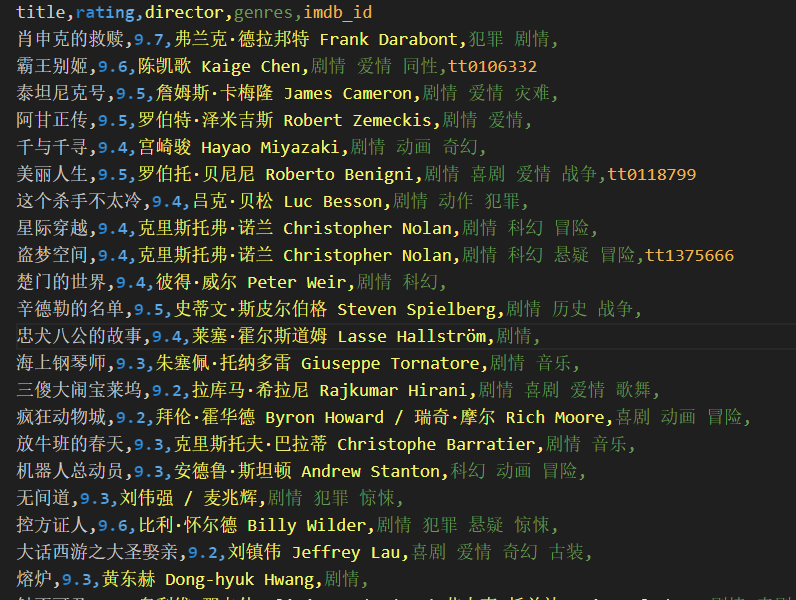
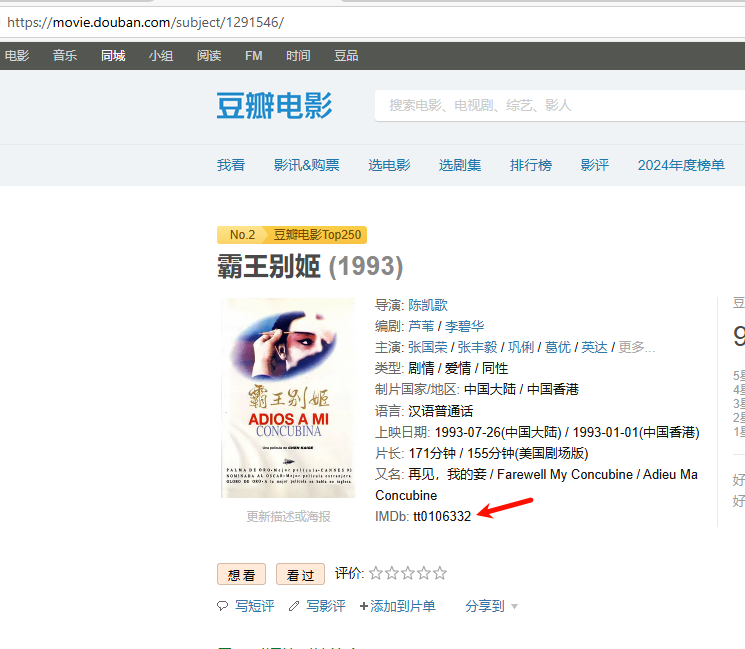
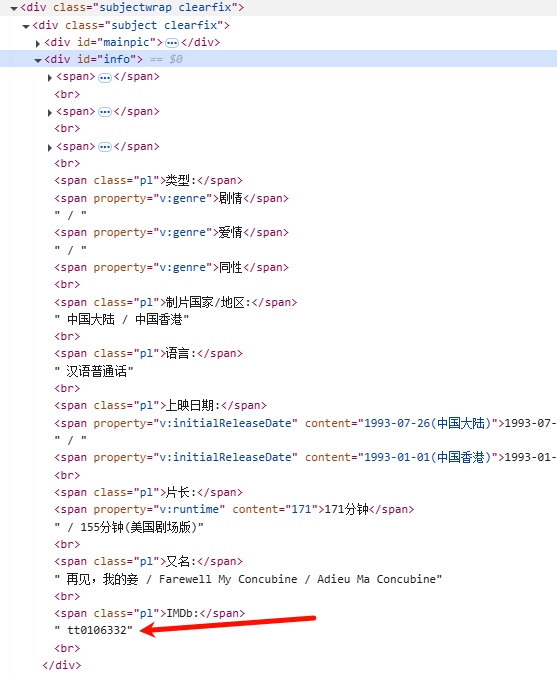
我想爬取豆瓣电影的imdb_id,但是它是有概率爬取不到的,无论是用css定位,xpath定位还是用正则匹配,都有很大的概率获取不到
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
import re
import os
from fake_useragent import UserAgent
class DoubanMovieScraper:
def __init__(self):
# 创建User-Agent生成器
try:
self.ua = UserAgent()
except:
# 如果无法使用fake_useragent库,使用预定义的User-Agent列表
self.user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36 Edg/91.0.864.71'
]
# 创建存放数据目录
self.data_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'data')
if not os.path.exists(self.data_dir):
os.makedirs(self.data_dir)
# 创建会话,维持Cookie
self.session = requests.Session()
def get_random_ua(self):
"""获取随机User-Agent"""
try:
return self.ua.random
except:
return random.choice(self.user_agents)
def get_headers(self, referer=None):
"""生成请求头"""
headers = {
'User-Agent': self.get_random_ua(),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
if referer:
headers['Referer'] = referer
return headers
def make_request(self, url, referer=None, max_retries=3):
"""发送请求,包含重试和错误处理"""
headers = self.get_headers(referer)
for attempt in range(max_retries):
try:
response = self.session.get(
url,
headers=headers,
timeout=15,
)
# 检查响应状态
if response.status_code == 200:
return response
elif response.status_code == 403 or response.status_code == 429:
print(f"请求被拒绝(状态码:{response.status_code}),可能是被反爬措施拦截,等待更长时间...")
# 遇到拒绝访问,等待更长时间
time.sleep(random.uniform(20, 30))
else:
print(f"请求失败,状态码: {response.status_code},尝试重试...")
# 如果不是最后一次尝试,等待一段时间再重试
if attempt < max_retries - 1:
time.sleep(random.uniform(5, 10))
except Exception as e:
print(f"请求发生异常: {str(e)}")
if attempt < max_retries - 1:
time.sleep(random.uniform(5, 10))
return None
def get_top250_movies(self):
movies = []
base_url = 'https://movie.douban.com/top250'
for start in range(0, 25, 25):
url = f'{base_url}?start={start}'
print(f"正在爬取: {url}")
try:
# 获取列表页
response = self.make_request(url, referer='https://movie.douban.com/')
if not response:
print(f"无法获取页面: {url},跳过该页")
continue
soup = BeautifulSoup(response.text, 'html.parser')
movie_items = soup.select('.grid_view li')
if not movie_items:
print(f"页面未找到电影列表,可能被反爬措施拦截。页面内容: {response.text[:200]}...")
continue
for item in movie_items:
try:
# 电影名称
title = item.select_one('.title').text
# 评分
rating = item.select_one('.rating_num').text
# 导演和类型信息
info = item.select_one('.bd p').text.strip()
# 提取导演信息
director = ""
if "导演:" in info:
director_match = re.search(r'导演:(.*?)主演:', info, re.DOTALL)
if director_match:
director = director_match.group(1).strip()
else:
# 如果没有主演信息,可能格式不同
director_match = re.search(r'导演:(.*?)(\d{4}|\s{2,})', info, re.DOTALL)
if director_match:
director = director_match.group(1).strip()
# 提取类型信息(年份/国家/类型)
genres = ""
type_match = re.search(r'\d{4}\s*/\s*([^/]*)/\s*(.*?)(?:\s{2,}|$)', info)
if type_match:
genres = type_match.group(2).strip()
# 获取IMDB ID
movie_url = item.select_one('.hd a')['href']
print(f"正在爬取{title}的详情页: {movie_url}")
# 尝试获取IMDb ID
# 在访问详情页之前额外等待,避免频繁请求
time.sleep(random.uniform(3, 5))
movie_response = self.make_request(movie_url,referer=url)
if movie_response and movie_response.status_code == 200:
# 使用正则表达式直接从HTML文本中提取IMDb ID
imdb_id = ""
imdb_pattern = r'IMDb:</span>\s*<a.*?>(tt\d+)</a>'
imdb_match = re.search(imdb_pattern, movie_response.text)
if imdb_match:
imdb_id = imdb_match.group(1)
print(f"已提取到IMDb ID: {imdb_id}")
else:
# 尝试另一种格式匹配
imdb_pattern2 = r'IMDb:</span>\s*(tt\d+)'
imdb_match2 = re.search(imdb_pattern2, movie_response.text)
if imdb_match2:
imdb_id = imdb_match2.group(1)
print(f"已提取到IMDb ID: {imdb_id}")
else:
print("未找到IMDb ID")
else:
print(f"获取电影详情页失败: {movie_url}")
movie_info = {
'title': title,
'rating': float(rating),
'director': director,
'genres': genres,
'imdb_id': imdb_id,
}
movies.append(movie_info)
print(f"已爬取电影: {title}")
except Exception as e:
print(f"处理电影项时出错: {str(e)}")
# 请求间隔,避免频繁请求,增加间隔时间
time.sleep(random.uniform(8, 15))
except Exception as e:
print(f"爬取列表页出错: {str(e)}")
# 保存为CSV
df = pd.DataFrame(movies)
csv_path = os.path.join(self.data_dir, 'douban_top250.csv')
df.to_csv(csv_path, index=False, encoding='utf-8-sig')
print(f"数据已保存至: {csv_path}")
return df
if __name__ == "__main__":
scraper = DoubanMovieScraper()
scraper.get_top250_movies()