怎么将以下代码改对啊
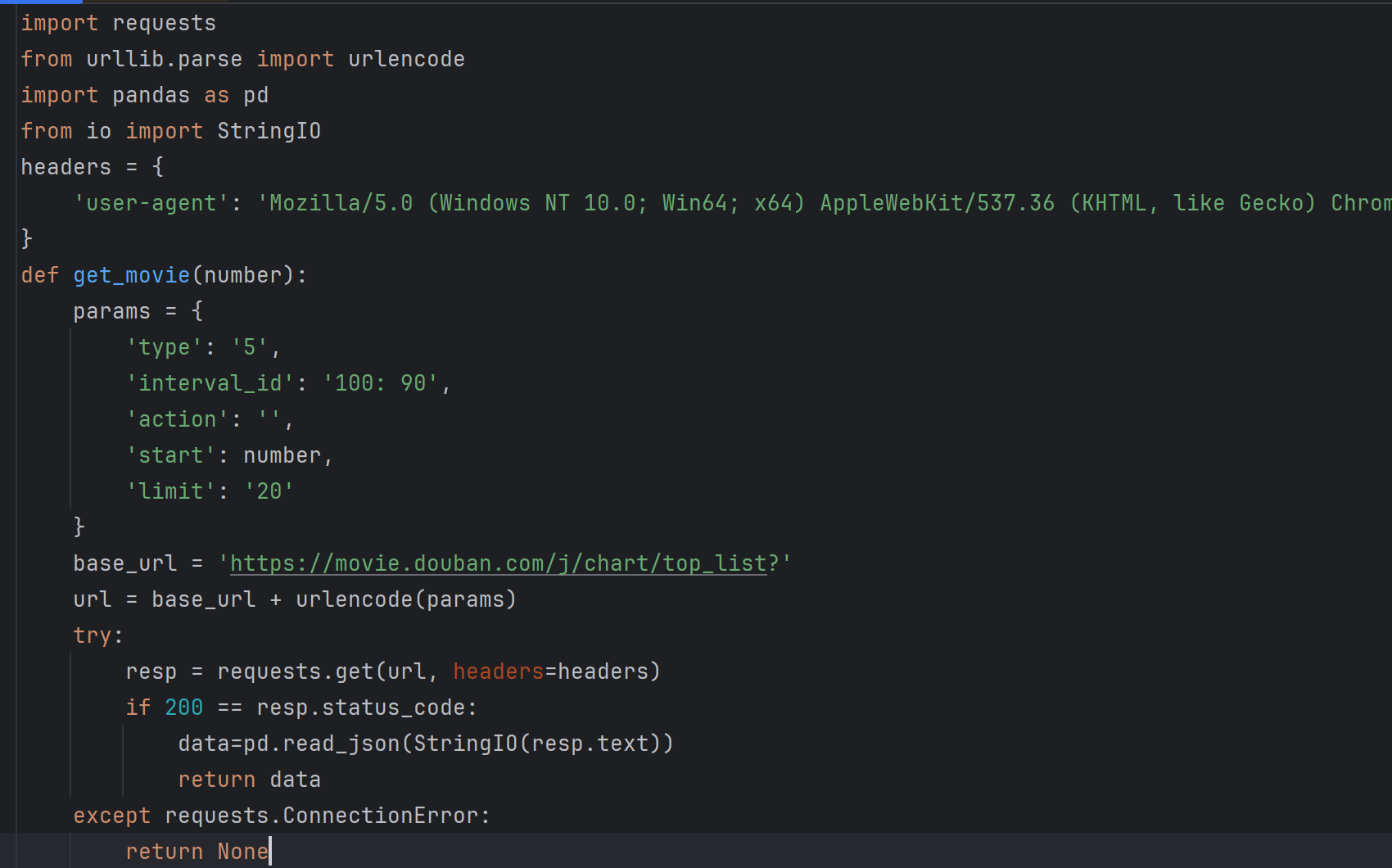
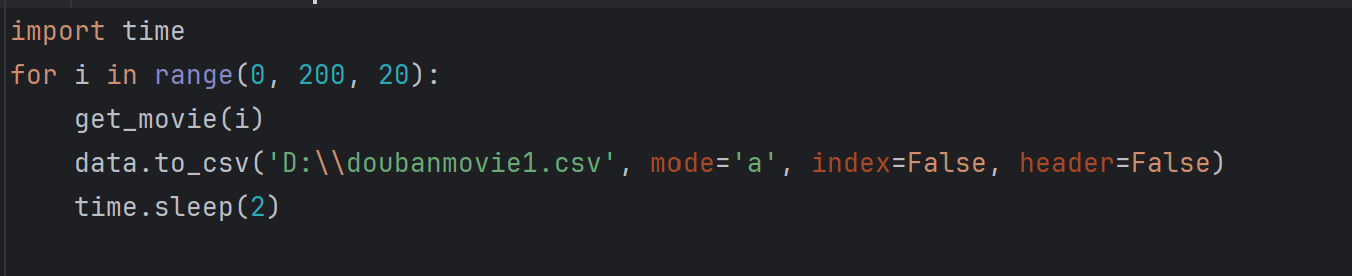
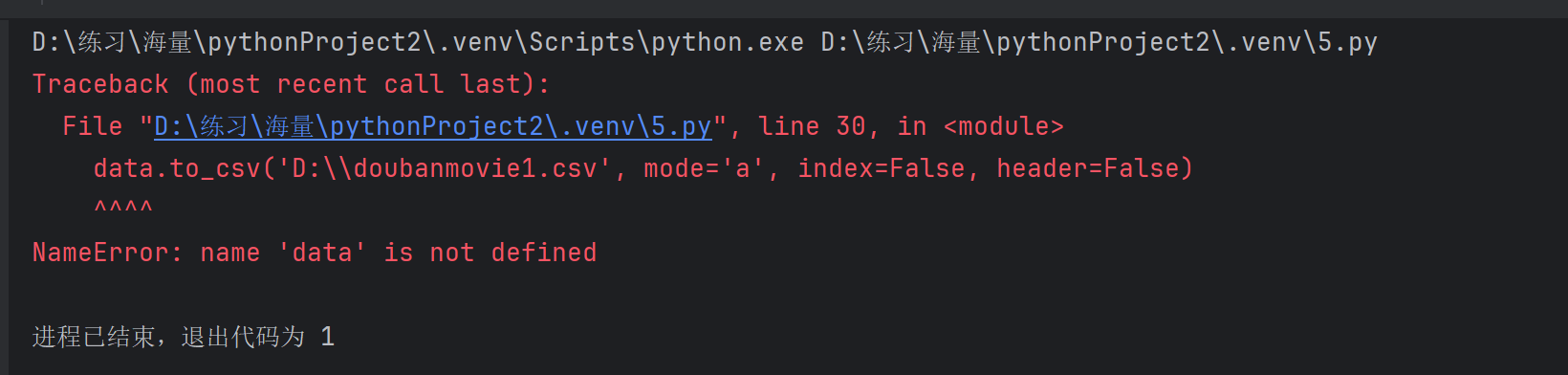
爬取豆瓣电影“动作”片排行榜的前200个电影信息,并将其保存在本地csv文件里

怎么将以下代码改对啊
 分享
分享
中午好🌞🌞🌞
本答案参考通义千问
以下是针对你的问题提供的解决方案,假设你已经有了一个基本的豆瓣电影爬虫代码,但存在一些问题需要修复。我们将通过以下几个步骤来完成目标:
首先,我们需要明确当前代码可能存在的问题:
以下是经过优化和修复后的代码示例:
import requests
from bs4 import BeautifulSoup
import csv
# 定义函数:获取指定页面的电影信息
def get_movie_info(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
movies = []
movie_list = soup.find_all('div', class_='item') # 动作片排行榜的电影结构
for item in movie_list:
title = item.find('span', class_='title').text.strip() # 获取电影标题
rating = item.find('span', class_='rating_num').text.strip() # 获取评分
info = item.find('div', class_='info').text.strip() # 获取其他信息
movies.append({
'title': title,
'rating': rating,
'info': info
})
return movies
# 定义函数:保存电影信息到CSV文件
def save_to_csv(movies, filename):
keys = ['title', 'rating', 'info']
with open(filename, mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=keys)
writer.writeheader()
writer.writerows(movies)
# 主函数:爬取前200部电影信息并保存到CSV
def main():
base_url = "https://movie.douban.com/tag/%E5%8A%A8%E4%BD%9C?start={}&type=T" # 动作片排行榜URL模板
all_movies = []
for start in range(0, 200, 20): # 每页20部电影,共10页
url = base_url.format(start)
print(f"正在爬取 {url}")
movies = get_movie_info(url)
all_movies.extend(movies)
# 保存所有电影信息到CSV文件
save_to_csv(all_movies, 'douban_action_movies.csv')
print("电影信息已成功保存到 douban_action_movies.csv 文件中!")
if __name__ == "__main__":
main()
请求头设置
User-Agent 模拟浏览器访问,避免被豆瓣反爬机制拦截。解析HTML结构
find 和 find_all 的参数)。分页处理
保存为CSV
csv.DictWriter 将电影信息写入CSV文件,方便后续分析。反爬机制
豆瓣可能有IP封禁或验证码机制,建议使用代理池或降低请求频率。
合法性
爬取数据时需遵守豆瓣的robots.txt协议,不得用于商业用途。
调试与验证
如果发现某些字段无法正确提取,可以打印 response.text 或 soup.prettify() 来检查HTML结构。
运行后会生成一个名为 douban_action_movies.csv 的文件,内容类似如下:
| title | rating | info | |---------------------|--------|-----------------------------------| | 无间道 | 9.2 | 导演: 刘伟强 / 麦兆辉 | | 功夫 | 8.7 | 导演: 周星驰 | | 终结者2:审判日 | 8.9 | 导演: 詹姆斯·卡梅隆 |
如果你还有其他问题,欢迎进一步补充说明!
分享 创建了问题
5月24日
创建了问题
5月24日


