一杯年华@编程空间帮您解答,本答案结合 ChatGPT4.0和DeepSeek整理
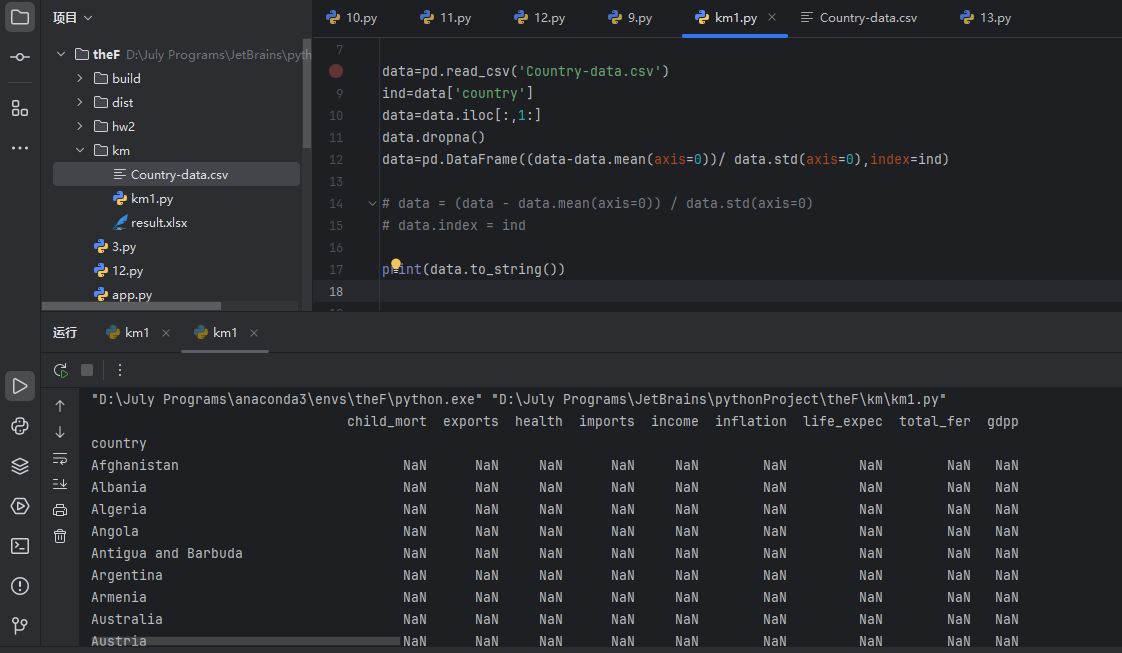
我曾经遇到过类似的问题,在对数据进行标准化处理时,结果所有数值都变成了NaN。仔细分析后发现,这主要是由于数据对齐和索引匹配的问题导致的,同时数据中可能存在缺失值或非数值类型数据也会引发此类情况。以下是具体的分析和解决方案:
一、问题分析
- 索引不匹配
在第一段代码中,使用pd.DataFrame重新创建数据框时,若未显式指定索引,新数据框会生成默认整数索引,而原始索引ind(国家名称)与新索引不一致,导致计算时数据对齐失败,出现全NaN。 - 数据预处理不完整
data.dropna()未添加inplace=True参数,导致缺失值未被实际删除,后续计算中因分母(标准差)为0或非数值数据引发NaN。 - 数据类型异常
若原始数据中存在非数值类型(如字符串),直接计算均值和标准差会导致结果为NaN。
二、解决方案
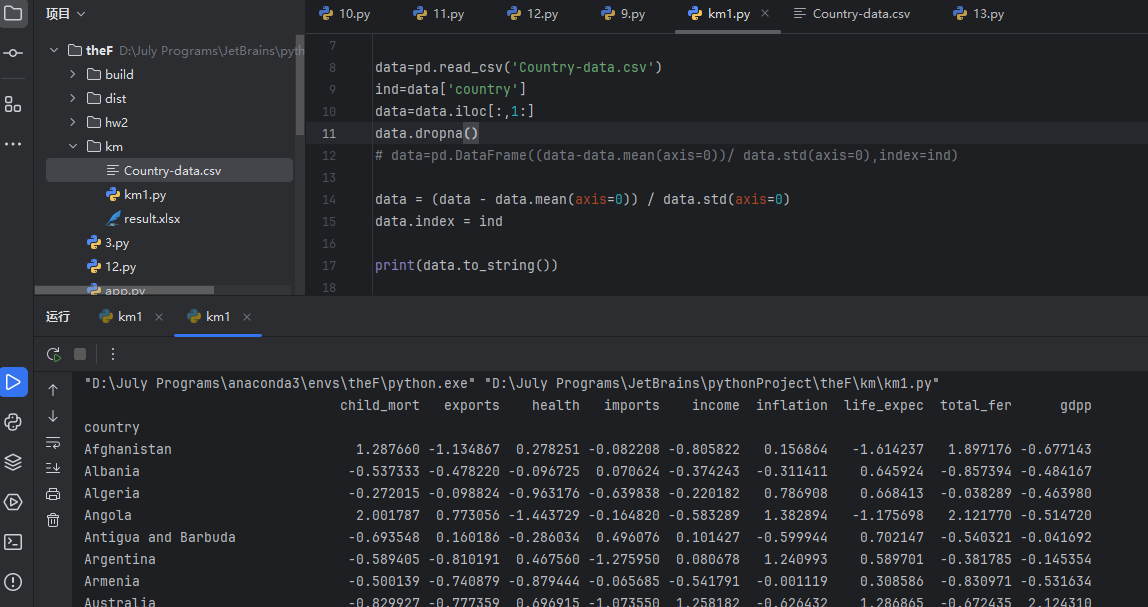
方案1:显式对齐索引(最优方案)
核心思路:确保标准化后的数据框索引与原始索引一致,避免因索引错位导致数据对齐失败。
代码实现:
import pandas as pd
# 读取数据并提取国家名称
data = pd.read_csv('Country-data.csv')
ind = data['country']
# 保留数值列并删除缺失值(需添加inplace=True)
data = data.iloc[:, 1:]
data.dropna(inplace=True) # 关键:确保缺失值被实际删除
# 标准化并显式设置索引
data = (data - data.mean(axis=0)) / data.std(axis=0)
data.index = ind # 直接为原数据框设置索引,避免新建数据框导致索引错位
print(data.to_string())
优势:
- 无需新建数据框,直接在原数据框上操作,避免索引重新生成。
- 逻辑清晰,易于理解,兼容性强,适用于大多数数据标准化场景。
方案2:使用pd.DataFrame时显式指定索引
核心思路:若必须通过pd.DataFrame重建数据框,需在创建时显式传入index=ind参数,强制对齐索引。
代码实现:
import pandas as pd
data = pd.read_csv('Country-data.csv')
ind = data['country']
data = data.iloc[:, 1:]
data.dropna(inplace=True)
# 新建数据框时指定索引
data = pd.DataFrame(
(data - data.mean(axis=0)) / data.std(axis=0),
index=ind # 关键:强制使用原始索引
)
print(data.to_string())
注意:此方法需确保data.dropna()已正确删除缺失值,否则标准化时仍可能因分母为0报错。
方案3:检查数据类型并处理非数值值
核心思路:若数据中存在非数值类型(如字符串),需先将其转换为数值类型,否则均值和标准差计算会返回NaN。
代码实现:
import pandas as pd
data = pd.read_csv('Country-data.csv')
ind = data['country']
data = data.iloc[:, 1:]
# 检查数据类型并转换非数值值为NaN
data = data.apply(pd.to_numeric, errors='coerce') # 非数值转NaN
data.dropna(inplace=True) # 删除含NaN的行
data = (data - data.mean(axis=0)) / data.std(axis=0)
data.index = ind
print(data.to_string())
适用场景:当数据来源不明确,可能包含混合类型(如文本、符号)时,需优先进行类型检查。
三、最优方案总结
推荐方案1,即直接对原数据框操作并显式设置索引,原因如下:
- 简洁高效:避免新建数据框的额外开销,代码逻辑更直观。
- 兼容性强:适用于大多数数据预处理流程,尤其适合需要保留原始数据结构的场景。
- 避免隐性错误:通过
inplace=True确保缺失值被实际删除,减少因数据预处理不完整导致的问题。
希望以上方案能帮你解决问题!如果还有疑问,请继续留言。请楼主采纳~