
为什么最后的输出并没有输出我理想的班级学科平均分呢?请求指导!
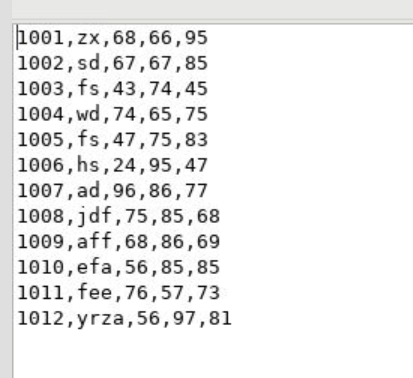
这里是原始数据
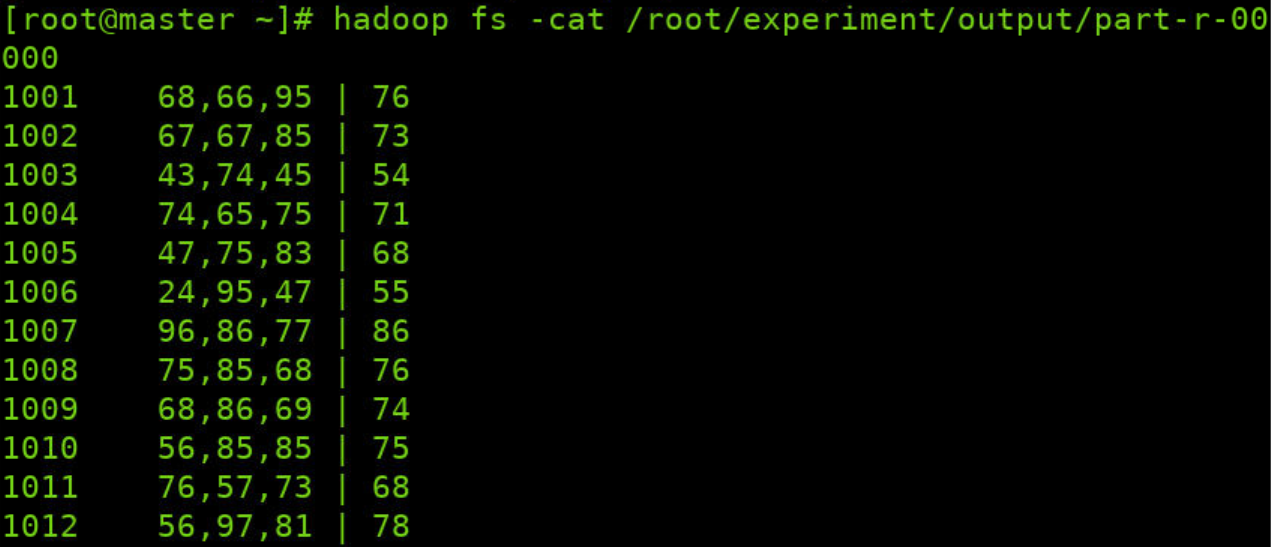
这里是输出结果
package experiment.big101;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.Arrays;
public class SMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] str = line.split(",");
int studentID = Integer.valueOf(str[0]); //学号
String[] score = Arrays.copyOfRange(str, 2, 5); //数学、英语、语文成绩
String scorestr = String.join(",",score);
context.write(new Text(String.valueOf(studentID)), new Text(String.valueOf(scorestr)));
}
}
package experiment.big101;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int subject1Total = 0;
int subject2Total = 0;
int subject3Total = 0;
int studentCount = 0;
StringBuilder studentAverages = new StringBuilder();
for (Text value : values) {
String[] scores = value.toString().split(",");
int s1 = Integer.parseInt(scores[0].trim());
int s2 = Integer.parseInt(scores[1].trim());
int s3 = Integer.parseInt(scores[2].trim());
int studentAvg = (s1 + s2 + s3) / 3;
if (studentAverages.length() > 0) {
studentAverages.append(",");
}
studentAverages.append(studentAvg);
subject1Total += s1;
subject2Total += s2;
subject3Total += s3;
studentCount++;
}
int classAvg1 = subject1Total / studentCount;
int classAvg2 = subject2Total / studentCount;
int classAvg3 = subject3Total / studentCount;
String classAverages = classAvg1 + "," + classAvg2 + "," + classAvg3;
String output = classAverages + " | " + studentAverages.toString();
context.write(key, new Text(output));
}
}
package experiment.big101;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SMain {
public static void main(String[] args) throws Exception {
args = new String[] { "hdfs://master:9000/root/experiment/datas", "hdfs://master:9000/root/experiment/output" };
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SMain.class);
job.setMapperClass(SMapper.class);
job.setReducerClass(SReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}






