
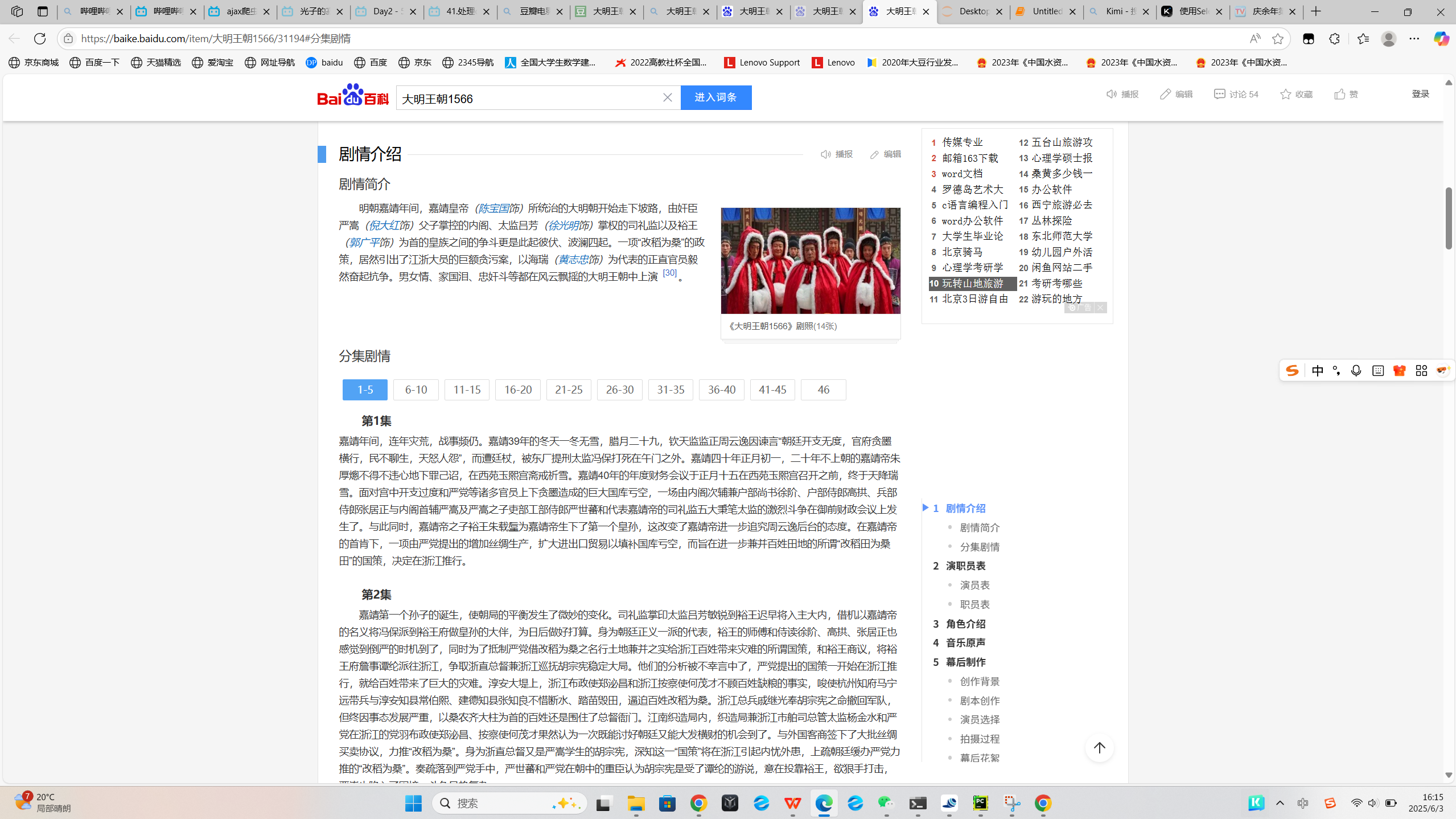
如何爬取大明王朝1566的全部分集剧情
我的初步代码如下
import requests
from bs4 import BeautifulSoup
网页地址
发送请求
response = requests.get(url)
检查请求是否成功
if response.status_code == 200:
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 定位到 <ul class="plotWrap_M_TLr"></ul> 容器
plot_wrap = soup.find('ul', class_='plotWrap_M_TLr')
# 如果容器存在
if plot_wrap:
# 在该容器内查找所有符合条件的 <span> 标签
span_tags = plot_wrap.find_all('span', class_='text_FvX0x', attrs={'data-text': 'true'})
# 提取并打印内容
for span in span_tags:
print(span.get_text(strip=True))
else:
print("未找到 <ul class='plotWrap_M_TLr'> 容器")
else:
print("请求失败,状态码:", response.status_code)






