
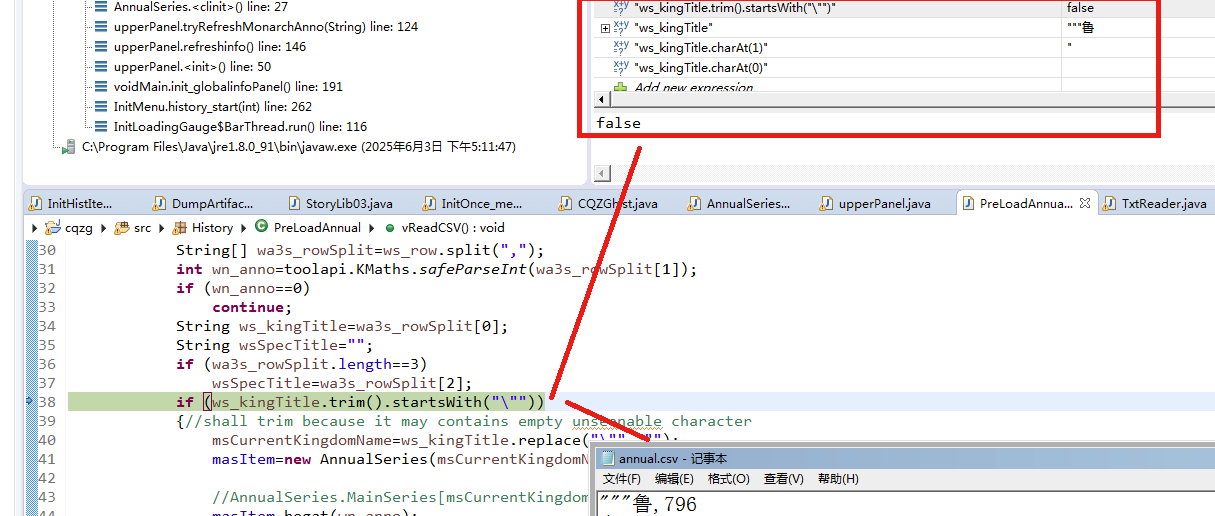
以前的程序是读取一个文本文件,一直好的,今天刚改了一些具体内容,再保存运行就报错了
读取utf-8保存的文本文件,第一行是 """鲁
结果记事本保存了一下之后
if (ws_kingTitle.startsWith("""))就是false了
一看
charAt(1)才是我的",chatAt(0)是一个空的,但不是null
我已经重新新建一个文本文件,把字符都复制过去了,第一次保存就直接把ansi改为utf-8也不顶用
是不是最前面包含了一个不可见字符?

以前的程序是读取一个文本文件,一直好的,今天刚改了一些具体内容,再保存运行就报错了
读取utf-8保存的文本文件,第一行是 """鲁
结果记事本保存了一下之后
if (ws_kingTitle.startsWith("""))就是false了
一看
charAt(1)才是我的",chatAt(0)是一个空的,但不是null
我已经重新新建一个文本文件,把字符都复制过去了,第一次保存就直接把ansi改为utf-8也不顶用
是不是最前面包含了一个不可见字符?
 分享
分享
下午好🌅🌅🌅
本答案参考通义千问
从你的描述来看,问题可能是文本文件中存在不可见字符(如 BOM - Byte Order Mark)或编码问题导致的。UTF-8 文件可能包含了 BOM 字符(EF BB BF),这在某些情况下会导致 charAt(0) 返回看似“空”的字符。
以下是可能的原因和解决方案:
BOM 字符的存在:
EF BB BF),用于标记文件为 UTF-8 编码。charAt(0) 会返回 BOM 的第一个字节(例如 \uFEFF),而不是你预期的内容。文件内容问题:
charAt(0) 返回的是这些字符。编码问题:
可以使用以下代码检查文件开头是否有 BOM 字符:
import java.io.FileInputStream;
import java.io.IOException;
public class CheckBOM {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("yourfile.txt")) {
byte[] bom = new byte[3];
int read = fis.read(bom);
if (read == 3 && bom[0] == (byte) 0xEF && bom[1] == (byte) 0xBB && bom[2] == (byte) 0xBF) {
System.out.println("文件包含 BOM");
} else {
System.out.println("文件不包含 BOM");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
如果输出是“文件包含 BOM”,说明文件确实有 BOM 字符。
如果文件包含 BOM,可以通过以下方式去掉 BOM 字符后读取文件内容:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class RemoveBOM {
public static String readFileWithoutBOM(String filePath) throws IOException {
StringBuilder content = new StringBuilder();
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
// 跳过可能存在的 BOM
if (reader.ready()) {
char firstChar = (char) reader.read();
if (firstChar != '\uFEFF') { // \uFEFF 是 BOM 的 Unicode 表示
content.append(firstChar);
}
}
String line;
while ((line = reader.readLine()) != null) {
content.append(line).append("\n");
}
}
return content.toString();
}
public static void main(String[] args) {
try {
String content = readFileWithoutBOM("yourfile.txt");
System.out.println("文件内容: " + content);
} catch (IOException e) {
e.printStackTrace();
}
}
}
如果你需要确保文件以 UTF-8 编码保存且没有 BOM,可以使用以下代码保存文件:
import java.io.FileWriter;
import java.io.IOException;
public class SaveWithoutBOM {
public static void saveFileWithoutBOM(String filePath, String content) {
try (FileWriter writer = new FileWriter(filePath)) {
writer.write(content);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String content = "鲁";
saveFileWithoutBOM("yourfile.txt", content);
System.out.println("文件已保存");
}
}
Scanner 或 Files.readString 读取文件Java 提供了更现代的方式来读取文件内容,可以避免手动处理 BOM 问题:
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Scanner;
public class ReadFileModern {
public static void main(String[] args) {
try {
// 使用 Files.readString 读取文件内容
String content = Files.readString(Paths.get("yourfile.txt"));
System.out.println("文件内容: " + content);
// 或者使用 Scanner 读取文件内容
Scanner scanner = new Scanner(Paths.get("yourfile.txt"), "UTF-8");
String line = scanner.nextLine();
System.out.println("第一行内容: " + line);
scanner.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Files.readString 或 Scanner)读取文件,减少手动处理编码问题的可能性。希望以上解决方案能解决你的问题!如果还有其他疑问,请随时补充说明。
分享 系统已结题
6月11日
系统已结题
6月11日 已采纳回答
6月3日
创建了问题
6月3日
已采纳回答
6月3日
创建了问题
6月3日


