web scraper相关问题
需求:一个有分页器的列表,需要获取每一页的每一个a链接,并且点击a链接进入详情页获取信息。
遇到的问题
- a链接可以预览到但没有数据
元素预览: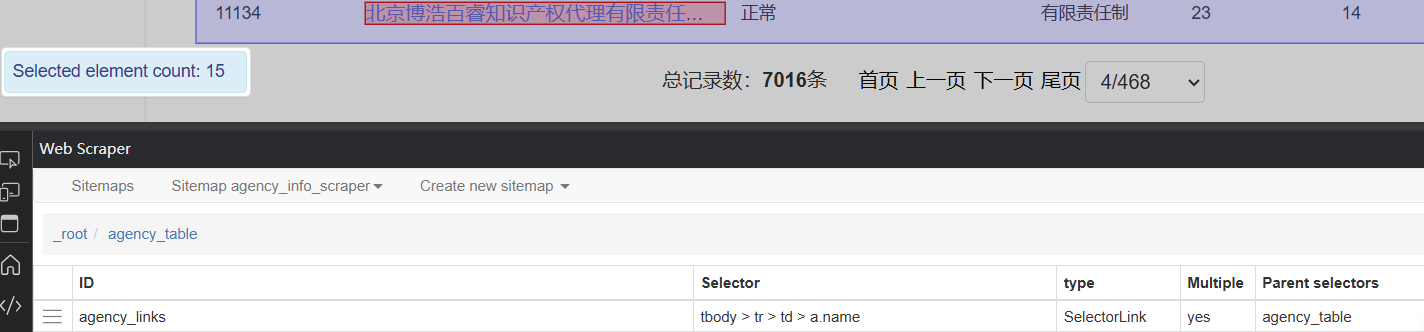
数据预览:
- 该网站点击“下一页”后会刷新网页,于是我参考了这篇文章进行翻页
https://zhuanlan.zhihu.com/p/94387525
但是获取到的数据只有一页
我的截图: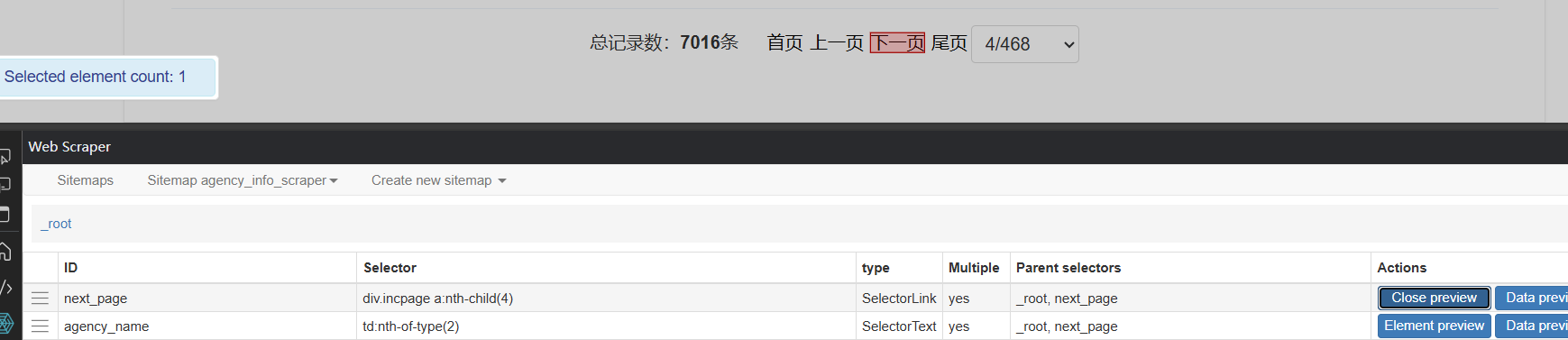

web scraper相关问题
需求:一个有分页器的列表,需要获取每一页的每一个a链接,并且点击a链接进入详情页获取信息。
遇到的问题
数据预览:
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
你遇到的问题是使用 web 爬虫获取有分页器的列表中每一页的每一个 a 链接,并点击 a 链接进入详情页获取信息。
问题的关键是如何获取 a 链接的数据元素。通常情况下,a 链接的数据元素是通过 JavaScript 动态生成的,这使得爬虫难以获取。
解决方案:
requests 和 BeautifulSoup 库来获取网页内容。Selenium 库来模拟浏览器行为,点击 a 链接并获取详情页内容。regex 库来提取 a 链接中的数据元素。以下是一个简单的示例代码:
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
import re
# 获取列表页内容
url = "https://example.com/list"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# 获取每一页的每一个 a 链接
links = []
for link in soup.find_all("a"):
links.append(link.get("href"))
# 使用 Selenium 模拟浏览器行为,点击 a 链接并获取详情页内容
driver = webdriver.Chrome()
for link in links:
driver.get(link)
# 获取详情页内容
detail_content = driver.page_source
# 提取数据元素
data = re.search(r"数据元素正则表达式", detail_content).group()
print(data)
# 关闭浏览器
driver.quit()
请注意,这只是一个简单的示例代码,实际情况中可能需要根据具体情况进行修改。
分享 创建了问题
6月9日
创建了问题
6月9日

