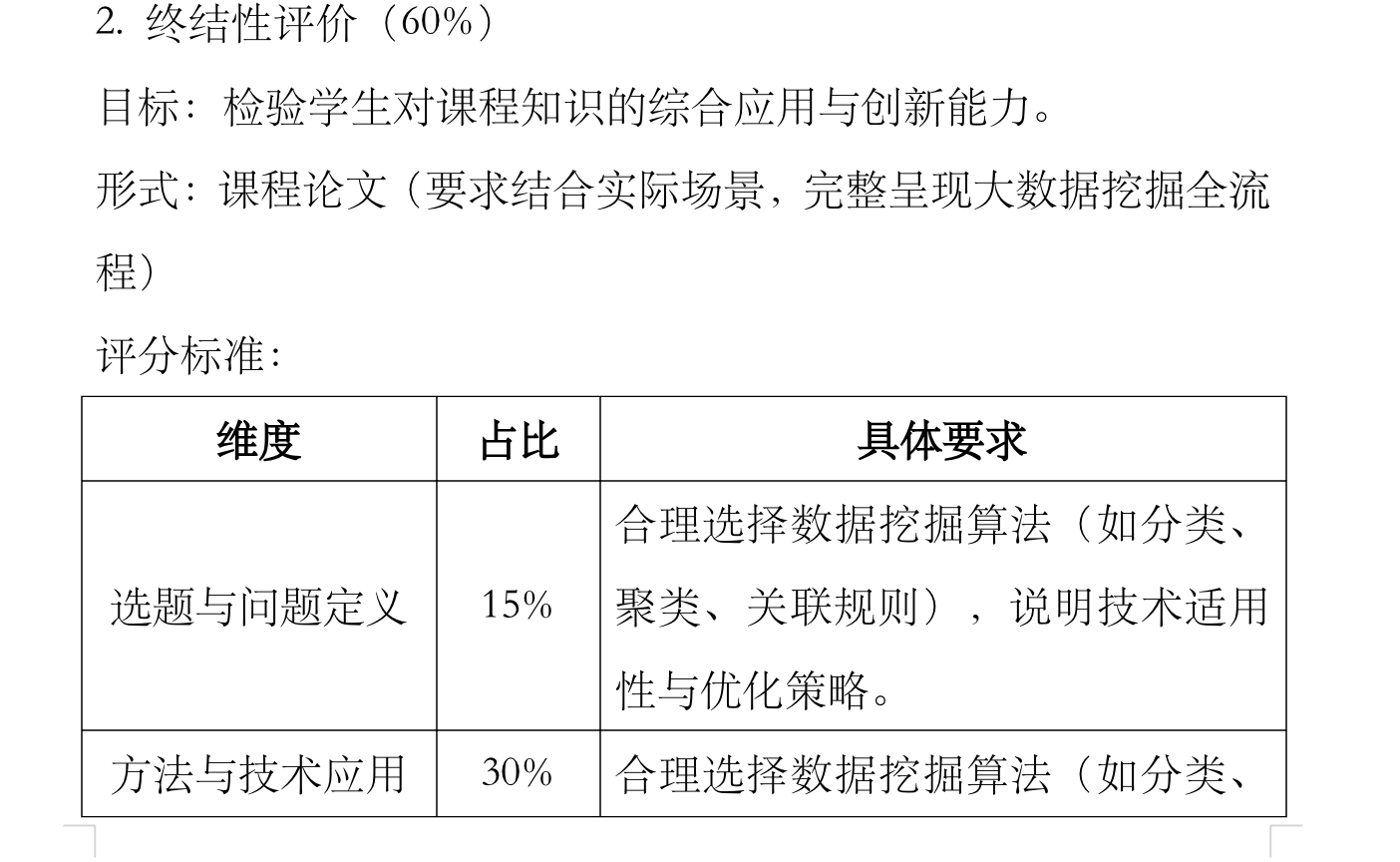
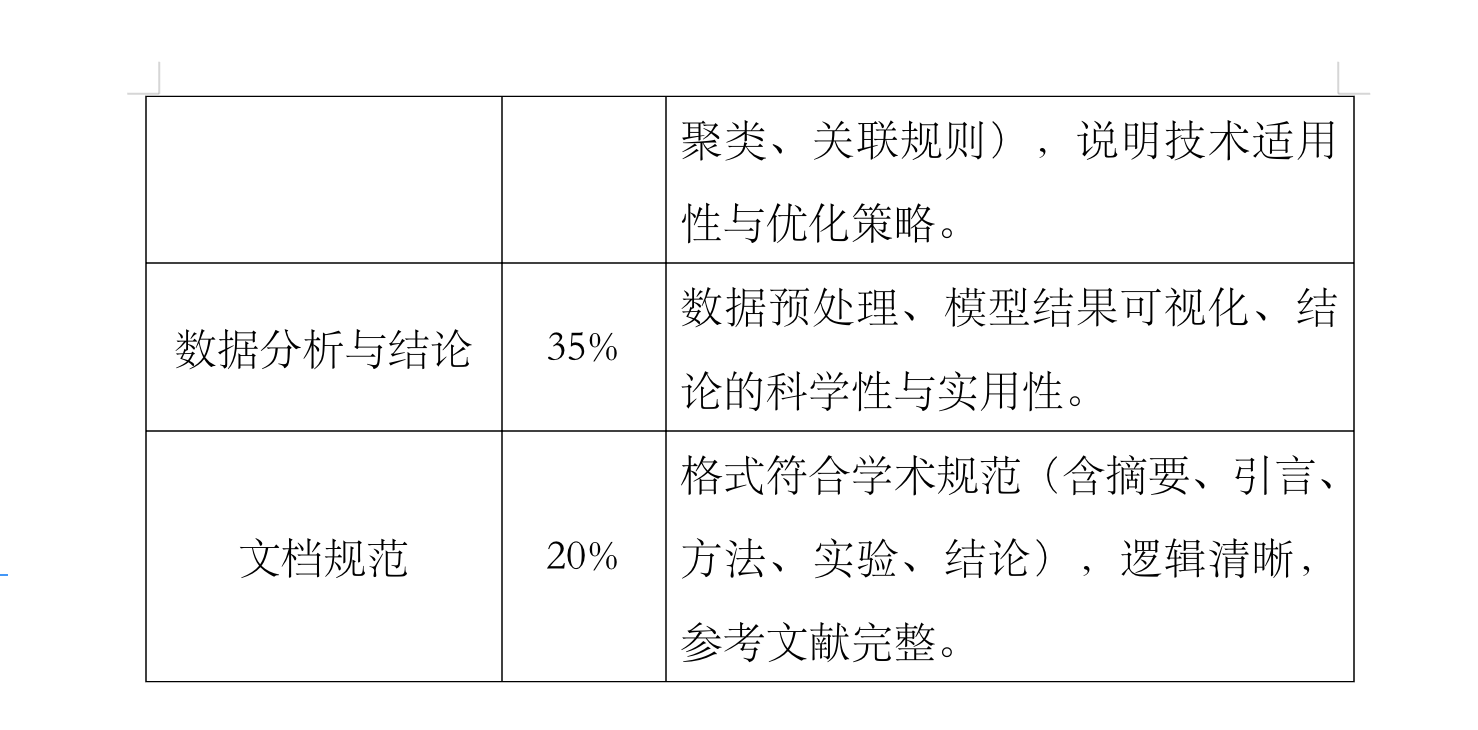
课程论文(要求结合实际场景,完整呈现大数据挖掘全流程),求提供一些思路或帮忙代写。

 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
大数据挖掘课程论文是指结合实际场景,完整呈现大数据挖掘全流程的论文。下面是一些思路:
在选择数据挖掘算法时,需要考虑实际场景和数据特点。以下是一些常用的算法:
以下是一个简单的代码示例,使用 scikit-learn 库实现决策树算法:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据加载
X = ... # 特征数据
y = ... # 目标数据
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 决策树模型
clf = DecisionTreeClassifier(random_state=42)
# 模型训练
clf.fit(X_train, y_train)
# 模型评估
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
注意:上面的代码只是一个简单的示例,实际情况中需要根据实际场景和数据特点选择合适的算法和参数。
分享 修改了问题
6月14日
创建了问题
6月14日
修改了问题
6月14日
创建了问题
6月14日


