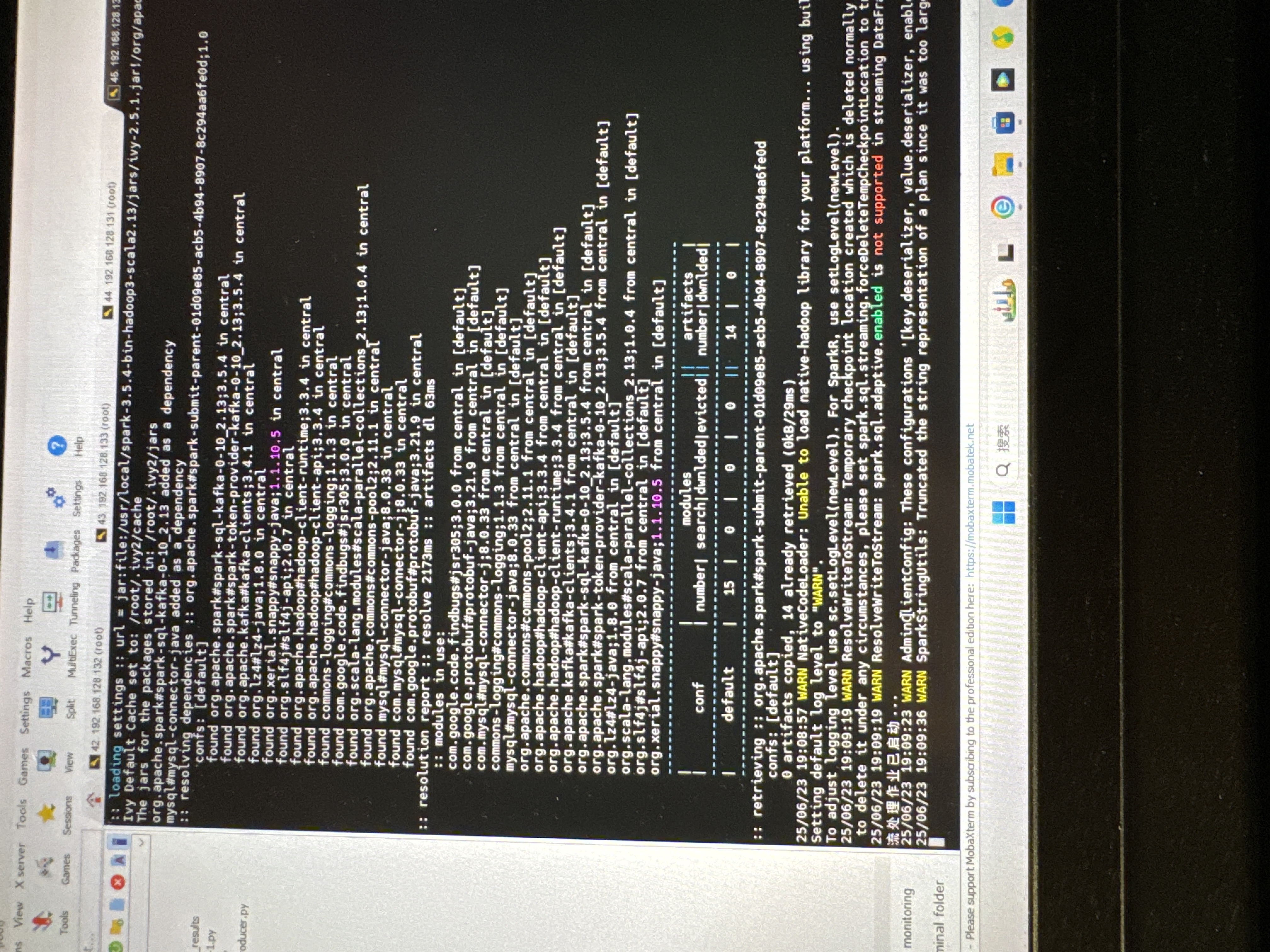
spark实时处理并传输到mysql数据库时,显示流处理已启动,卡住很久不动然后报错是什么原因?
我们的流程是爬取股票数据,3s刷新,然后传输到kafka里面,接着spark实时处理并存储到mysql里面,mysql库和表我已经创建好了,最后可视化处理。spark实时处理和存储mysql出问题,报错为broker的问题

 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
Spark实时处理并传输到 MySQL 数据库时,卡住很久不动然后报错可能是由于以下原因:
spark.sql.shuffle.partitions 参数来调整分区数量,以减少网络传输的压力。spark.sql.shuffle.partitions 参数来调整分区数量,以减少数据量。spark.jars 参数来指定 MySQL 驱动程序的路径。spark-defaults.conf)中的参数是否正确。kafka-console-consumer 命令来消费 topic。以下是一个简单的示例代码,用于 Spark 实时处理并传输到 MySQL 数据库:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object SparkRealtimeProcessing {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder.appName("Spark Realtime Processing").getOrCreate()
// 读取 Kafka topic
val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", "localhost:9092").option("subscribe", "stock_data").load()
// 处理数据
val processedDF = kafkaDF.selectExpr("CAST(value AS STRING)").selectExpr("split(value, ',')[0] AS stock_code", "split(value, ',')[1] AS stock_price")
// 传输到 MySQL 数据库
processedDF.write.format("jdbc").option("url", "jdbc:mysql://localhost:3306/stock_data").option("dbtable", "stock_data").option("user", "root").option("password", "password").save()
spark.stop()
}
}
请注意,这只是一个简单的示例代码,实际情况可能需要根据具体情况进行调整。
分享 创建了问题
6月23日
创建了问题
6月23日

