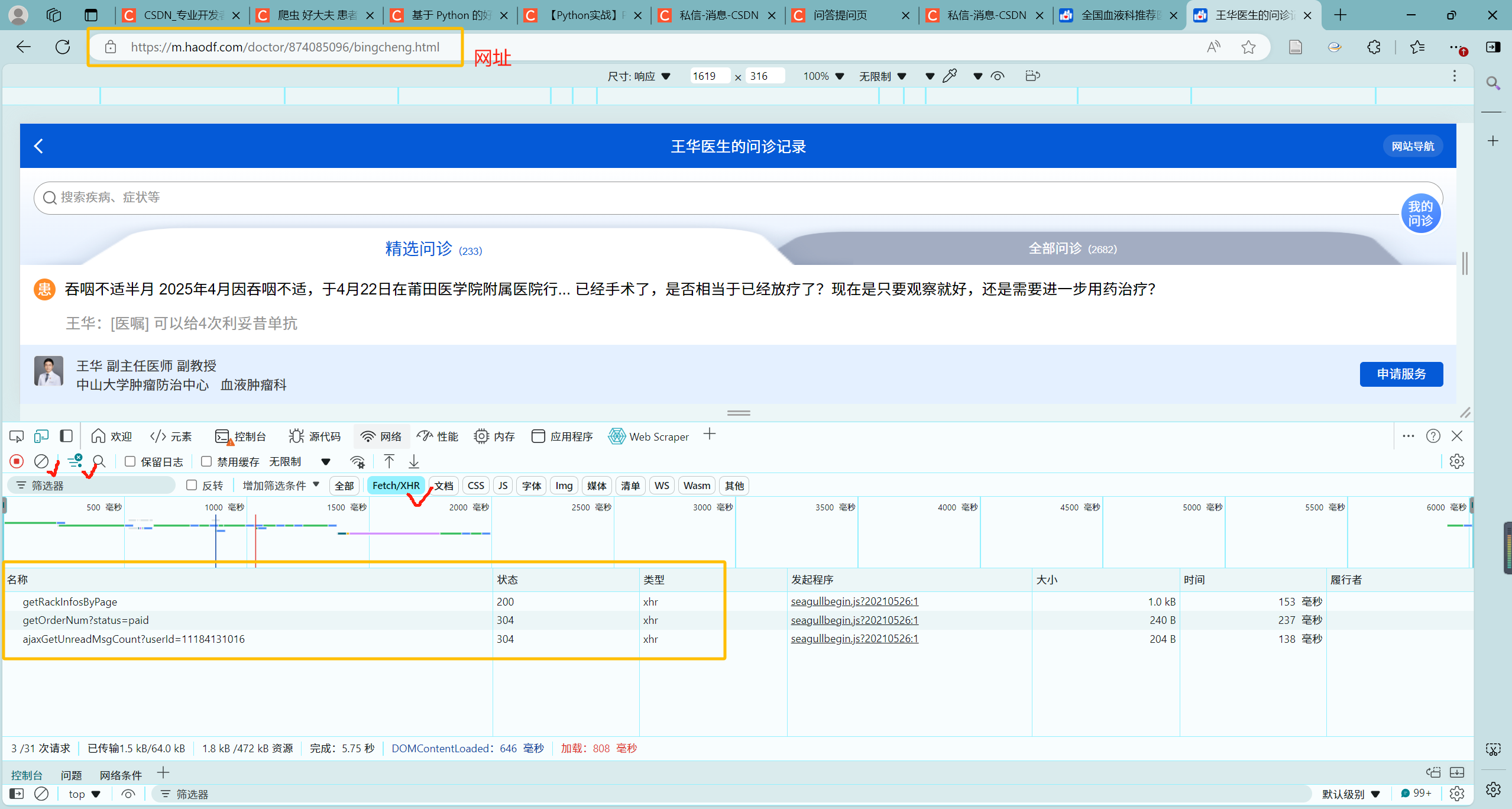
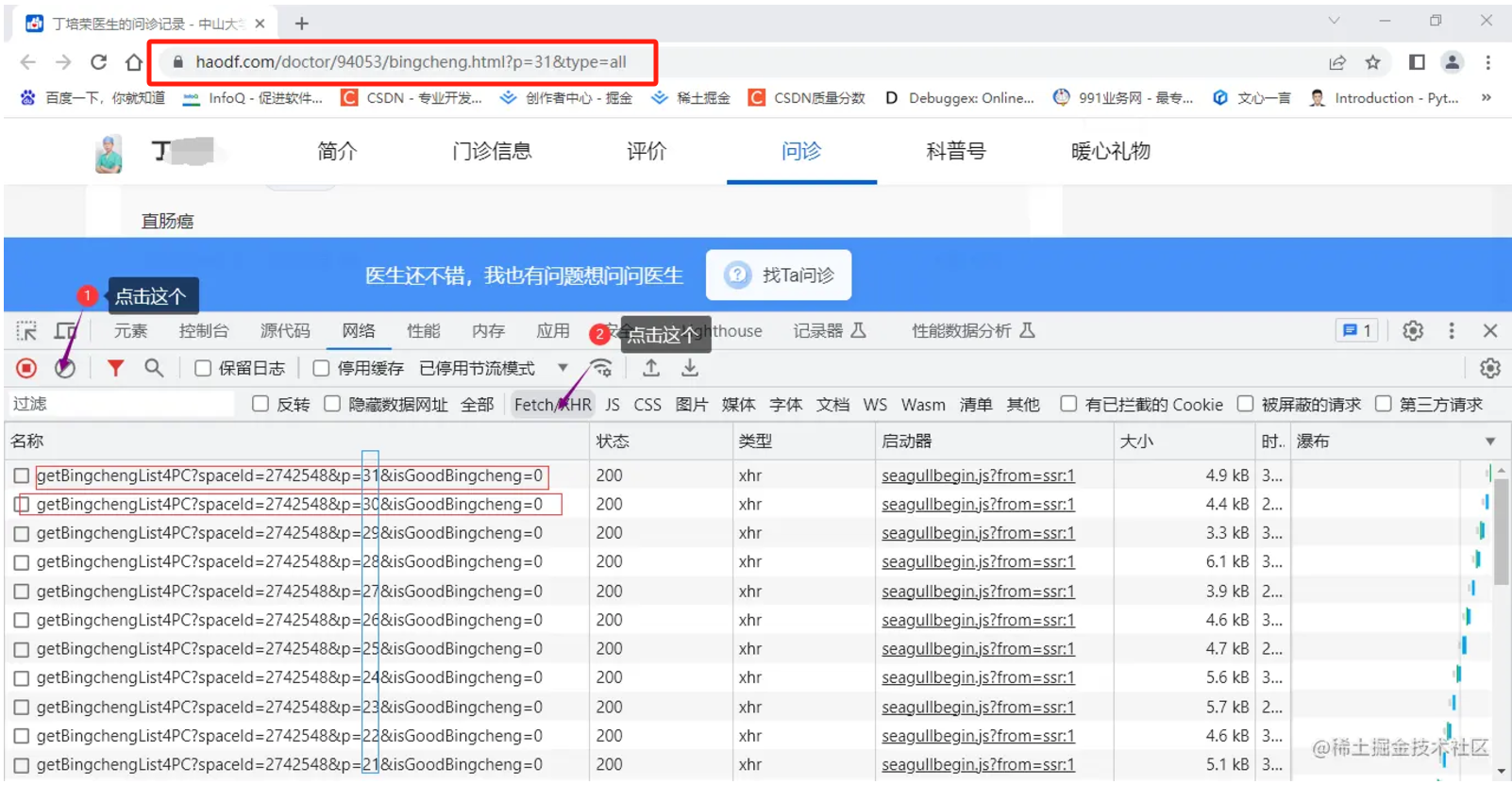
请问大家要如何才能够爬取到“好大夫网站”的完整患者评论呢?在爬取的时候发现电脑网页端只能查看部分患者评价,手机APP端才能查看完整评价,通过开发者工具获取的信息和教程上显示的也完全不同。这个问题困惑我非常久了,但是由于本人不懂如何解决,求解惑!QAQ
参照的是这位大大的教程@小敢摘葡萄 如果您能够看到的话,不知能否为我解答疑惑(滑跪)

请问大家要如何才能够爬取到“好大夫网站”的完整患者评论呢?在爬取的时候发现电脑网页端只能查看部分患者评价,手机APP端才能查看完整评价,通过开发者工具获取的信息和教程上显示的也完全不同。这个问题困惑我非常久了,但是由于本人不懂如何解决,求解惑!QAQ
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
你遇到的问题是大夫网站的评论部分在电脑网页端和手机APP端显示不同,导致爬取完整评论变得困难。下面是一些可能的解决方案:
requests 和 BeautifulSoup 库模拟手机APP端的请求,获取完整评论。可以通过分析开发者工具获取的信息和教程上显示的信息来模拟请求。requests 库中的 proxies 参数来设置代理服务器。BeautifulSoup 库来解析评论的 HTML 结构,获取完整评论。以下是一个简单的示例代码,使用 requests 和 BeautifulSoup 库模拟手机APP端请求,获取完整评论:
import requests
from bs4 import BeautifulSoup
# 设置代理服务器
proxies = {
'http': 'http://your-proxy-server.com:8080',
'https': 'http://your-proxy-server.com:8080'
}
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'
}
# 发送请求
response = requests.get('https://www.haodf.com/...', headers=headers, proxies=proxies)
# 解析 HTML 结构
soup = BeautifulSoup(response.content, 'html.parser')
# 获取评论
comments = soup.find_all('div', {'class': 'comment'})
# 遍历评论
for comment in comments:
print(comment.text.strip())
请注意,这只是一个简单的示例代码,实际情况中可能需要更多的处理和调整。
分享 创建了问题
7月4日
创建了问题
7月4日


