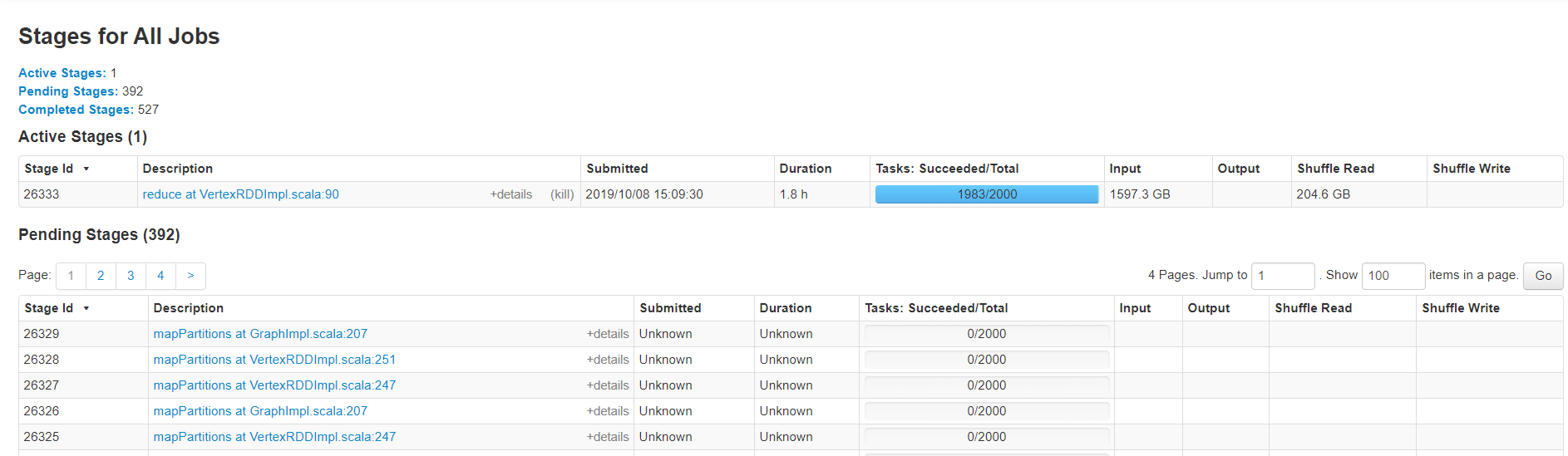

spark 程序卡在在很长时间,基本没有变化,只有图中的imput在不断增加,求解决

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

- 2018-11-27 12:08回答 5 已采纳 拿你用Input试试https://www.iviewui.com/components/input
- 2023-02-28 09:10回答 3 已采纳 该回答引用ChatGPT 在 Python 中,右尖括号(">")通常用于交互式命令行提示符中,用于指示代码块的缩进级别,而在实际编写 Python 代码中并不需要输入这些右尖括号。在编写代码
- 2022-07-23 00:46回答 1 已采纳 在script中向控制层发送请求携带该值,控制层将该值放到session域中,input里用${sessionscope.name}取就好了。
- 2020-12-12 10:01在写css时,使得input和img在同一行居中对齐的方法: 复制代码代码如下:img{vertical-align:middle;} input{width:宽度;height:高度;line-height:与高度一致;margin:0px;padding;0px;font-size:字体大小;border:边
- 2013-04-07 03:29回答 1 已采纳 试试android:gravity="top":
- 2022-09-09 10:45回答 1 已采纳 calc.h #ifndef CALC_H #define CALC_H extern float add(float a, float b); extern float sub(float a,
- 2016-03-23 14:23回答 2 已采纳 from TFM: ReadString reads until the first occurrence of delim in the input, returning a strin
- 2021-04-18 11:00恋猫的博客 reply = 'Y';while reply == 'Y'score=input('Please input your score: ');if isempty(score)score = 60;endif (score < 60) && (score >= 0)disp('E');elseif (score >= 60) &...
- 2023-03-16 20:30回答 3 已采纳 程序整个思路有问题 book.ISBN[i]这里你似乎是觉得是数组,但是你books中的isbn是string,不是string数组下面很多都是同理 你要先搞清楚books到底代表一本书,还是所有的
- 2014-10-12 17:29回答 2 已采纳 Yes, you should always sanitize all input. Just because you're giving the user a choice from a sel
- 2022-07-22 13:46回答 6 已采纳 v-model.lazy实际为onchange事件和v-bind结合。如果要实现格式化,失去焦点显示格式化值,获取焦点显示原始值,可以用v-bind绑定显示值,onblur事件获取输入值设置proto
- 2021-03-14 10:33xu kaihe的博客 2008-09-21 回答java初学者,一定对从键盘输入数据感到困难,使用下面的类Input,可以方便的从键盘输入... 读入整数下面是java输入输出基本类Input类的源代码:最后以从键盘输入10个整数为例说明之。import java.io.*;...
- 2022-05-05 14:34回答 2 已采纳 一边定义了数组长度,一边又要判断输入 % 结束,这本身就是 相悖的
- 2021-04-23 22:02weixin_39531688的博客 超强大的图论程序图论程序大全程序一:可达矩阵算法function P=dgraf(A) n=size(A,1); P=A; for i=2:n P=P+A^i; end P(P~=0)=1; P;程序二:关联矩阵和邻接矩阵互换算法function W=incandadf(F,f) if f==0 m=sum(sum...
- 2020-11-24 13:16weixin_39729262的博客 程序设计基本方法计算机与程序设计计算机是根据指令操作数据的设备两大特点:1、功能性,对数据的操作,表现为数据计算、输入输出处理和结果存储等2、可编程性,可根据一系列指令自动滴、可预测滴、准确滴完成操作者...
- weixin_39738115的博客 【判断题】在Python 3.X中,input()函数把用户的键盘输入作为字符串返回 (5.0分)【判断题】由于冰的导热系数比水大4倍,热扩散系数大9倍,所以在相同温度差的条件下,(但升降的方向相反),组织材料...
- 2022-10-19 22:12LeMiaokai的博客 如何通过Python将指定文件夹中,符合指定命名规则的图片添加指定的文字内容,最后按指定的命名规则将添加文字后的图片保存到指定的文件夹中。比如,可以通过Python在健康码,行程卡的截图上方便的添加文字内容,省心...
- 2020-11-25 22:41weixin_39872257的博客 程序设计基本方法计算机与程序设计计算机是根据指令操作数据的设备两大特点:1、功能性,对数据的操作,表现为数据计算、输入输出处理和结果存储等2、可编程性,可根据一系列指令自动滴、可预测滴、准确滴完成操作者...
- 2020-10-21 05:32主要介绍了Javascript 动态改变imput type属性的相关资料,并附简单实例代码,需要的朋友可以参考下
- 2019-07-01 22:49cidao9241的博客 应用场景 生成带二维码的推广海报图片 旧方法: 将用户自己的推广连接先通过qrcode.js生成二维码,然后再用后台返回的一张背景图片和二维码通过canvas绘制成一张...在部分安卓手机上获取二维码图片后,onload...
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 R语言Rstudio突然无法启动
- ¥15 关于#matlab#的问题:提取2个图像的变量作为另外一个图像像元的移动量,计算新的位置创建新的图像并提取第二个图像的变量到新的图像
- ¥15 改算法,照着压缩包里边,参考其他代码封装的格式 写到main函数里
- ¥15 用windows做服务的同志有吗
- ¥60 求一个简单的网页(标签-安全|关键词-上传)
- ¥35 lstm时间序列共享单车预测,loss值优化,参数优化算法
- ¥15 Python中的request,如何使用ssr节点,通过代理requests网页。本人在泰国,需要用大陆ip才能玩网页游戏,合法合规。
- ¥100 为什么这个恒流源电路不能恒流?
- ¥15 有偿求跨组件数据流路径图
- ¥15 写一个方法checkPerson,入参实体类Person,出参布尔值