让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
若您愿意支持,欢迎直接打赏,将不胜感激!
上海证券交易所发行上市数据爬取方案
根据您提供的需求,我将为您设计一个爬取上海证券交易所发行上市数据的Python爬虫方案。该爬虫将爬取639页共15959条数据,包括发行人信息和文件名称。
分析目标网站
- 目标URL:
https://www.sse.com.cn/listing/renewal/ipo/index_listing_detail.shtml?auditId=1783 - 数据格式: 表格形式,分页显示
- 需要爬取: 发行人名称、文件名称、披露日期等信息
爬虫实现方案
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
import os
# 请求头设置
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://www.sse.com.cn/'
}
# 基础URL
base_url = 'https://www.sse.com.cn/listing/renewal/ipo/index_listing_detail.shtml'
def get_page_data(page_num):
"""获取单页数据"""
params = {
'auditId': 1783,
'pageNo': page_num,
'pageSize': 25 # 每页25条数据
}
try:
response = requests.get(base_url, params=params, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 提取表格数据
table = soup.find('table', {'class': 'table table-striped'})
if not table:
return None
rows = table.find_all('tr')[1:] # 跳过表头
data = []
for row in rows:
cols = row.find_all('td')
if len(cols) >= 4:
item = {
'发行人': cols[0].get_text(strip=True),
'文件名称': cols[1].get_text(strip=True),
'披露日期': cols[2].get_text(strip=True),
'板块': cols[3].get_text(strip=True)
}
# 提取文件链接
file_link = cols[1].find('a')
if file_link and file_link.get('href'):
item['文件链接'] = 'https://www.sse.com.cn' + file_link['href']
data.append(item)
return data
except Exception as e:
print(f"获取第{page_num}页数据失败: {e}")
return None
def download_file(url, save_path):
"""下载文件"""
try:
response = requests.get(url, headers=headers, stream=True)
response.raise_for_status()
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
f.write(chunk)
return True
except Exception as e:
print(f"下载文件失败: {url}, 错误: {e}")
return False
def main():
# 创建保存目录
if not os.path.exists('sse_data'):
os.makedirs('sse_data')
if not os.path.exists('sse_data/files'):
os.makedirs('sse_data/files')
all_data = []
total_pages = 639 # 总页数
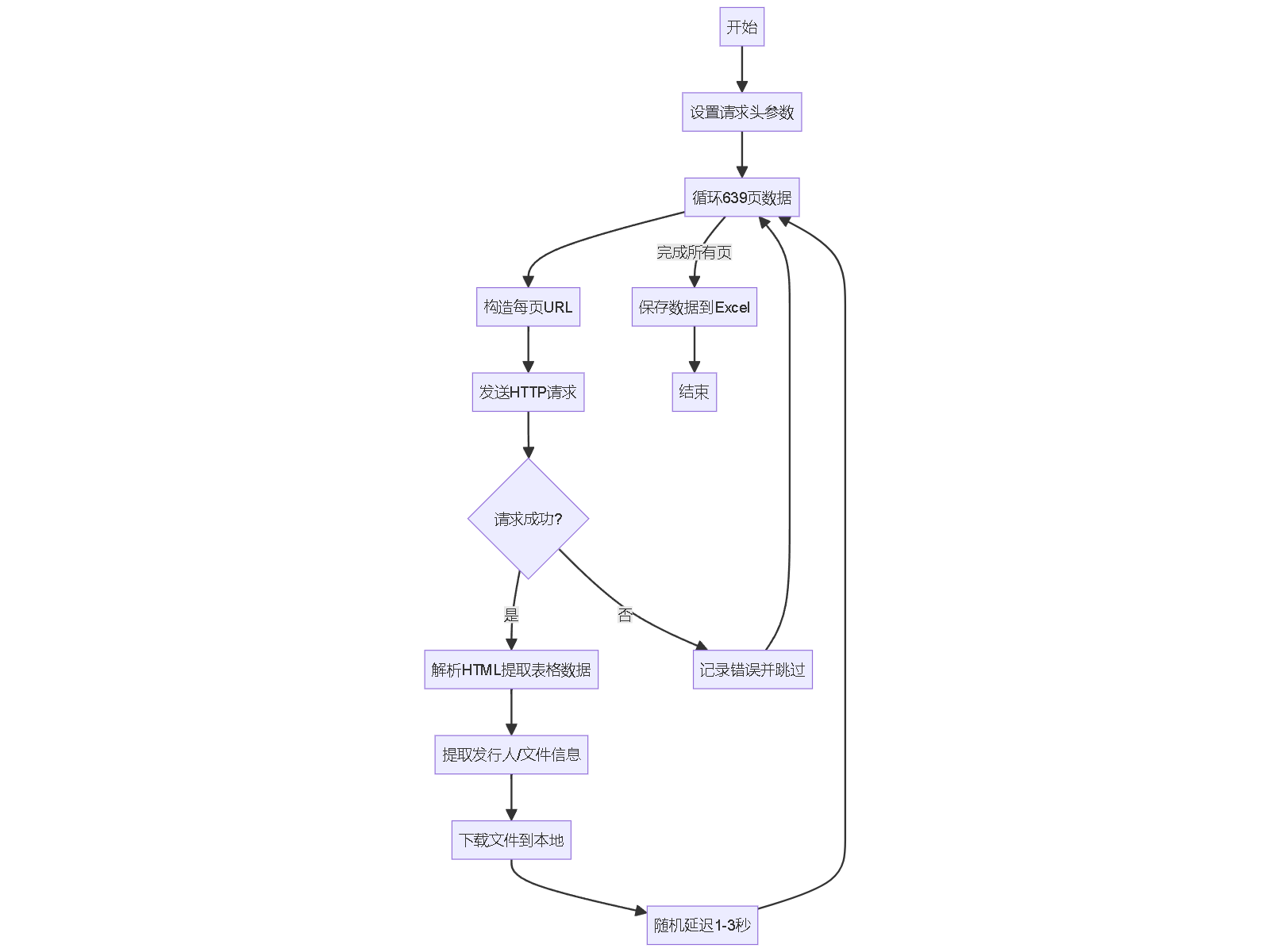
for page in range(1, total_pages + 1):
print(f"正在爬取第{page}页...")
page_data = get_page_data(page)
if page_data:
all_data.extend(page_data)
# 下载文件
for item in page_data:
if '文件链接' in item:
file_name = f"{item['发行人']}_{item['文件名称']}.pdf"
# 清理文件名中的非法字符
file_name = ''.join(c for c in file_name if c.isalnum() or c in (' ', '_', '-', '.'))
save_path = os.path.join('sse_data/files', file_name)
if not os.path.exists(save_path):
download_file(item['文件链接'], save_path)
time.sleep(random.uniform(1, 3)) # 随机延迟
time.sleep(random.uniform(2, 5)) # 防止请求过于频繁
# 每50页保存一次进度
if page % 50 == 0:
df = pd.DataFrame(all_data)
df.to_excel(f'sse_data/sse_listing_data_page_{page}.xlsx', index=False)
print(f"已保存前{page}页数据")
# 保存最终数据
df = pd.DataFrame(all_data)
df.to_excel('sse_data/sse_listing_data_final.xlsx', index=False)
print("所有数据爬取完成!")
if __name__ == '__main__':
main()
爬虫工作流程
注意事项
- 反爬机制:
- 添加了随机延迟,避免请求过于频繁
- 使用了合理的User-Agent和Referer
- 建议在非高峰时段运行爬虫
- 数据存储:
- 数据会保存为Excel文件
- 文件会下载到本地
sse_data/files目录 - 每50页会保存一次进度
- 扩展功能:
- 可以添加代理IP池增强稳定性
- 可以增加重试机制处理失败请求
- 可以添加日志记录功能
- 法律合规:
- 请确保您的爬取行为符合上海证券交易所的使用条款
- 不要对网站造成过大负担
- 爬取的数据仅用于个人学习研究
如果需要更详细的实现或有任何问题,请随时提问。