
现在使用【Tesseract OCR】遇到几个问题
1.表格行列识别对不齐,上下错位
2.英文数字个别识别不准确,但是中文识别很差,不知道如何训练字体
3.如果有类似经验私信我,感谢🙏
4.很多方案是python的,我是我们开发是c++很多库使用不了

Tesseract OCR 处理表格,有偿

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

5条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以点击头像关注私信或评论。如果答案让您满意,请采纳、点赞、关注,非常感谢!
若您愿意支持,欢迎直接打赏,将不胜感激!
Tesseract OCR表格处理问题解决方案
针对您提到的Tesseract OCR处理表格时遇到的问题,我将提供C++方向的解决方案:
1. 表格行列识别错位问题
表格识别是OCR中的难点,建议采用以下方法:
// 预处理代码示例 #include <leptonica/allheaders.h> #include <tesseract/baseapi.h> void processTableImage(const char* inputImage) { // 1. 图像预处理 Pix* image = pixRead(inputImage); Pix* grayscale = pixConvertRGBToGray(image, 0.0, 0.0, 0.0); Pix* binary = pixThresholdToBinary(grayscale, 150); // 二值化 // 2. 表格线检测增强 Pix* lines = pixGenerateLineSegments(binary, 1); // 检测直线 // 3. 使用Tesseract OCR tesseract::TessBaseAPI* api = new tesseract::TessBaseAPI(); api->Init(NULL, "chi_sim+eng", tesseract::OEM_LSTM_ONLY); api->SetImage(lines); api->SetPageSegMode(tesseract::PSM_AUTO_OSD); // 获取结果 char* outText = api->GetUTF8Text(); printf("%s", outText); // 释放资源 api->End(); delete api; pixDestroy(&image); }2. 识别准确率问题
中文识别差解决方案:
- 确保使用中文训练数据(chi_sim.traineddata)
- 预处理图像增强对比度
- 考虑使用更高分辨率的输入
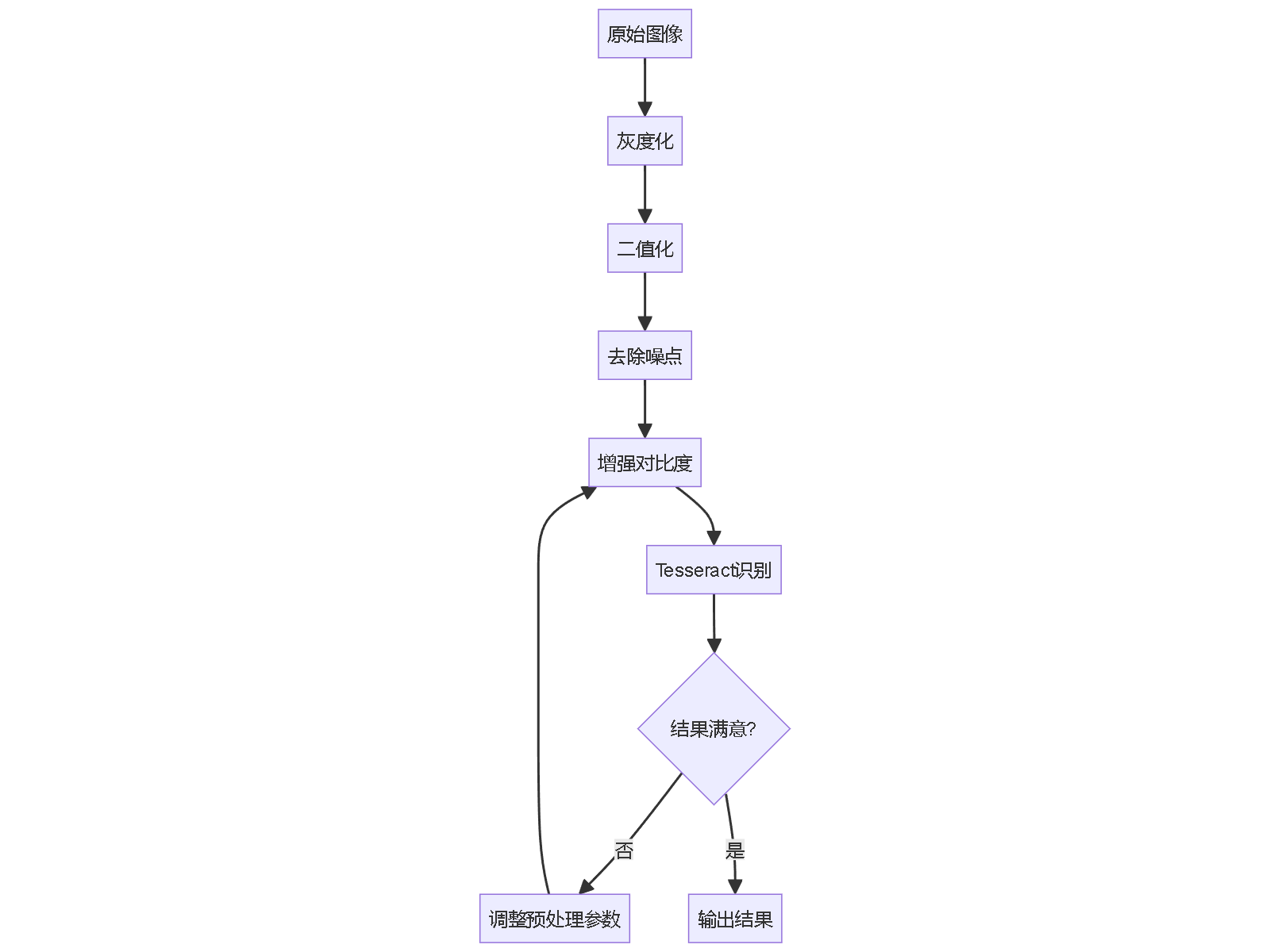
训练自定义字体:
- 准备训练样本(至少10页相同字体的文本)
- 使用jTessBoxEditor工具修正识别结果
- 执行Tesseract训练命令:
# 生成.box文件 tesseract chi.custom.exp0.tif chi.custom.exp0 -l chi_sim --psm 6 batch.nochop makebox # 生成.tr文件 tesseract chi.custom.exp0.tif chi.custom.exp0 nobatch box.train # 生成字符集 unicharset_extractor chi.custom.exp0.box # 创建字体属性文件 echo "custom 0 0 0 0 0" > font_properties # 训练 shapeclustering -F font_properties -U unicharset chi.custom.exp0.tr mftraining -F font_properties -U unicharset -O chi.unicharset chi.custom.exp0.tr cntraining chi.custom.exp0.tr # 合并数据 combine_tessdata chi.3. C++替代方案
如果Tesseract效果不理想,可以考虑以下C++友好方案:
- OpenCV表格检测:使用霍夫变换检测表格线
- PaddleOCR C++版:百度开源的OCR引擎,对中文支持较好
- EasyOCR C++接口:通过封装Python库提供C++接口
// OpenCV表格检测示例 #include <opencv2/opencv.hpp> void detectTable(const cv::Mat& src) { cv::Mat gray, binary; cv::cvtColor(src, gray, cv::COLOR_BGR2GRAY); cv::threshold(gray, binary, 0, 255, cv::THRESH_BINARY_INV | cv::THRESH_OTSU); // 检测水平和垂直线 cv::Mat horizontal = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(binary.cols/2, 1)); cv::Mat vertical = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(1, binary.rows/2)); cv::Mat horLines, verLines; cv::erode(binary, horLines, horizontal); cv::dilate(horLines, horLines, horizontal); cv::erode(binary, verLines, vertical); cv::dilate(verLines, verLines, vertical); // 合并线条 cv::Mat tableMask = horLines | verLines; }4. 有偿服务建议
如果需要专业团队协助,建议考虑:
- 国内OCR专业公司:百度OCR、阿里云OCR、腾讯OCR
- 开源社区专家:GitHub上寻找有Tesseract经验的开源贡献者
- 专业外包平台:Upwork、Freelancer等寻找有表格OCR经验的开发者
希望这些方案对您有所帮助!如需更具体的实现细节,可以提供更多关于您表格格式和需求的信息。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2025-06-22 20:46资源下载链接为: ...Tesseract OCR是一款开源的光学字符识别引擎,最初由HP公司...Tesseract不仅支持命令行操作,还提供了C++、Python、Java、.NET等多种编程语言的API,方便开发者在应用程序中集成OCR功能。例如,Pytho
- 2025-03-05 15:59Tesseract-OCR的语言包是该引擎的扩展组件,它使得Tesseract能够识别和处理特定语言的文字。语言包中包含了特定语言的字符集、语法规则以及字形数据等,这些都是Tesseract在执行识别过程中不可或缺的参考信息。没有...
- 2026-01-19 17:18tesseract-ocr-tessdata语言包是Tesseract-OCR的一个重要组件,它使得Tesseract-OCR能够识别并翻译多种语言的文字,大大扩展了Tesseract-OCR的应用范围。通过使用tesseract-ocr-tessdata语言包,我们可以将图片文件...
- 2024-03-06 13:22比官网版本12M(2018年的)的要新-- chi_v3_20220621.zip: 包含 v3 版传统模型 (简体 chi_sim,繁体 chi_tra,简繁合并 chi_all) chi_sim, chi_tra 分别包含 7000 常用字,chi_all 包含 8000 常用字,加快识别速度,...
- 2020-03-21 18:27引擎负责处理图像并识别字符,训练数据则包含特定语言的字符模板,API接口允许开发者通过编程方式与OCR引擎交互。在Linux环境下,我们可以使用命令行或者集成到Python项目中来调用Tesseract OCR。 在描述中提到的...
- 2024-04-13 11:25总的来说,Tesseract OCR 训练集提供了基础的识别能力,使Tesseract能够处理多种语言的文本图像,并具备页面布局分析功能。正确使用这些训练数据,可以极大地提高Tesseract在实际应用场景中的性能,使其成为强大的...
- 2025-05-27 09:34TesseractOCR及其语言包为文本识别提供了一个强大而灵活的工具,无论是在研究还是商业应用中,它都是一个值得信赖的选择。随着机器学习和深度学习技术的发展,TesseractOCR的识别精度和效率有望得到进一步提升,其...
- 2021-12-20 22:28在本压缩包“tesseract-ocr安装包和中文语言包”中,应包含有中文语言包文件。安装步骤如下: 1. 解压下载的zip文件。 2. 找到中文语言包文件,通常命名为`chi_sim`或`chi_sim.traineddata`。 3. 将该文件复制到...
- 2025-08-29 16:48此外,Tesseract-ocr的使用并不复杂,它提供了命令行工具和多种编程语言的API接口,使得开发者可以在自己的应用中嵌入Tesseract-ocr的功能。其中,Python因其简洁的语法和强大的社区支持,成为了使用Tesseract-ocr...
- 2025-05-29 10:50在实际应用中,Tesseract-OCR语言包非常适用于需要自动化处理文档的场景,如文档扫描、图片文字提取、验证码识别等。它支持多种操作系统,并且可以通过编程接口与多种编程语言结合使用,从而为开发者提供了灵活性和...
- 2025-03-05 16:01Tesseract-OCR支持多种操作系统,包括Windows、Linux、Mac等,也支持多种编程语言,如C++、Python等。它的安装包通常包含了Tesseract-OCR引擎的源代码和预编译的二进制文件,用户可以根据自己的需要选择使用。 ...
- 2022-03-20 12:42tesseract-ocr安装包和中文语言包.rar
- 2021-03-16 16:57《tesseract-ocr4.0简体中文语言安装包详解》 Tesseract OCR(Optical Character Recognition,光学字符识别)是一款由谷歌维护的开源OCR引擎,它能够识别图像中的文字并转换为可编辑的文本格式。本文将详细阐述...
- 2025-10-10 00:12在Ubuntu上,可以运行:```bashsudo apt-get install tesseract-ocr-zh```在macOS上,安装中文语言包的命令可能类似:```bashbrew cask install tesseract-lang --languages zh```**Tesseract OCR中文支持**...
- 2024-02-26 13:17总结一下,C# TesseractOCR识别身份证号涉及到以下知识点: 1. Tesseract OCR引擎的使用,包括安装、初始化和配置。 2. C#中处理图像的基础操作,如读取、调整大小。 3. OCR识别过程,包括调用Tesseract引擎进行识别...
- 2023-09-13 14:42本文主要围绕“Tesseract OCR简体中文语言包”进行详细讲解,探讨如何使用Tesseract OCR处理中文文本,以及如何利用提供的“chi_sim.traineddata”和“chi_sim_vert.traineddata”文件来提高中文识别的准确性。...
- 2025-05-01 08:58包括两个文件:1.安装包tesseract-ocr-w64-setup-5.5.0.20241111.exe。 2.中文语言包chi_sim.traineddata。 找了好多地方,好不容易才下载下来的语言包,所以分享出来方便大家下载。
- 没有解决我的问题, 去提问

问题事件
 系统已结题
8月15日
系统已结题
8月15日 已采纳回答
8月7日
已采纳回答
8月7日-
创建了问题
7月13日