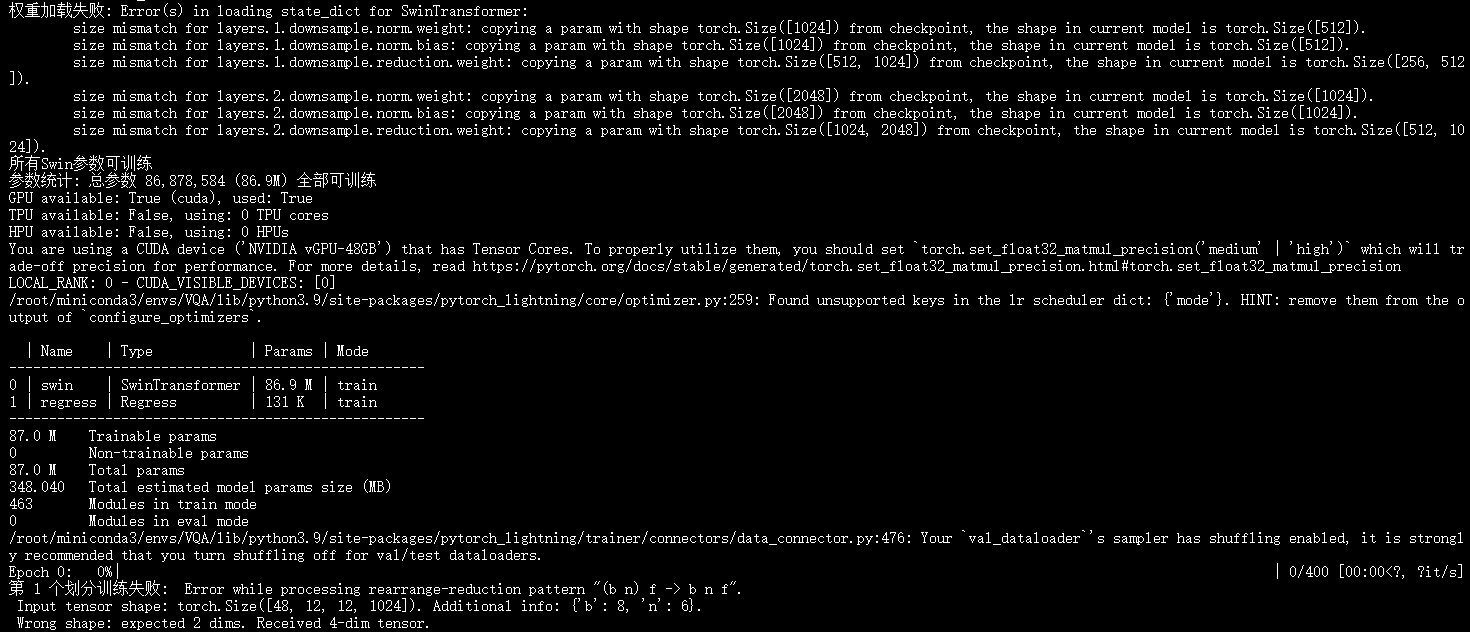
遇到这种问题该如何解决呀,位置是对的,权重大小也是对的,但是就是一直报错

 分享
分享
晚上好🌙🌙🌙
本答案参考通义千问
遇到“权重加载失败”的问题,即使你已经确认了路径正确和权重文件大小匹配,仍然可能由于其他原因导致加载失败。以下是一些常见原因及解决方案:
model = MyModel())与加载的权重文件不匹配。torch.save(model.state_dict(), 'weights.pth')保存的,确保加载时使用的是model.load_state_dict(torch.load('weights.pth'))。eval()或train()模式下加载。重点: 一定要确保模型定义和权重文件是同一个模型结构。
map_location='cpu'来强制将权重加载到CPU:
model.load_state_dict(torch.load('weights.pth', map_location='cpu'))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.load_state_dict(torch.load('weights.pth', map_location=device))
重点: 权重加载时要确保设备一致。
torch.load('weights.pth')手动加载,看是否报错。pickle或json等工具验证文件内容(适用于自定义格式)。重点: 文件大小匹配≠内容完整,建议重新生成或下载权重。
state_dict()和加载的权重字典:
print(model.state_dict().keys())
print(torch.load('weights.pth').keys())
weights = torch.load('weights.pth')
weights = {k.replace('old_name', 'new_name'): v for k, v in weights.items()}
model.load_state_dict(weights)
重点:
state_dict中的键名必须完全匹配。
torch.nn.DataParallel,保存的权重会带有module.前缀。weights = torch.load('weights.pth')
weights = {k.replace('module.', ''): v for k, v in weights.items()}
model.load_state_dict(weights)
map_location并设置strict=False:
model.load_state_dict(torch.load('weights.pth'), strict=False)
重点: 使用
DataParallel时,权重文件中的键名会带有module.前缀。
pip show torch查看版本号。pip install torch==1.9.0+cu111 --extra-index-url https://download.pytorch.org/whl/cu111
重点: 版本一致性是关键!
print(os.path.abspath('weights.pth'))
重点: 路径虽然对,但文件可能无法访问。
strict=False进行宽松加载(调试用)model.load_state_dict(torch.load('weights.pth'), strict=False)
重点: 只用于调试,正式使用应确保严格匹配。
strict=False进行调试。如果你能提供具体的错误信息(如报错内容),我可以进一步帮你定位问题!
分享 创建了问题
7月14日
创建了问题
7月14日


