上午好☀️☀️☀️️
本答案参考通义千问
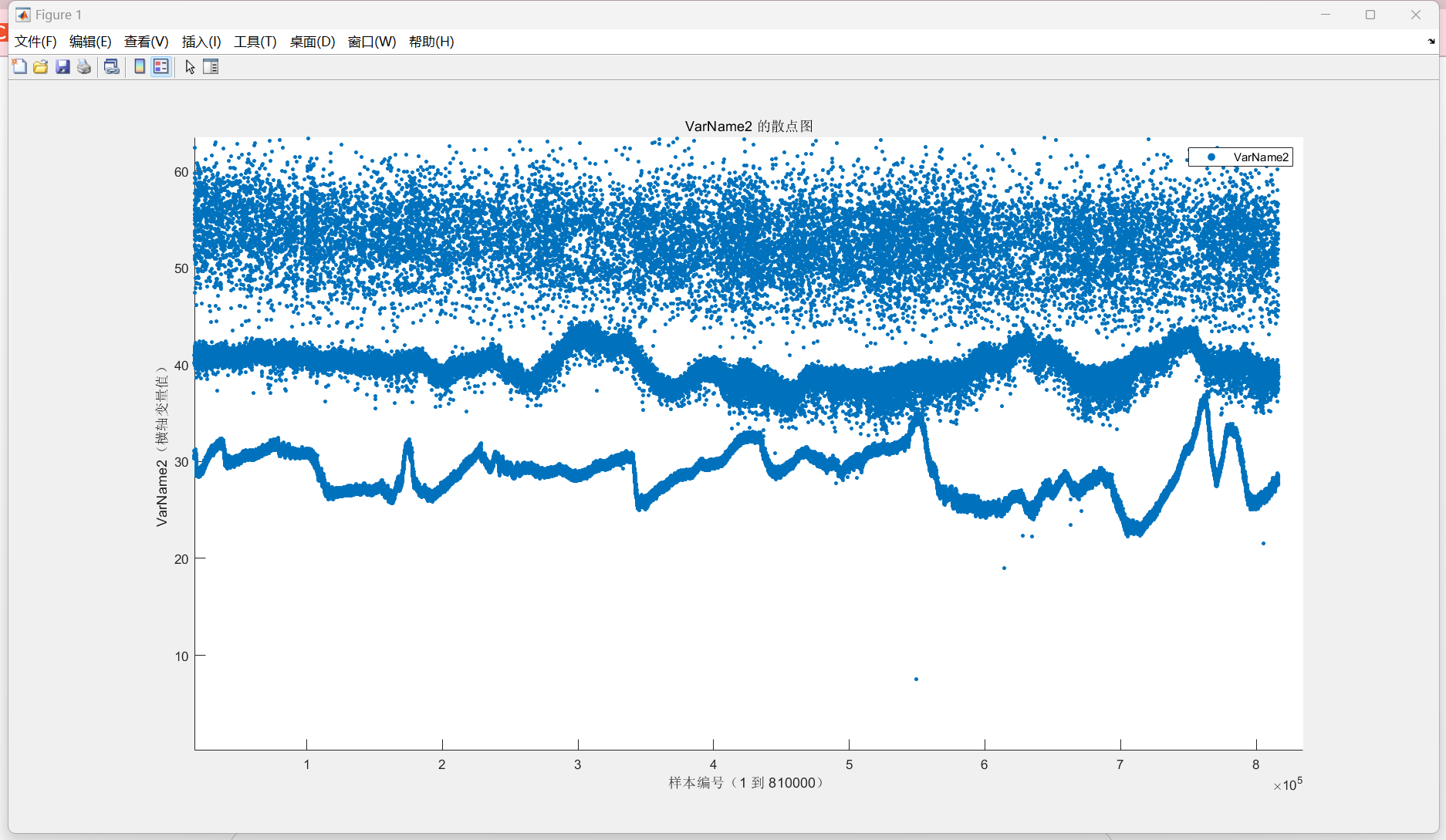
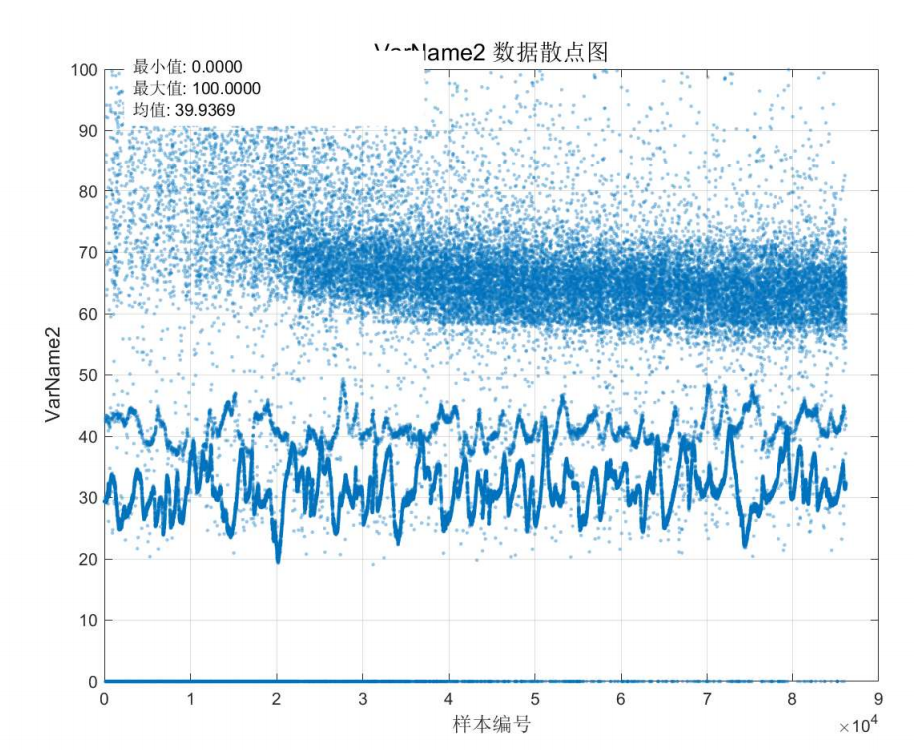
针对你描述的数据处理问题,这是一个典型的噪声干扰下的信号提取与异常值处理问题。你的目标是从大量噪声中提取出真实的床面高程变化趋势,并且需要对数据进行合理的清洗和建模。
一、问题分析
1. 数据分布特征
- 数据集中存在三个明显区域:
- 上层区域(72%):数据分散且均匀,是噪声数据。
- 中间区域(14%):为正常床面数据,符合预期范围(25~70cm)。
- 下层区域(14%):另一条平行的反射条带,可能是其他反射源或传感器误差。
- 离群点:散布在正常数据左右,可能来自传感器漂移、环境干扰等。
2. 现有方法的局限性
- 平均数/中位数:在噪声较多的情况下,无法准确反映真实数据的变化趋势。
- 直接“一刀切”:虽然可以去除上层噪声,但会丢失部分有用信息,且不能处理下层反射条带和离群点。
二、解决方案
1. 数据预处理:去除噪声与异常点
步骤一:可视化数据
- 使用 散点图 或 直方图 展示原始数据分布。
- 目的:直观识别不同区域的数据分布,辅助后续处理。
步骤二:使用统计方法筛选数据
- Z-score 标准化:
- 计算每个数据点的 Z-score,剔除 |Z| > 3 的数据点(通常认为超出3倍标准差的是异常值)。
- IQR 方法(四分位距法):
- 计算 Q1(25% 分位数)、Q3(75% 分位数),IQR = Q3 - Q1。
- 剔除低于 Q1 - 1.5×IQR 或高于 Q3 + 1.5×IQR 的数据点。
注意:这一步适用于初步去除离群点,但不能完全解决多区域噪声问题。
步骤三:基于阈值的区域划分
- 将数据分为几个区间(如 25~30cm, 30~35cm, ..., 65~70cm)。
- 计算每个区间的密度(即数据点数量 / 总数据量)。
- 保留密度较高的区间(例如 25~70cm 中的中间段)。
关键点:通过密度分析识别哪些区域是“真实数据”,哪些是“噪声”。
2. 模型拟合:逼近真实数据趋势
步骤一:滑动窗口均值滤波
- 对数据按时间序列进行滑动窗口平均,平滑噪声。
- 例如:取窗口大小为 10 秒(100 个点),计算每组的均值作为该时刻的估计值。
import numpy as np
def sliding_mean(data, window_size=10):
return np.convolve(data, np.ones(window_size)/window_size, mode='same')
步骤二:使用线性回归或非线性拟合
- 如果床面高程变化趋势是线性的,可使用线性回归。
- 如果是非线性,可用多项式拟合或样条插值。
from sklearn.linear_model import LinearRegression
# 假设 data 是一个一维数组,time 是时间索引
X = np.arange(len(data)).reshape(-1, 1)
y = data
model = LinearRegression()
model.fit(X, y)
predicted = model.predict(X)
步骤三:使用 Kalman 滤波(高级方法)
- 对于动态系统(如床面随时间变化),Kalman 滤波是一种递归滤波算法,能够融合观测数据和模型预测,提高精度。
3. 多区域数据分离(进阶)
步骤一:聚类分析(如 K-Means)
- 将数据按照数值进行聚类,找出代表真实数据的簇。
- 例如,将数据分为 3 类,选择中间那一类作为真实数据。
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(data.reshape(-1, 1))
labels = kmeans.labels_
centers = kmeans.cluster_centers_
步骤二:基于密度的聚类(DBSCAN)
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=2, min_samples=5)
dbscan.fit(data.reshape(-1, 1))
mask = (dbscan.labels_ != -1) # 去除噪声点
filtered_data = data[mask]
4. 反射条带数据的处理
步骤一:识别反射条带
- 如果反射条带具有固定高度(如比正常数据低 5cm),可以直接设置一个下限阈值,过滤掉低于该阈值的数据。
threshold = 20 # 假设反射条带低于 20cm
filtered_data = data[data > threshold]
步骤二:结合时间信息
- 如果反射条带是周期性出现的,可以结合时间戳进行过滤。
三、推荐学习资料
为了更好地掌握数据处理技术,以下是一些基础且全面的学习资源:
-
《Python for Data Analysis》 by Wes McKinney
- 学习 Pandas 和 NumPy,掌握基本的数据处理技能。
-
《Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow》
-
Coursera: "Data Science Specialization" by Johns Hopkins University
-
Kaggle Learn
- 提供免费的数据科学课程,包括数据清洗、特征工程等。
四、总结
| 步骤 | 方法 | 作用 |
|------|------|------|
| 1 | 可视化 | 识别数据分布 |
| 2 | Z-score/IQR | 去除离群点 |
| 3 | 阈值筛选 | 去除噪声区域 |
| 4 | 滑动窗口均值 | 平滑噪声 |
| 5 | 聚类分析 | 识别真实数据区域 |
| 6 | Kalman 滤波 | 动态数据优化 |
| 7 | 时间信息结合 | 过滤周期性反射条带 |
五、建议操作流程
- 先用直方图或散点图观察数据分布。
- 使用 IQR 或 Z-score 去除明显的离群点。
- 利用滑动窗口均值或 Kalman 滤波平滑数据。
- 使用聚类算法(如 K-Means 或 DBSCAN)识别真实数据区域。
- 结合时间信息,去除反射条带。
- 最终用线性/非线性拟合得到床面高程变化趋势。
如果你愿意提供部分数据样本,我可以帮你编写具体的代码来实现上述步骤,并给出更精准的处理方案。希望这些内容对你有帮助!如果还有疑问,欢迎继续提问。