晚上好🌙🌙🌙
本答案参考通义千问
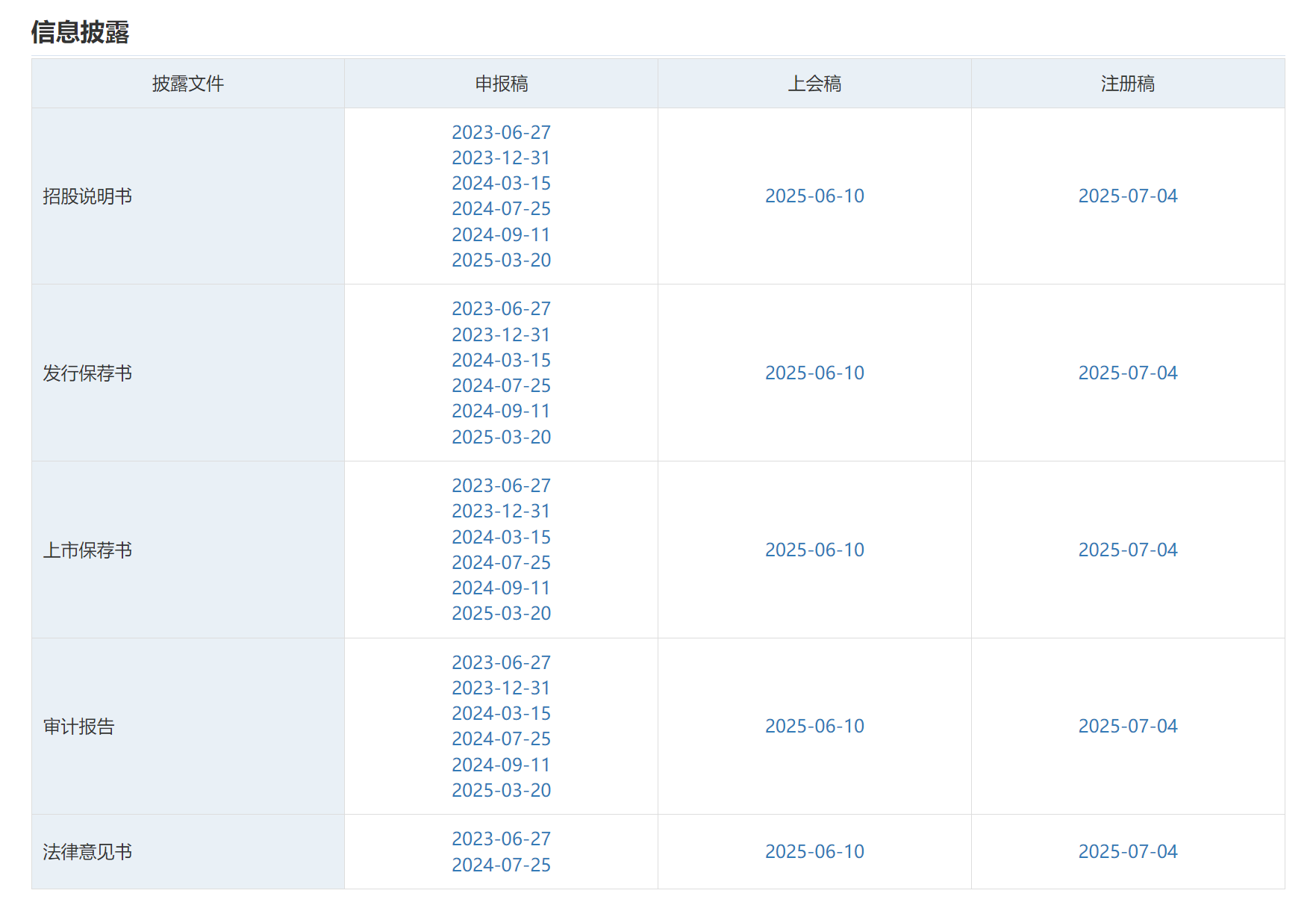
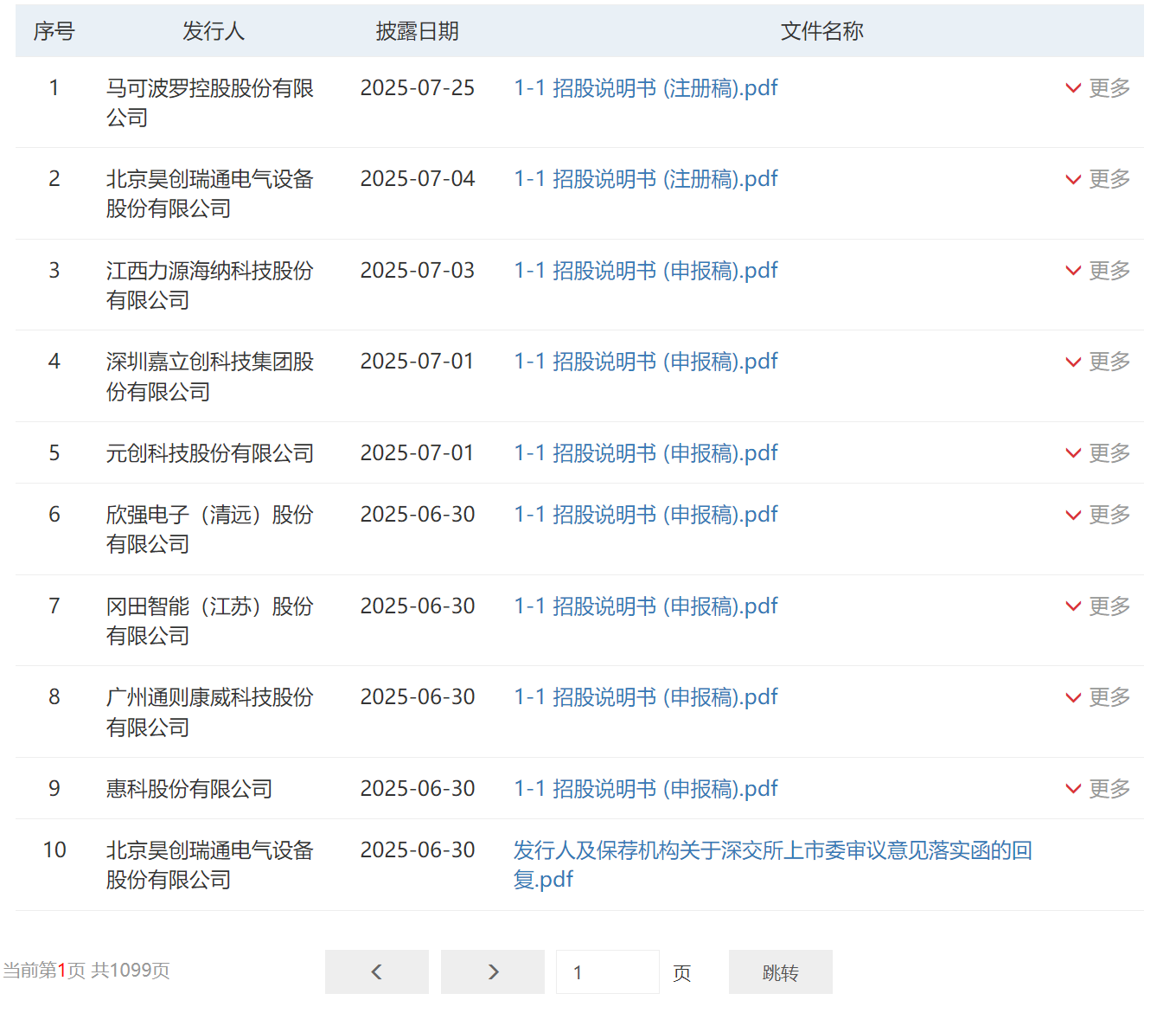
你提到的深圳证券交易所(深交所)的 IPO申报稿、上会稿、注册稿 等信息,是上市公司在上市过程中需要披露的重要文件。这些信息通常在 深交所官网 的以下两个页面中展示:
- IPO申报稿/上会稿/注册稿:
https://listing.szse.cn/disclosure/ipo/index.html - 项目动态IPO详情页:
https://listing.szse.cn/projectdynamic/ipo/detail/index.html?id=...
一、问题分析
1. 链接之间的关系
- IPO申报稿 是公司提交给监管机构的初步材料;
- 上会稿 是经过审核后准备上发审委会议的材料;
- 注册稿 是最终通过审核并完成注册的文件。
它们之间有时间顺序和逻辑关联,但没有直接的URL链接可以一键跳转。通常需要通过列表页面获取ID,再根据ID访问详情页来查看具体文件。
2. 爬取难点
- 深交所网站使用了反爬机制(如验证码、请求频率限制等);
- 部分页面使用JavaScript动态加载内容,无法直接通过静态HTML抓取;
- 文件可能以PDF形式存在,需提取PDF链接或下载PDF。
二、解决方案(步骤详解)
✅ 步骤 1:分析目标网页结构
1.1 IPO申报稿页面
网址:https://listing.szse.cn/disclosure/ipo/index.html
- 使用浏览器开发者工具(F12)查看页面元素,找到申报稿列表的结构。
- 通常包含字段:公司名称、申报日期、状态(如“已受理”、“已反馈”等)、ID(用于访问详情页)。
1.2 项目动态IPO详情页
网址:https://listing.szse.cn/projectdynamic/ipo/detail/index.html?id=...
✅ 步骤 2:确定数据来源与接口(可选)
如果网页是通过 AJAX 请求加载数据,你可以尝试通过浏览器开发者工具的 Network 面板查找 API 接口,例如:
GET https://listing.szse.cn/api/ipo/list?page=1&size=10
- 该接口可能返回 JSON 格式的数据,包含所有 IOP 项目的 ID、名称、状态等信息。
✅ 步骤 3:编写 Python 爬虫代码(示例)
下面是一个基本的 Python + requests + BeautifulSoup 示例代码,用于爬取 IPO 申报稿列表,并提取其中的 ID 和 PDF 下载链接。
⚠️ 注意:此代码仅用于学习目的,请遵守网站的 robots.txt 和相关法律法规。
import requests
from bs4 import BeautifulSoup
import time
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
def get_ipo_list():
url = 'https://listing.szse.cn/disclosure/ipo/index.html'
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
# 假设申报稿列表在 <table class="table"> 中
table = soup.find('table', {'class': 'table'})
rows = table.find_all('tr')[1:] # 跳过表头
for row in rows:
tds = row.find_all('td')
company_name = tds[0].text.strip()
status = tds[1].text.strip()
id_link = tds[2].find('a')['href'] # 获取详情页链接
# 提取ID
detail_id = id_link.split('id=')[1].split('&')[0]
print(f"公司名称: {company_name}, 状态: {status}, ID: {detail_id}")
# 访问详情页
detail_url = f'https://listing.szse.cn/projectdynamic/ipo/detail/index.html?id={detail_id}'
detail_response = requests.get(detail_url, headers=headers)
detail_soup = BeautifulSoup(detail_response.text, 'lxml')
# 查找PDF链接
pdf_link = detail_soup.find('a', {'class': 'download-btn'})['href']
print(f"PDF下载链接: https://listing.szse.cn{pdf_link}\n")
time.sleep(1) # 避免频繁请求被封IP
if __name__ == '__main__':
get_ipo_list()
✅ 步骤 4:处理反爬机制
4.1 使用代理 IP
如果被封 IP,可以使用代理服务(如 快代理、芝麻代理):
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
response = requests.get(url, headers=headers, proxies=proxies)
4.2 设置请求间隔
time.sleep(2) # 每次请求间隔2秒
4.3 处理 JavaScript 渲染
如果页面内容由 JS 动态加载,可以考虑使用 Selenium 或 Playwright:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://listing.szse.cn/disclosure/ipo/index.html")
# 等待JS渲染完成
time.sleep(5)
# 提取内容...
✅ 步骤 5:保存数据(可选)
你可以将爬取的数据保存为 CSV 或 Excel 文件:
import pandas as pd
data = []
for row in rows:
# ...提取数据...
data.append([company_name, status, detail_id, pdf_link])
df = pd.DataFrame(data, columns=['公司名称', '状态', 'ID', 'PDF链接'])
df.to_csv('ipo_data.csv', index=False, encoding='utf-8-sig')
三、注意事项
- 遵守法律和网站规则:请确保你的行为符合《中华人民共和国网络安全法》及网站的《用户协议》。
- 避免高频请求:不要短时间内大量请求,以免被封IP。
- 建议使用合法方式获取数据:如需大规模数据,可联系深交所官方获取授权接口。
四、总结
| 步骤 | 内容 |
|------|------|
| 1 | 分析目标网页结构 |
| 2 | 确定数据来源与接口 |
| 3 | 编写 Python 爬虫代码 |
| 4 | 处理反爬机制(代理、延迟等) |
| 5 | 保存数据 |
如果你希望我帮你进一步优化代码,或者针对某个特定页面进行解析,请提供更具体的网页源码或截图,我可以帮助你定制化代码。
如有其他问题,欢迎继续提问!