让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
- 关键点分析:
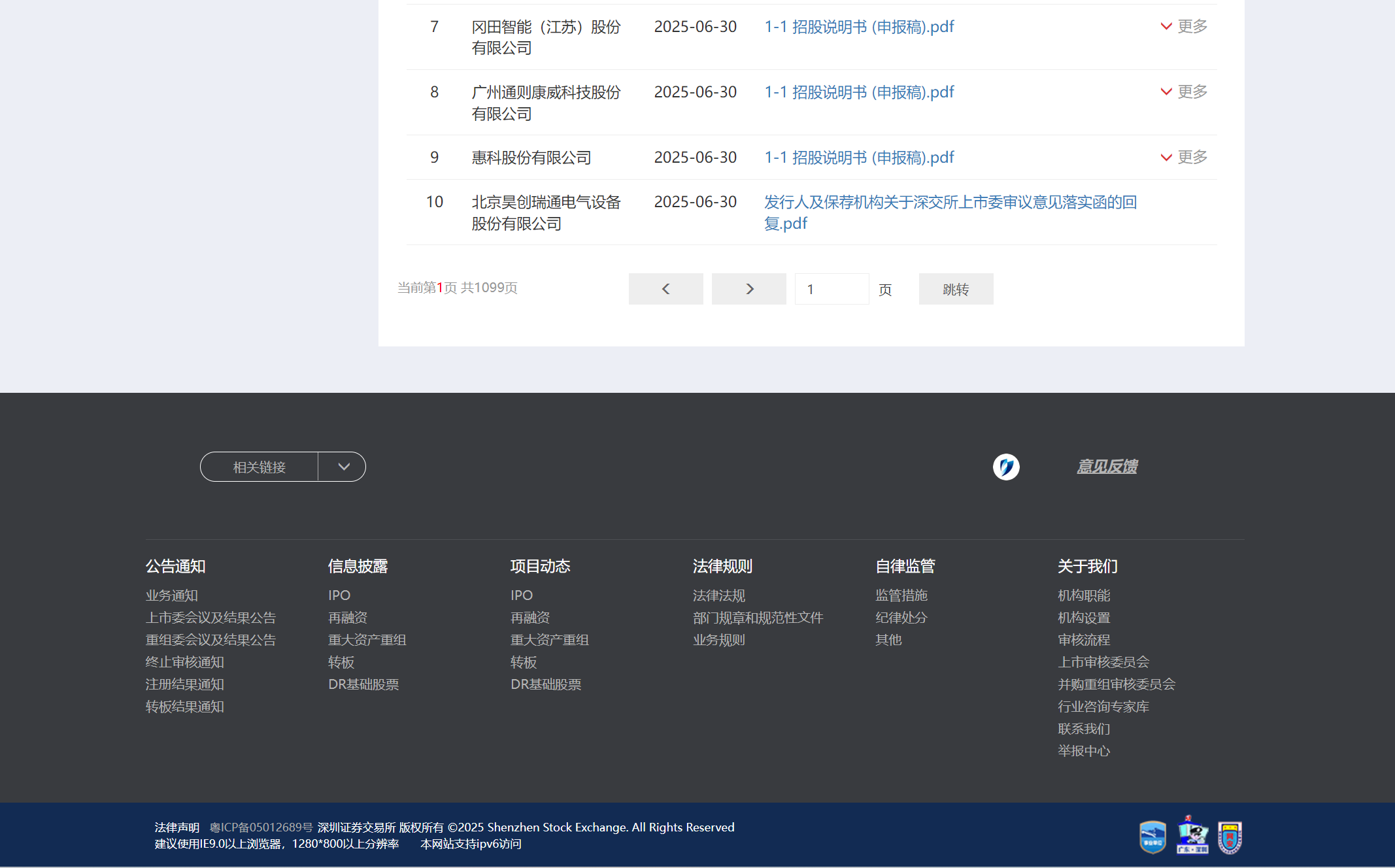
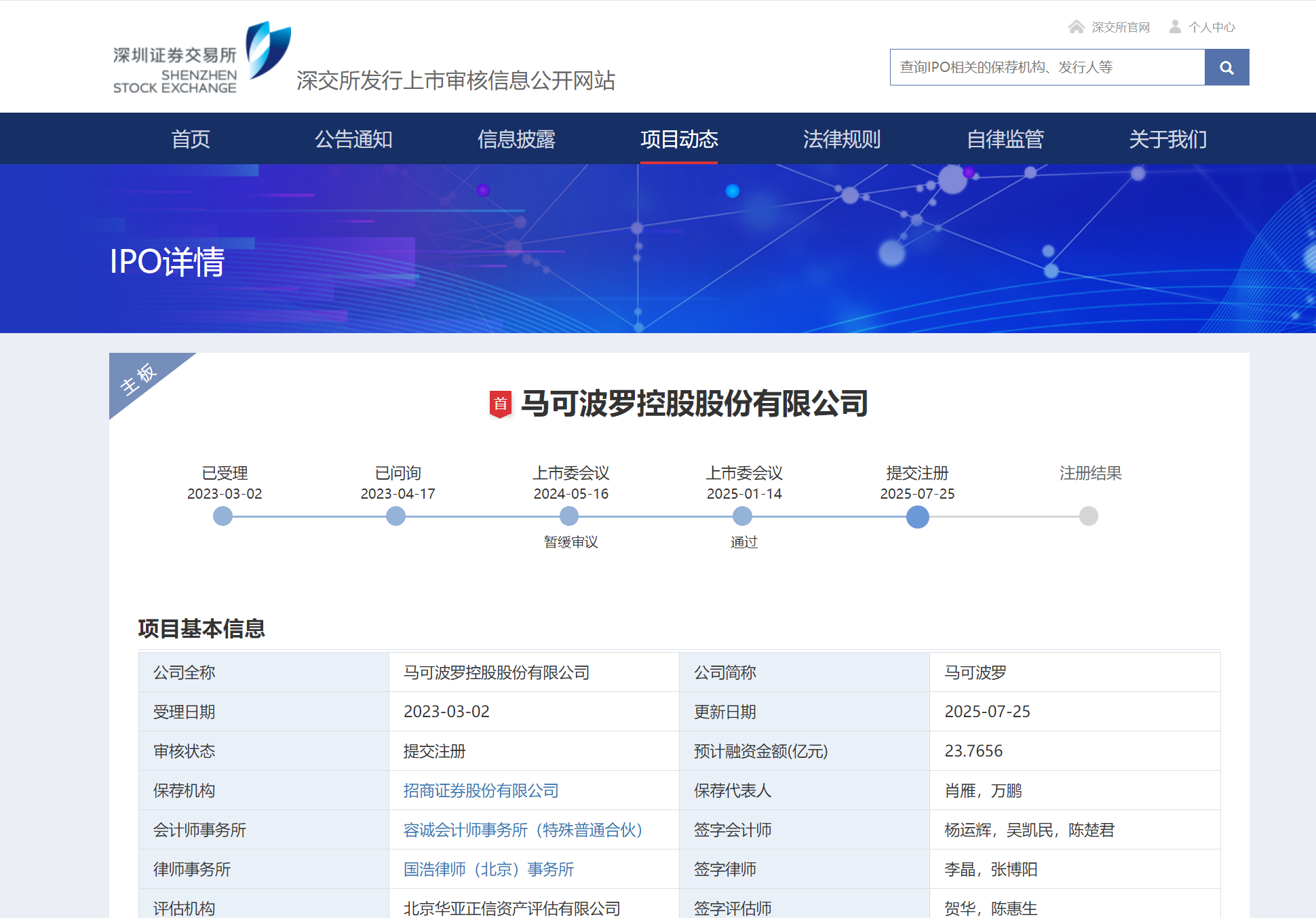
- 目标网站是深交所发行上市审核信息公开网站,需要绕过反爬虫机制。
- 要准确提取各个公司的项目基本信息和招股说明书稿件链接及内容。
- 不同页面的结构和数据提取方式需要仔细分析。 - 解决方案:
- 可以使用Python的requests库来发送HTTP请求获取网页内容,BeautifulSoup库来解析HTML。
- 示例代码如下:
import requests
from bs4 import BeautifulSoup
def get_company_info(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 提取项目基本信息
basic_info = soup.find_all('div', class_='info-item')
for info in basic_info:
title = info.find('span', class_='info-title').text.strip()
value = info.find('span', class_='info-value').text.strip()
print(f"{title}: {value}")
# 提取招股说明书链接
prospectus_link = soup.find('a', text='招股说明书')
if prospectus_link:
prospectus_url = 'http://listing.szse.cn' + prospectus_link['href']
get_prospectus_content(prospectus_url)
def get_prospectus_content(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
content = soup.find('div', class_='document-content').text
print(content)
base_url = 'http://listing.szse.cn/disclosure/ipo/index.html'
response = requests.get(base_url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
company_links = soup.find_all('a', class_='tab-2-item')
for link in company_links:
company_url = 'http://listing.szse.cn' + link['href']
get_company_info(company_url)
- 多种解决方案优缺点:
- 使用requests和BeautifulSoup:- 优点:简单易用,适合初学者,能快速实现基本的网页爬取和解析。
- 缺点:对于复杂的动态网页和反爬虫机制处理能力有限。
- 使用
Scrapy框架: - 优点:功能强大,支持异步请求、中间件处理反爬虫等,效率较高。
- 缺点:学习成本相对较高,代码结构相对复杂。
- 总结:
- 首先通过分析目标网站的HTML结构,利用requests库获取网页内容,再用BeautifulSoup库提取所需信息。对于招股说明书的内容提取,先获取链接再进一步获取内容。不同的爬取方案各有优缺点,可以根据具体需求和项目情况选择合适的方法。
需要注意的是,在爬取网站数据时要确保遵守相关法律法规和网站的使用条款,避免过度爬取造成不良影响。
希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。