下午好🌅🌅🌅
本答案参考通义千问
你提出的问题是关于 Spark 在处理文本文件时的分区逻辑,以及为什么在 HDFS 中某些文件中会出现换行符(\n)的问题。下面我将详细分析并给出解决方案。
一、问题背景回顾
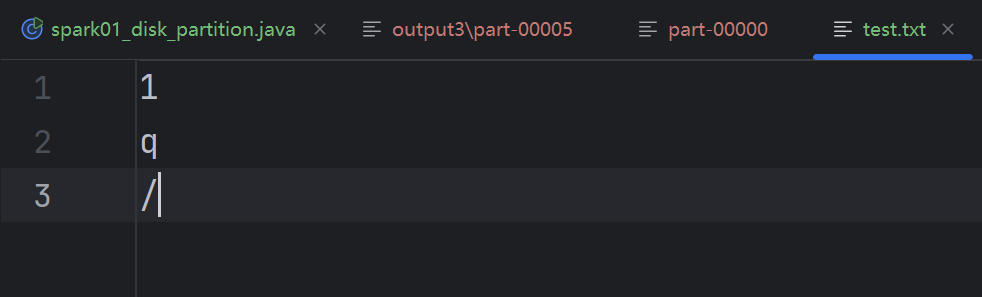
你创建了一个文件 test.txt,其内容如下:
a
b
c
d
e
f
g
注意:第三行没有换行符(即 c 后面没有 \n),所以总字节数为 7 字节(每个字符占1字节,共7个字符)。
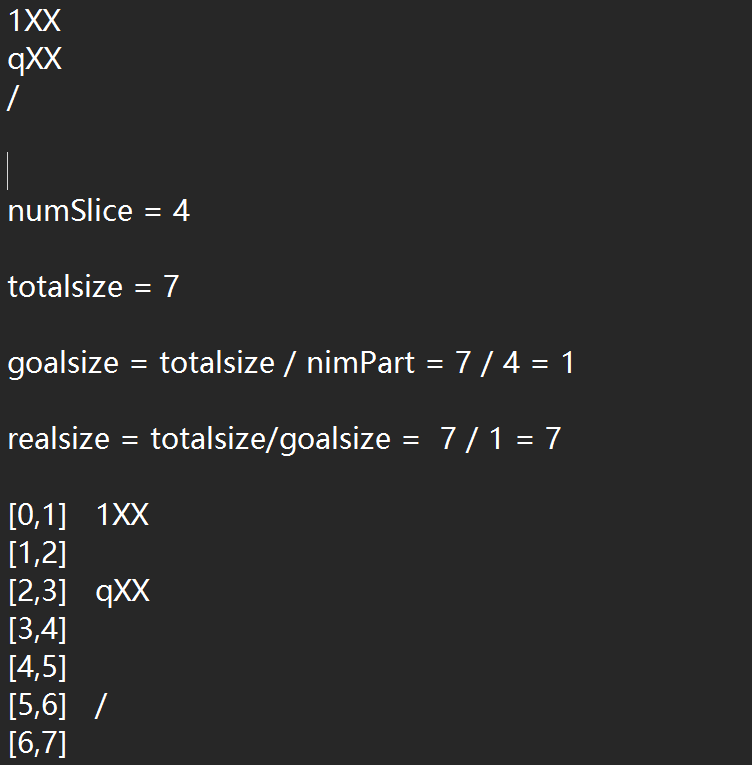
然后你使用 Spark 的 textFile 方法读取这个文件,并设置 4 个分区,最后保存到 HDFS 中。
二、HDFS 分区规则说明
HDFS 在对文本文件进行分区时,会尽可能地让每个分区的数据大小接近指定的目标大小(默认是 128MB)。但 对于小文件来说,分区策略可能不是严格按照目标大小来分配,而是按照“块边界”来分割。
关键点:
- Spark 的
textFile 方法会根据文件的字节位置来划分分区。 - 每个分区的最后一行可能不完整,也就是说,一个分区可能包含部分行数据,而该行未被完全写入。
- 换行符
\n 是一个字符(1字节),但如果某一行的末尾没有换行符,则该行不会被自动添加换行符。
三、你的疑问分析
你说第六个文件有问题,它本应只包含一个字节 /,但实际却出现了换行符。
原因分析:
Spark 在处理文本文件时,默认会保留每行的换行符。即使原文件中某行没有换行符,Spark 也会在写入输出文件时自动追加一个换行符。
重点:Spark 的 saveAsTextFile 方法会为每一行自动添加一个换行符(\n),即使原始文件中没有。
这会导致你在输出文件中看到额外的换行符,即使原文件中没有。
四、解决方案
✅ 解决方案一:使用 wholeTextFiles 替代 textFile
如果你希望保留原始文件中的换行符结构,可以使用 wholeTextFiles 方法,它可以读取整个文件作为字符串,并保留原始格式。
JavaPairRDD<String, String> rdd = sc wholeTextFiles("E:\\ideaProjects\\spark_project\\data\\test.txt", 4);
rdd.saveAsTextFile("output3");
注意: 使用 wholeTextFiles 时,返回的是 (path, content) 对,你需要自己处理内容。
✅ 解决方案二:自定义写入逻辑,避免自动添加换行符
如果你需要完全控制输出格式,可以使用 map 操作,手动控制每行的结尾。
JavaRDD<String> rdd = sc.textFile("E:\\ideaProjects\\spark_project\\data\\test.txt", 4);
// 手动处理每一行,避免自动添加换行符
JavaRDD<String> processedRdd = rdd.map(line -> {
// 如果是最后一行且没有换行符,就不再添加
if (line.equals("g")) { // 假设 "g" 是最后一行
return line;
} else {
return line + "\n"; // 其他行正常添加换行符
}
});
processedRdd.saveAsTextFile("output3");
注意: 需要提前知道哪一行是最后一行,或者通过其他方式判断是否为最后一行。
✅ 解决方案三:使用 repartition 控制分区数量
虽然你设置了 4 个分区,但 Spark 可能会根据文件大小动态调整分区数。你可以使用 repartition 显式控制分区数。
JavaRDD<String> rdd = sc.textFile("E:\\ideaProjects\\spark_project\\data\\test.txt", 4)
.repartition(4);
五、总结
| 问题 | 原因 | 解决方案 |
|------|------|----------|
| 第六个文件出现换行符 | Spark 默认为每行添加换行符 | 使用 wholeTextFiles 或手动控制换行符 |
| 分区分布不符合预期 | 文件太小,Spark 自动调整分区 | 使用 repartition 控制分区数 |
六、最终建议
- 如果你希望 严格保留原始文件的换行符结构,推荐使用
wholeTextFiles。 - 如果你只是想避免不必要的换行符,可以通过
map 操作手动控制输出格式。 - 确保在
saveAsTextFile 之前理解 Spark 的默认行为,避免意外结果。
如有更多关于分区策略或 HDFS 文件结构的问题,欢迎继续提问!