sqlalchemy.exc.ArgumentError: Mapper mapped class News->news could not assemble any primary key columns for mapped table 'news'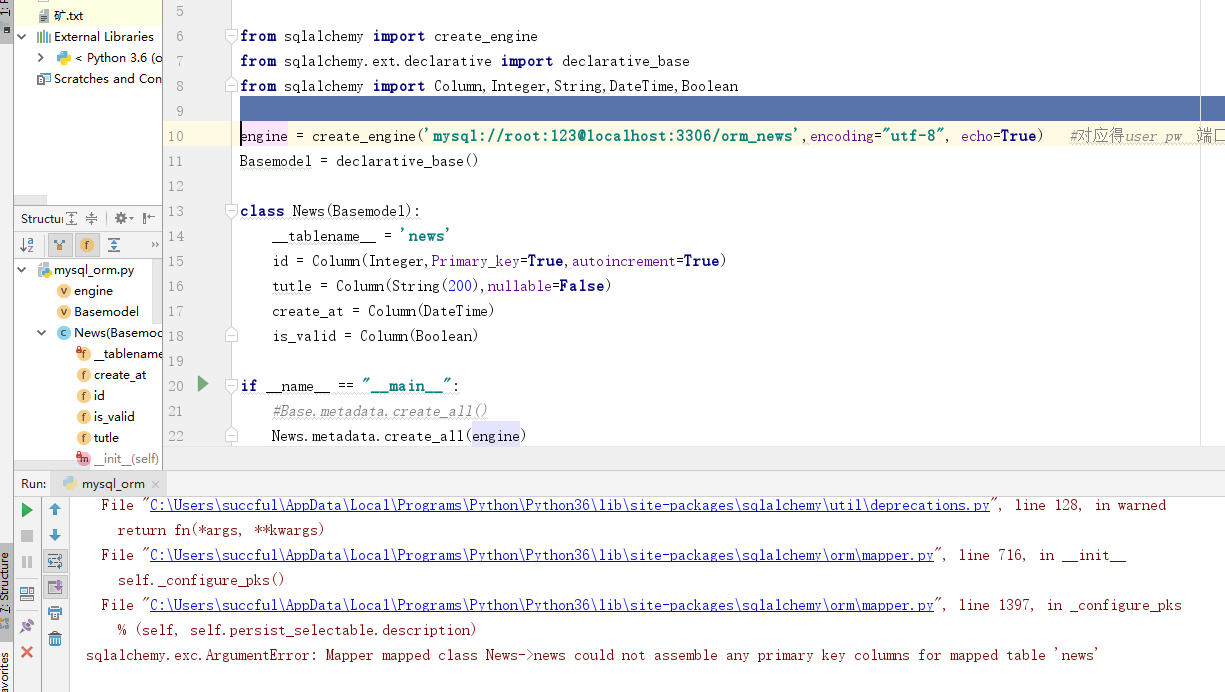

使用sqlalchemy,映射操作失败,请帮忙解答下。

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

- 2020-09-08 23:07SQLAlchemy 是 Python 中一个强大的 SQL 工具包和 ORM(对象关系映射)库,它允许开发者使用 Python 类定义数据库模式,并与 MySQL 这样的关系型数据库进行交互。ORM 提供了面向对象的方式来操作数据库,使得数据库...
- 2024-11-23 12:38SQLAlchemy是Python中一个功能强大且广泛使用的库,用于数据库操作。它提供了多种方式与数据库交互,包括创建表、查询、插入、更新和删除数据。通过本文的介绍,读者应该能够掌握SQLAlchemy的基本概念、功能、安装...
- 2020-09-21 15:49在Python的Web开发领域,Django是一个非常流行的框架,它内置了ORM(对象关系映射)系统,使得开发者可以方便地进行数据库操作。然而,对于一些需要更灵活、更底层控制的场景,Django的ORM可能无法满足需求,此时就...
- 2020-09-19 13:19### Python使用sqlalchemy模块连接数据库操作详解 #### 一、SQLAlchemy简介 SQLAlchemy是一个Python SQL工具包和ORM(对象关系映射),它提供了一整套全面的企业级持久化模式功能,包括活跃记录模式、数据映射器...
- 2021-01-20 04:49当然现代的SQLAlchemy(新版本SQLAlchemy,原文是modern SQLAlchemy)使用Declarative把这两件事一起做了,即允许我们把创建类和描述定义数据库表以及它们之间的映射关系一次搞定。 这段话是什么意思呢?简单来说吧...
- 2020-09-19 08:30Sqlalchemy是Python中最流行的ORM框架之一,它提供了一套强大的API用于数据库操作。这篇教程将详细介绍如何安装和使用sqlalchemy。 首先,安装sqlalchemy非常简单。在命令行中,你可以使用pip来安装,如在虚拟环境...
- 2020-09-19 14:51### Python 数据库操作 SQLAlchemy 的知识点概述 #### 一、数据库操作的重要性及背景 数据库操作是软件开发中的核心技能之一,特别是在需要持久化存储数据的应用场景下尤为重要。在现代软件架构中,应用程序通常...
- 2023-11-12 17:14徐州蔡徐坤的博客 Python使用SQLAlchemy操作sqlite: sqllite的介绍和常用的sql语句, python使用SQLAlchemy集成sqlite
- 2020-09-22 04:34这正是ORM映射关系的精髓所在,它隐藏了底层的数据库细节,使开发者可以使用Python对象的属性和方法来操作数据,而无需编写复杂的SQL语句。 关于外键的小知识部分提到了几点: 1. FOREIGN KEY约束通常链接到主键列...
- 2026-01-06 15:40SQLAlchemy是Python编程语言中一个流行的SQL工具包和对象关系映射(ORM)库,提供了丰富的数据库操作接口,允许开发人员使用Python编程来管理和操作数据库数据,以面向对象的方式进行数据库编程。 在数据库编程中,...
- 没有解决我的问题, 去提问

