
大神帮忙看一下
今天使用htmlunit+jsoup爬取知乎网站的视频,发现爬取到的html中缺少视频的信息,无法进行下一步了
知乎视频网址:https://video.zhihu.com/video/1157743087110549504?autoplay=false&useMSE=
浏览器检查中查看到的视频信息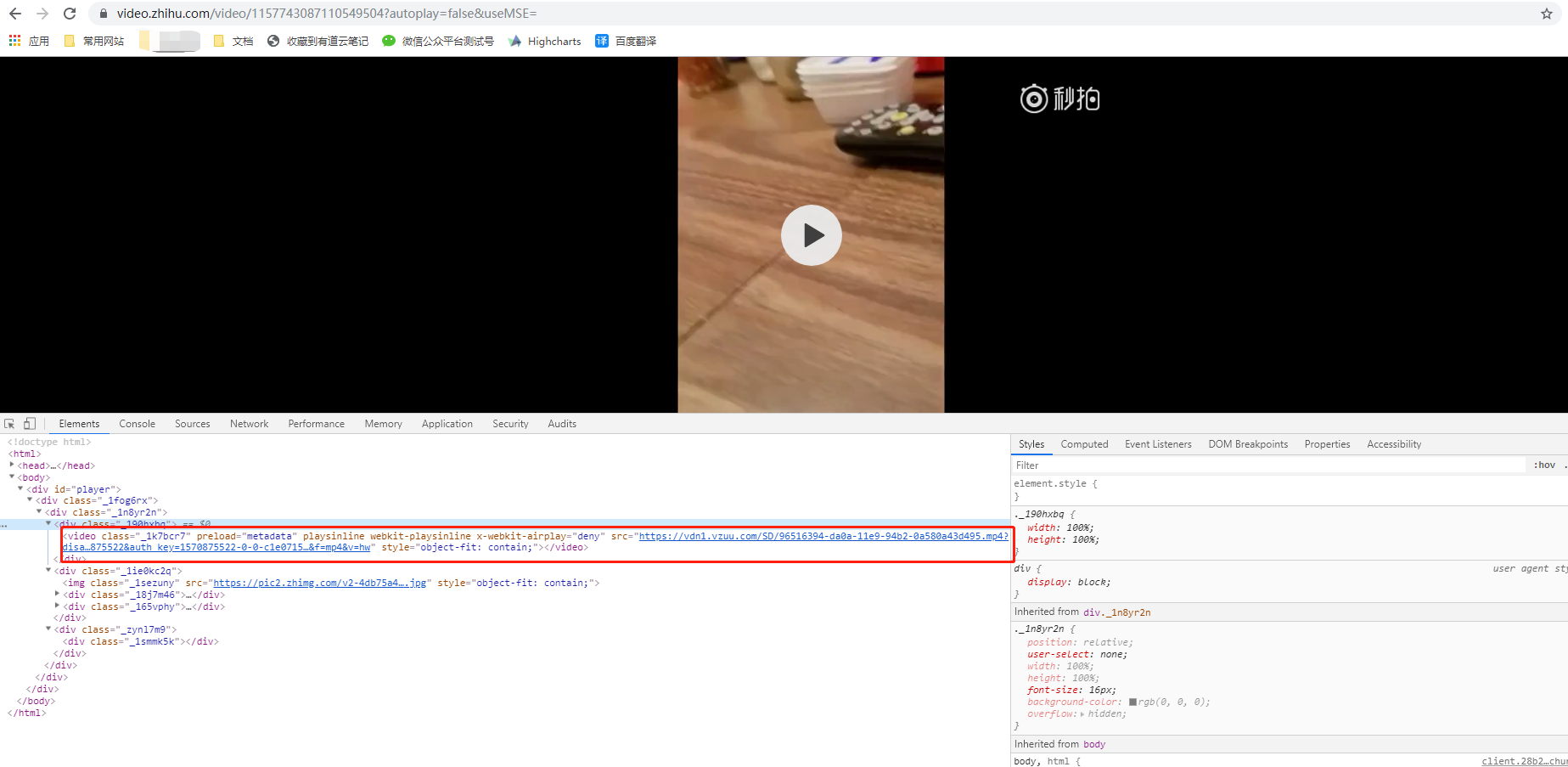
java代码
@Test
public void testttt() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);//新建一个模拟谷歌Chrome浏览器的浏览器客户端对象
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常, 这里选择不需要
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常, 这里选择不需要
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);//是否启用CSS, 因为不需要展现页面, 所以不需要启用
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
HtmlPage page = null;
try {
page = webClient.getPage("https://video.zhihu.com/video/1157743087110549504?autoplay=false&useMSE=");//尝试加载上面图片例子给出的网页
// page = webClient.getPage("http://ent.sina.com.cn/film/");//尝试加载上面图片例子给出的网页
} catch (Exception e) {
e.printStackTrace();
}finally {
webClient.close();
}
webClient.waitForBackgroundJavaScript(30000000);//异步JS执行需要耗时,所以这里线程要阻塞30秒,等待异步JS执行结束
String pageXml = page.asXml();//直接将加载完成的页面转换成xml格式的字符串
System.out.println(pageXml);
//TODO 下面的代码就是对字符串的操作了,常规的爬虫操作,用到了比较好用的Jsoup库
// Document document = Jsoup.parse(pageXml);//获取html文档
// List<Element> infoListEle = document.getElementById("feedCardContent").getElementsByAttributeValue("class", "feed-card-item");//获取元素节点等
// infoListEle.forEach(element -> {
// System.out.println(element.getElementsByTag("h2").first().getElementsByTag("a").text());
// System.out.println(element.getElementsByTag("h2").first().getElementsByTag("a").attr("href"));
// });
}
运行程序打印的html如下: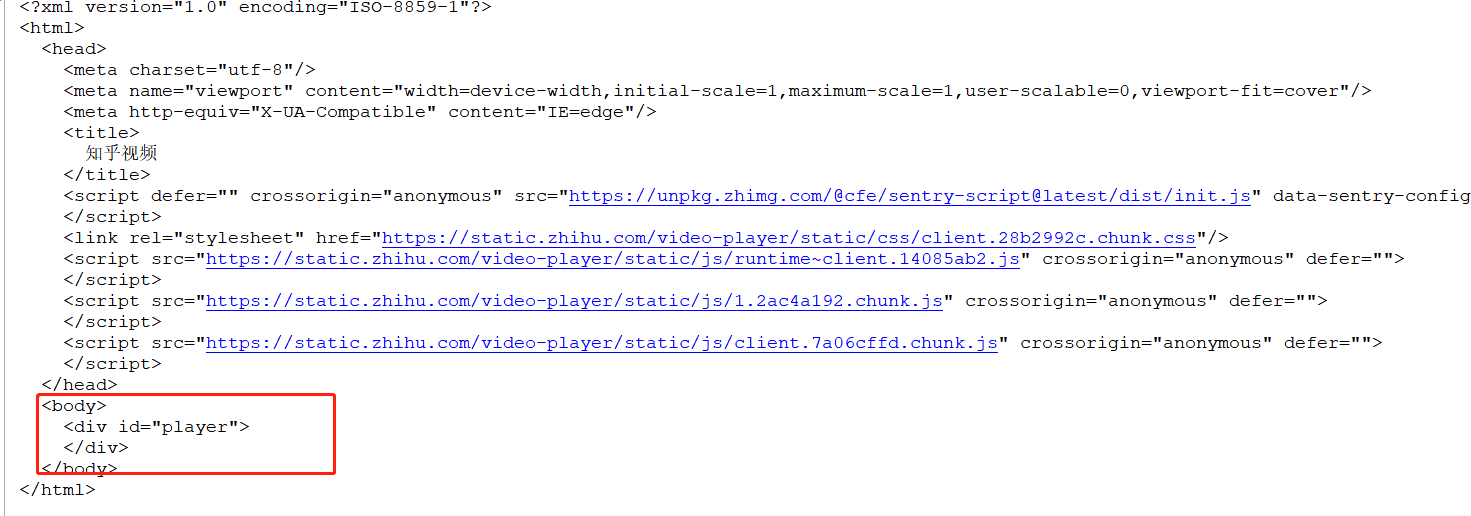
有大神遇到过这个问题吗?帮忙看一下




