我利用keras的神经网络训练一个模型,被训练的数据是一个很大的二维数组,每一行是一个类别,总共有3种类别。被训练出的模型中包括3种类别(暂且称为A,B,C)。现在B类的预测准确率太高了,而A和C类的预测准确率较低,我想在把B类准确率适当减低的情况下来提高A和C类的预测准确率。请问该怎么操作?
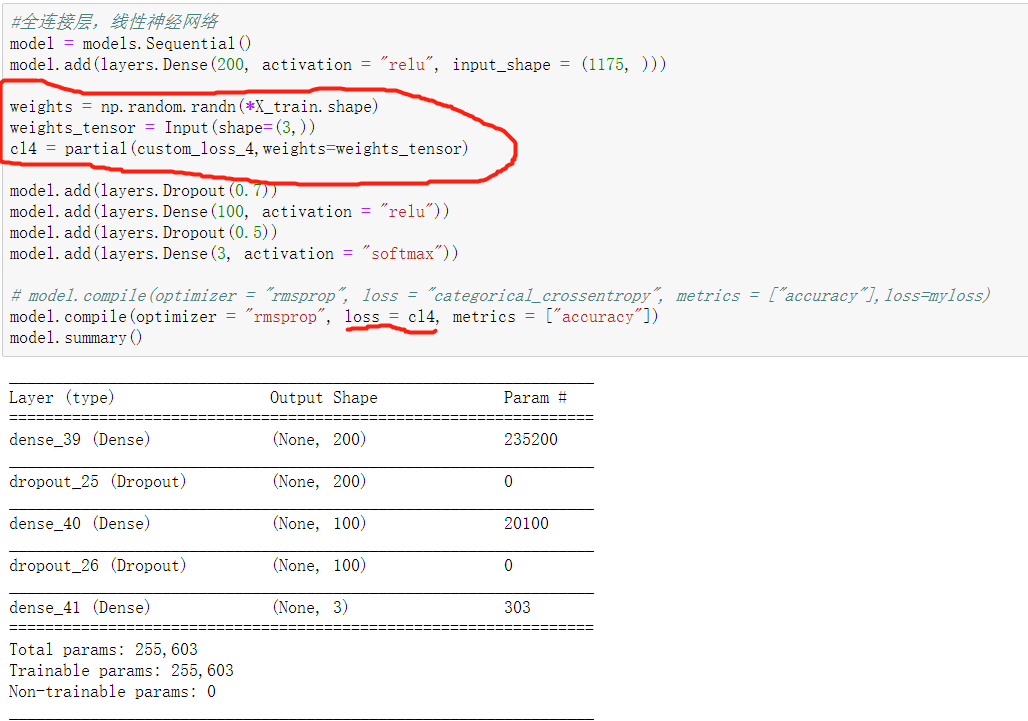
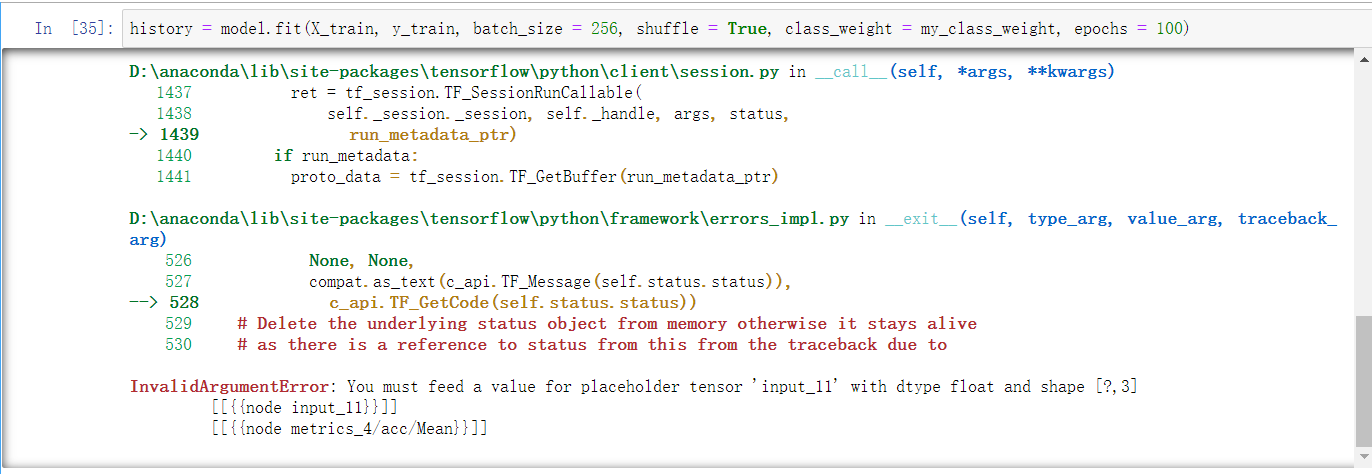
代码如下,我从网上查了一些代码,自己不是特别明白,尝试后,出现了错误。请问该如何修改?下面添加的图片中被划红线圈住的代码是添加上去的,最终运行出错了,请问怎么修改,或者重新帮我写一个权重损失代码代码,跪谢
def custom_loss_4(y_true, y_pred, weights):
return K.mean(K.abs(y_true - y_pred) * weights)
model = models.Sequential()
model.add(layers.Dense(200, activation = "relu", input_shape = (1175, )))
weights = np.random.randn(*X_train.shape)
weights_tensor = Input(shape=(3,))
cl4 = partial(custom_loss_4,weights=weights_tensor)
model.add(layers.Dropout(0.7))
model.add(layers.Dense(100, activation = "relu"))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(3, activation = "softmax"))
model.compile(optimizer = "rmsprop", loss = cl4, metrics = ["accuracy"])
model.summary()
补充一下:我在前面对数据做过了不平衡调整,定义的函数如下:
def calc_class_weight(total_y):
my_class_weight = class_weight.compute_class_weight("balanced", np.unique(total_y), total_y)
return my_class_weight

python如何自定义权重损失函数?

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答
 蔡能教授,网站特聘专家 2019-10-13 16:19关注
蔡能教授,网站特聘专家 2019-10-13 16:19关注from keras.layers import Input,Embedding,LSTM,Dense,Lambda
from keras.layers.merge import dot
from keras.models import Model
from keras import backend as Kword_size = 128
nb_features = 10000
nb_classes = 10
encode_size = 64
margin = 0.1embedding = Embedding(nb_features,word_size)
lstm_encoder = LSTM(encode_size)def encode(input):
return lstm_encoder(embedding(input))q_input = Input(shape=(None,))
a_right = Input(shape=(None,))
a_wrong = Input(shape=(None,))
q_encoded = encode(q_input)
a_right_encoded = encode(a_right)
a_wrong_encoded = encode(a_wrong)q_encoded = Dense(encode_size)(q_encoded) #一般的做法是,直接讲问题和答案用同样的方法encode成向量后直接匹配,但我认为这是不合理的,我认为至少经过某个变换。
right_cos = dot([q_encoded,a_right_encoded], -1, normalize=True)
wrong_cos = dot([q_encoded,a_wrong_encoded], -1, normalize=True)loss = Lambda(lambda x: K.relu(margin+x[0]-x[1]))([wrong_cos,right_cos])
model_train = Model(inputs=[q_input,a_right,a_wrong], outputs=loss)
model_q_encoder = Model(inputs=q_input, outputs=q_encoded)
model_a_encoder = Model(inputs=a_right, outputs=a_right_encoded)model_train.compile(optimizer='adam', loss=lambda y_true,y_pred: y_pred)
model_q_encoder.compile(optimizer='adam', loss='mse')
model_a_encoder.compile(optimizer='adam', loss='mse')model_train.fit([q,a1,a2], y, epochs=10)
#其中q,a1,a2分别是问题、正确答案、错误答案的batch,y是任意形状为(len(q),1)的矩阵解决 无用评论 打赏举报 分享
- 2022-02-28 14:56回答 3 已采纳 把menu函数放在main函数的上面。
- 2022-05-06 16:11回答 4 已采纳 age 是占位的可缺省参数,要使用缺省值,只有参数为1个时才行,只要参数是2个,又没有用命名参数调用的方式,默认就依位置,所以现在的调用中,'zhangsan'是形参name的实际值,13是形参age
- 2022-02-12 16:34回答 7 已采纳 主要是eval这块,如果输入的不是可以计算的数就会报错,所以在函数try里eval,异常就跳过再往后判断(有忽略异常的感觉) ```python def isNum(s): try
- 2022-03-15 18:46AI强仔的博客 catboost自定义损失函数和eval_metric
- 2022-04-26 00:08回答 1 已采纳 可以用isinstance函数检查数据类型 >>>a=[1,2,3,4.1] >>>isinstance(a,list) True >>>isin
- 2021-06-14 23:59回答 2 已采纳 代码如下:{如果对你有帮助,可以给我个采纳吗,谢谢!! 点击我这个回答右上方的【采纳】按钮}。 def my_replace(s,m,n): l = len(m) i = 0
- 2022-04-30 14:00回答 1 已采纳 def dna(s): ans = "" for i in s: if i == "A": ans += "T" elif i
- 2021-05-20 00:06数据派THU的博客 作者:Arjun Sarkar翻译:陈之炎校对:欧阳锦本文约1900字,建议阅读8分钟本文带你学习使用Python中的wrapper函数和OOP来编写自定义损失函数。 标签:...
- 2023-04-07 19:42回答 3 已采纳 循环遍历字符串,然后判断当前字符是否是数字字符 def num_isdigit(string): if string == '': return False else:
- 2022-11-19 22:56回答 1 已采纳 你打引号干嘛
- 2021-12-04 01:29回答 1 已采纳 Python中对于切片的操作是用英文冒号':'来实现的,因此应为s2[i:i + length]。
- 2022-06-22 16:06Kevin Davis的博客 【pytorch笔记】(五)自定义损失函数、学习率衰减、模型微调。
- 2020-01-29 12:38其实可以叫我小徐的博客 目录问题背景:二分类损失LogLoss公式推导代码实现多分类损失MultiLoss公式推导代码实现自定义Loss注意事项结语新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段...
- 2018-10-17 14:52weixin_30877755的博客 验证损失:自定义LightGBM中的验证损失需要定义一个函数,该函数接受相同的两个数组,但返回三个值:一个字符串,其名称为metric的字符串,损失本身,以及关于更高是否更好的布尔值。 用于在LightGBM中...
- 2022-08-06 08:21kakaccys的博客 损失函数是是用来估量你模型的预测值f(x)与真实值Y的不一致程度。不同的损失函数对模型拟合会有不同的效果,损失...在这里我们使用MNIST作为我们的数据集,并使用paddle内置的lenet进行训练,验证自定义损失函数。...
- 没有解决我的问题, 去提问


悬赏问题
- ¥188 寻找能做王者评分提取的
- ¥15 matlab用simulink求解一个二阶微分方程,要求截图
- ¥30 matlab解优化问题代码
- ¥15 写论文,需要数据支撑
- ¥15 identifier of an instance of 类 was altered from xx to xx错误
- ¥100 反编译微信小游戏求指导
- ¥15 docker模式webrtc-streamer 无法播放公网rtsp
- ¥15 学不会递归,理解不了汉诺塔参数变化
- ¥15 基于图神经网络的COVID-19药物筛选研究
- ¥30 软件自定义无线电该怎样使用