python+selenium 关于取淘宝商品页面某个商品的XPath,显式等待一直报错,XPath取a标签、div、img都运行失败,求解
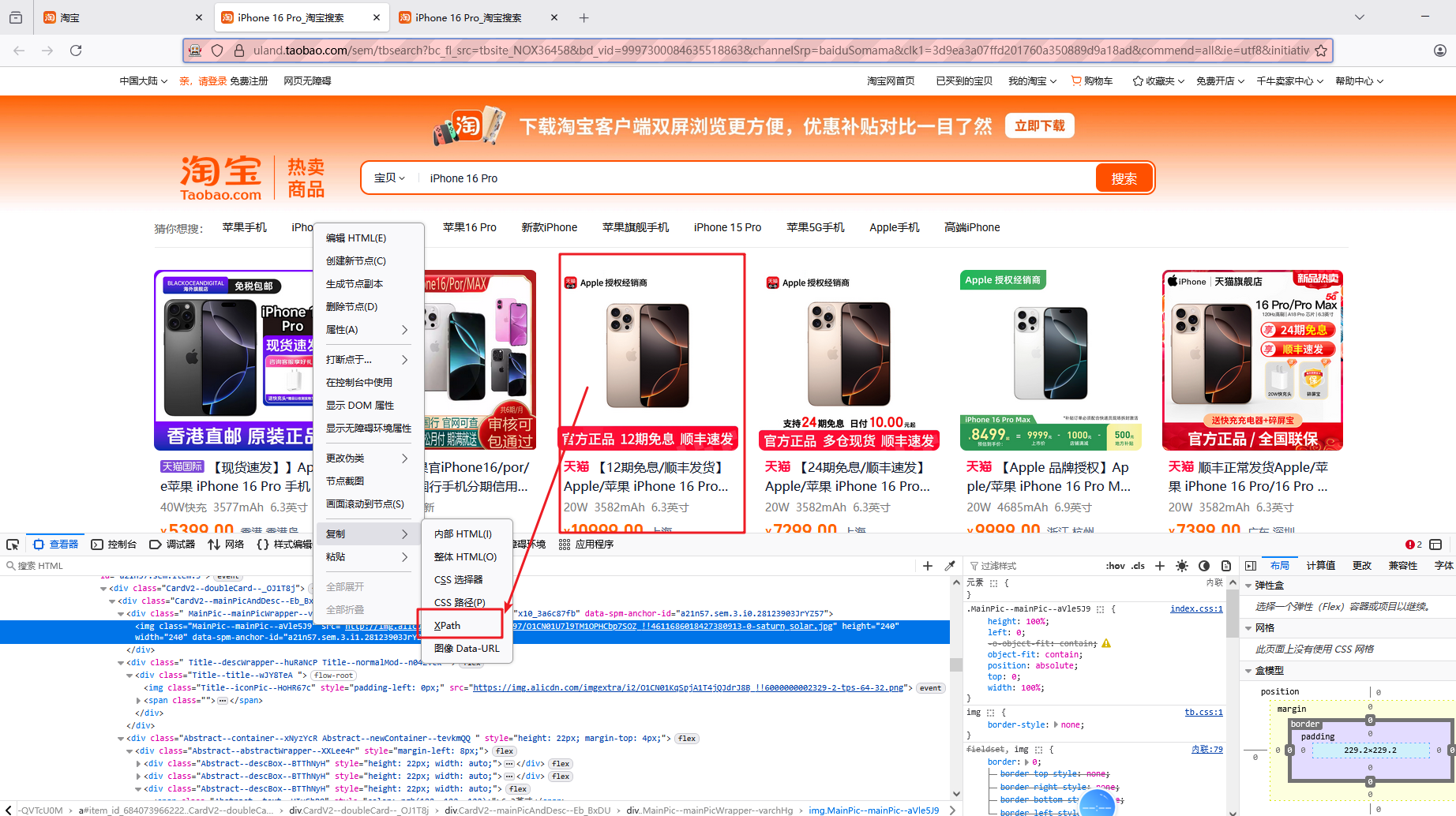
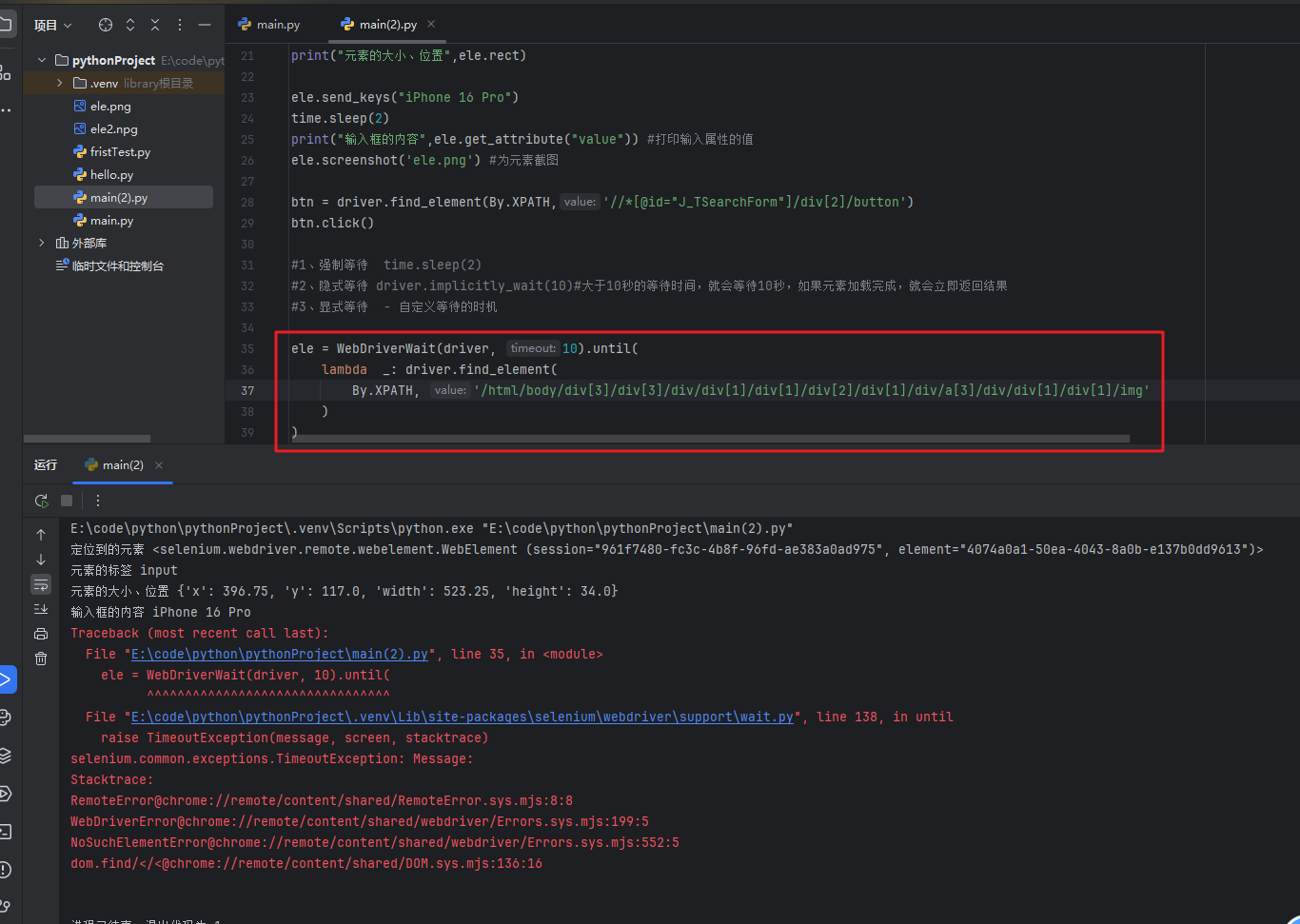

python+selenium 关于取淘宝商品页面某个商品的XPath,显式等待一直报错,XPath取a标签、div、img都运行失败,求解
 分享
分享
上午好☀️☀️☀️️
本答案参考通义千问
在使用 Python + Selenium 进行自动化测试时,遇到 XPath 无法定位元素 的问题非常常见。你提到“显式等待一直报错”,并且尝试通过 a、div、img 等标签取值失败,这可能涉及多个原因,包括:
淘宝的商品页面通常是通过 JavaScript 动态加载内容的,这意味着你不能直接通过简单的 find_element 定位元素,因为元素可能在页面加载完成后才出现。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://detail.tmall.com/item.htm?id=1234567890") # 替换为实际商品ID
try:
# 显式等待:等待某个关键元素加载完成(如商品标题)
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="J_Title"]'))
)
print("元素成功找到!")
except Exception as e:
print("元素未找到,错误信息:", e)
finally:
driver.quit()
注意: 请根据实际页面结构调整 XPath 路径。
你可以使用浏览器开发者工具(F12)查看目标元素的结构,并复制正确的 XPath。
例如,一个正确的 XPath 可能是:
# 示例:获取商品标题
title_xpath = '//*[@id="J_Title"]'
显式等待需要配合 expected_conditions 使用,常见的条件包括:
| 条件 | 含义 |
|------|------|
| presence_of_element_located() | 元素存在于 DOM 中 |
| element_to_be_clickable() | 元素可点击 |
| visibility_of_element_located() | 元素可见 |
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.XPATH, '//a[@class="some-class"]'))
)
element.click()
淘宝页面可能嵌套了 iframe 或使用了 Shadow DOM,导致常规 XPath 无法定位元素。
# 切换到 iframe
iframe = driver.find_element(By.XPATH, '//*[@id="J_Frame"]')
driver.switch_to.frame(iframe)
# 再次定位元素
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="product-img"]'))
)
如果 XPath 太复杂或容易出错,可以尝试用 CSS 选择器来定位元素。
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#J_Title'))
)
使用显式等待确保元素已加载
WebDriverWait(driver, 10).until(...)
使用浏览器开发者工具获取准确的 XPath
检查页面是否为动态加载,必要时使用 execute_script 模拟滚动
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
处理 iframe 或 Shadow DOM
driver.switch_to.frame(...)
尝试使用 CSS 选择器替代 XPath
By.CSS_SELECTOR
| 错误提示 | 原因 | 解决方案 |
|----------|------|----------|
| NoSuchElementException | 元素未加载完成 | 添加显式等待 |
| TimeoutException | 等待时间不足 | 增加等待时间 |
| StaleElementReferenceException | 元素过期 | 重新定位元素 |
| ElementNotVisibleException | 元素不可见 | 使用 visibility_of_element_located |
如果你能提供具体的 XPath 表达式或页面截图,我可以帮你进一步分析和修正。希望这些方法能帮助你解决问题!
分享 创建了问题
8月20日
创建了问题
8月20日

