
每次代码运行爬取的小说章节不一样有的时候多有的时候少并且不能全部爬取下来
希望有人帮忙解决
代码如下:
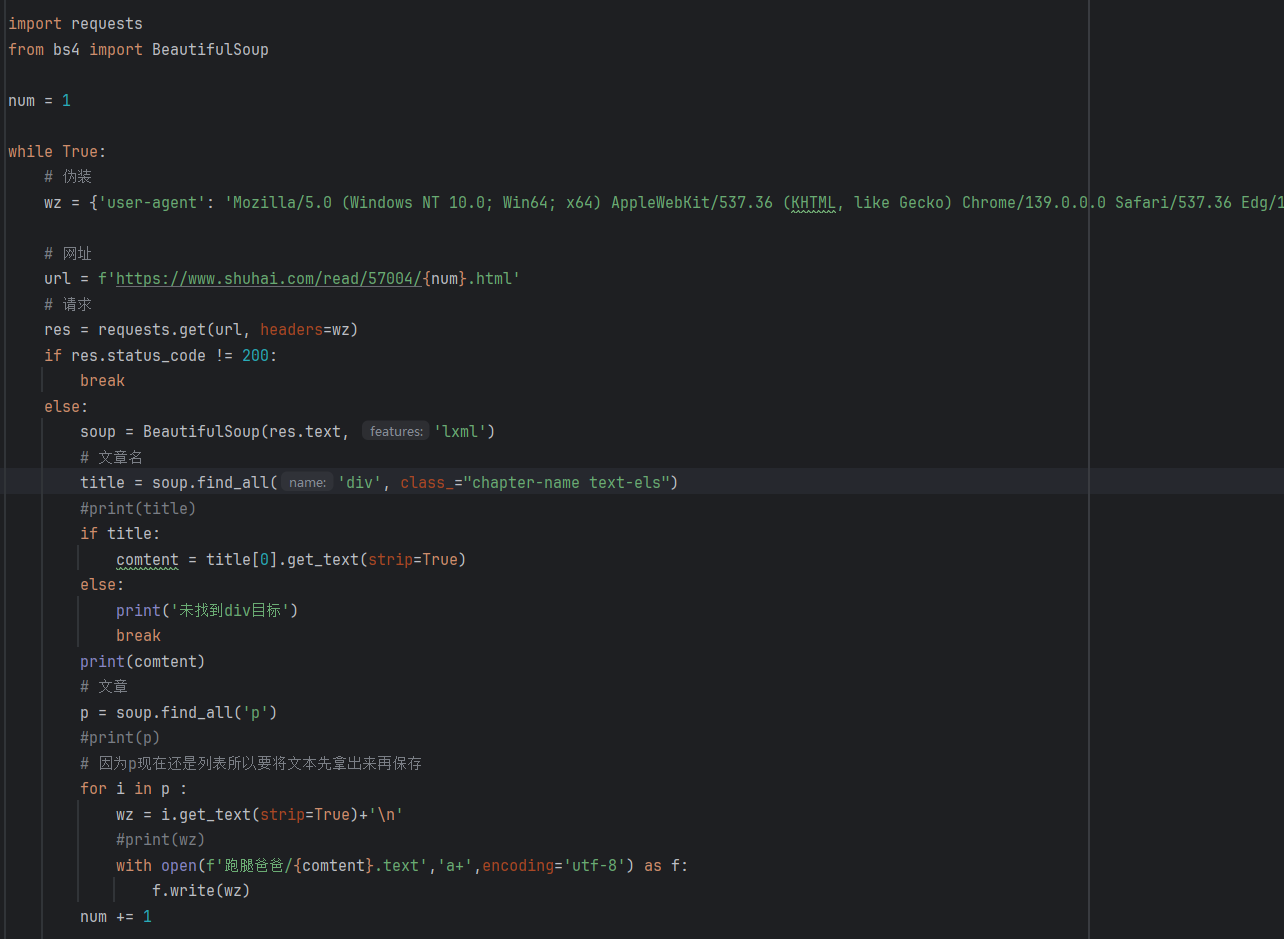
importrequests
from bs4 import BeautifuLSoup
num=1
while True:
#伪装
wZ=fuser-agent':Mozilla/5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,ike Gecko) Chrome/139.0.0.0 Safari/537.36Edg/
#网址
UrL=f'https://www.shuhai.com/read/57004/num.html
#请求
res=requests.get(ur,headers=Wz)
ifres.status_code!=200:
break
else:
soup=BeautifulSoup(res.text, features:lxmL')
#文章名
title=soup.find_al(name:div',class_="chapter-nametext-es")
#print(title)
iftitle:
comtent=titelo].get_text(strip=True)
else:
print(未找到div目标)
break
print(comtent)
#文章
p= soup.find_all('p')
#print(p)
#因为p现在还是列表所以要将文本先拿出来再保存
foriinp:
WZ=i.get_text(strip=True)+'n
#print(wZ)
withopen(f·跑腿爸爸/fcomtent.text,a+l,encoding=utf-8')asf:
f.write(wZ)
num +=1






