使用Selenium爬取网页信息的时候,这个评分数据爬出来一直为空,其他数据都可以爬到。有人可以帮忙看看为什么吗。
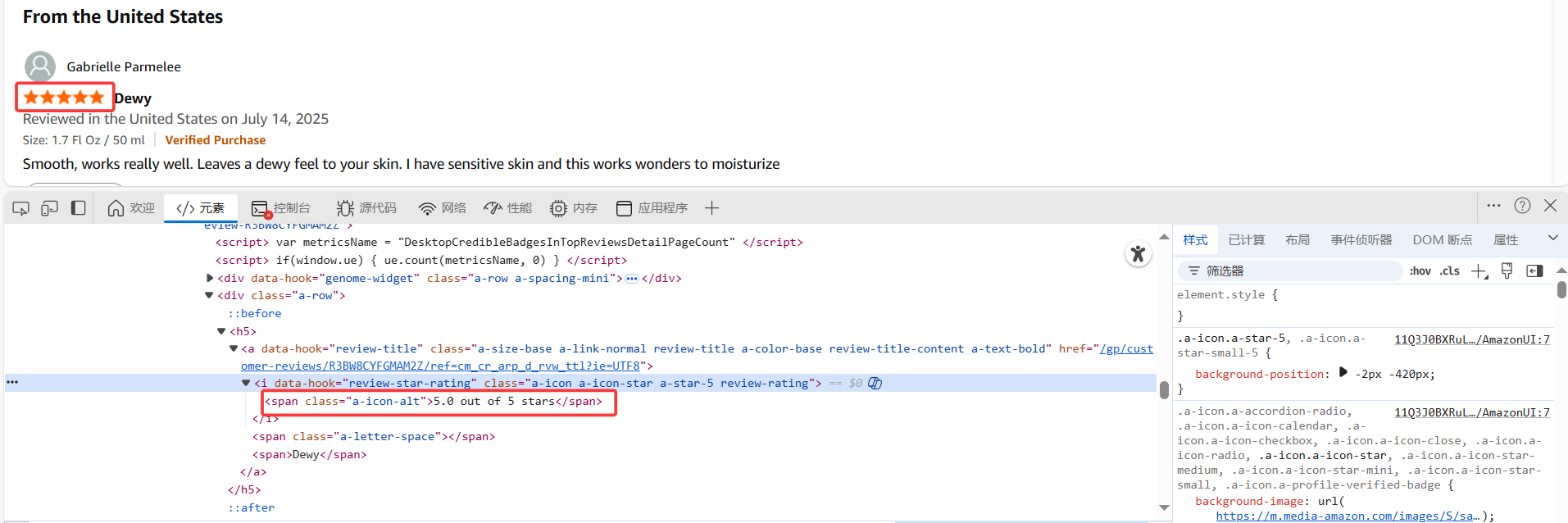

使用Selenium爬取网页信息的时候,这个评分数据爬出来一直为空,其他数据都可以爬到。有人可以帮忙看看为什么吗。
 分享
分享
上午好☀️☀️☀️️
本答案参考通义千问
在使用 Selenium 爬取网页信息时,如果评分数据一直为空,而其他数据可以正常获取,可能是以下原因导致的。以下是详细分析和解决方案:
元素未加载完成
定位方式错误
<span>、<div>、<rating> 等)。动态内容或框架问题
浏览器窗口大小或位置问题
反爬机制或验证码
重点: 如果评分数据是通过异步请求加载的,请检查对应的XHR请求,看看是否需要模拟登录或处理Cookie。
使用 WebDriverWait 等待评分元素出现后再进行操作。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com")
try:
# 等待评分元素加载完成(假设评分元素的id为"rating")
rating_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "rating"))
)
print(rating_element.text) # 获取评分文本
except Exception as e:
print("无法找到评分元素:", e)
重点: 使用
presence_of_element_located或visibility_of_element_located来判断元素是否已经加载并可见。
//div 或 //*[@class="some-class"]。# 示例:使用XPath定位评分元素
rating_element = driver.find_element(By.XPATH, '//div[@class="rating"]')
重点: 使用
find_element()和find_elements()时,务必确保定位器是唯一的、精准的。
如果你发现评分数据位于某个 iframe 内部,需要先切换到该 frame:
driver.switch_to.frame("frame_name_or_id")
rating_element = driver.find_element(By.ID, "rating")
print(rating_element.text)
driver.switch_to.default_content() # 切换回主文档
重点: 如果页面使用了 Shadow DOM,可以使用 JavaScript 直接操作:
script = """
return document.querySelector('your-shadow-root-selector').shadowRoot.querySelector('.rating').textContent;
"""
rating_text = driver.execute_script(script)
print(rating_text)
某些网站会根据屏幕尺寸显示不同内容,你可以调整窗口大小:
driver.maximize_window() # 最大化窗口
driver.set_window_size(1920, 1080) # 设置特定分辨率
import time
import random
time.sleep(random.uniform(1, 3)) # 随机等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import random
driver = webdriver.Chrome()
try:
driver.get("https://example.com")
# 随机等待,模拟人类行为
time.sleep(random.uniform(1, 3))
# 显式等待评分元素加载
rating_element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.XPATH, '//div[@class="rating"]'))
)
print("评分数据:", rating_element.text)
except Exception as e:
print("发生错误:", e)
finally:
driver.quit()
| 原因 | 解决方案 |
|------|----------|
| 元素未加载完成 | 使用 WebDriverWait 等待元素加载 |
| 定位方式错误 | 检查XPath/CSS选择器是否正确 |
| iframe/Shadow DOM | 切换frame或使用JavaScript操作 |
| 浏览器窗口问题 | 调整窗口大小或最大化 |
| 反爬机制 | 添加随机等待、模拟人类行为 |
如果你能提供具体的网页链接或评分元素的HTML结构,我可以进一步帮你分析具体问题!
分享 创建了问题
8月22日
创建了问题
8月22日


