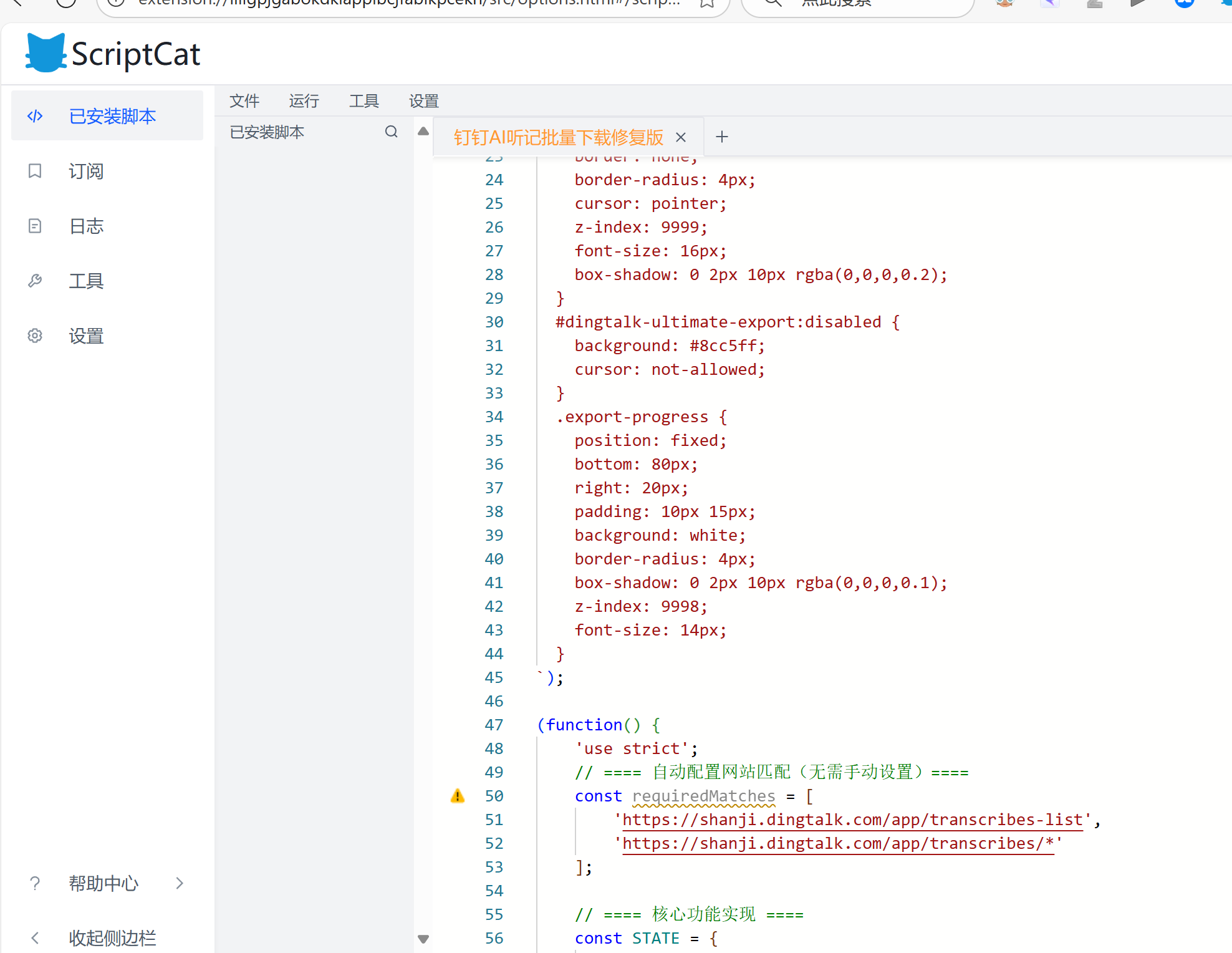
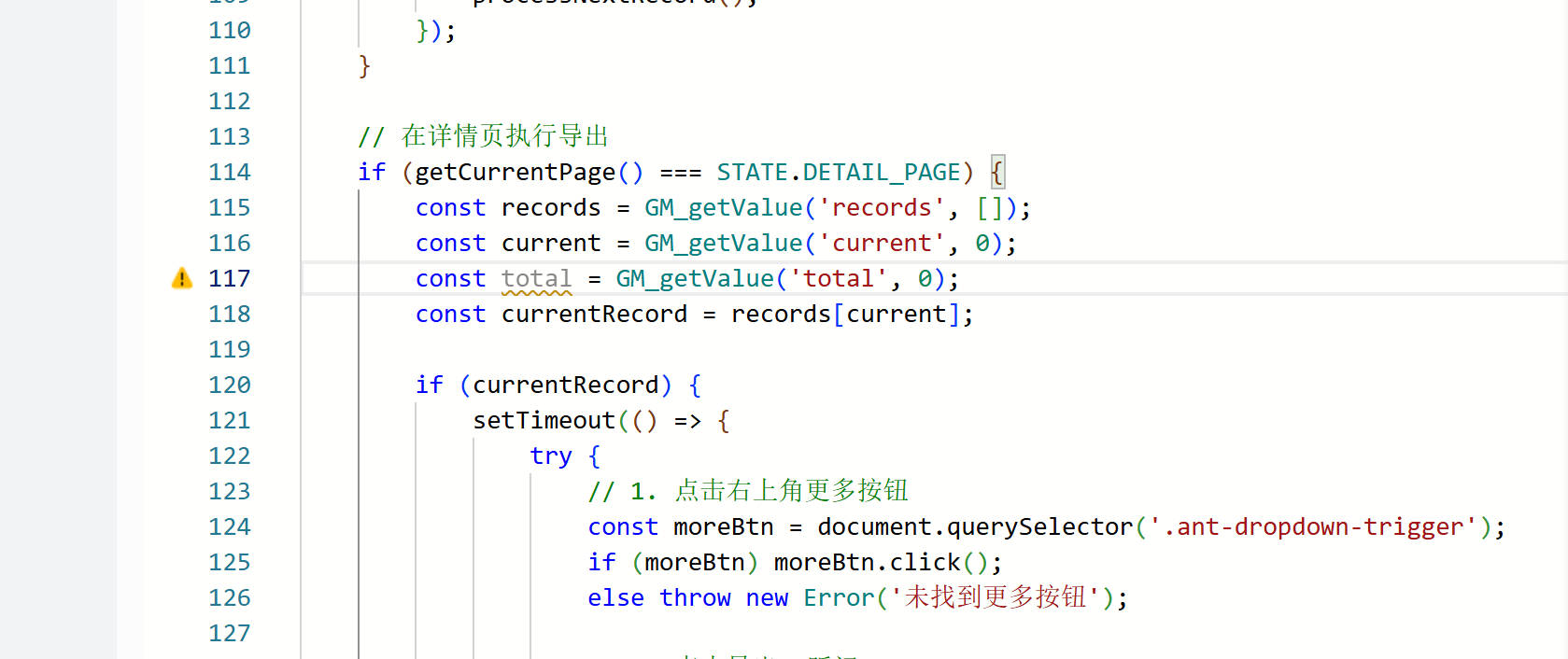
求解| 为什么两个const都有问题?
┭┮﹏┭┮
还是因为我用了脚本猫呢?我就想做一个可以批量下载的功能,不然我就要手动下载500条文件里,真的很累……有没有朋友可以指导我一下

求解| 为什么两个const都有问题?
 分享
分享
 关注
关注让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
requests库来实现一个简单的批量下载功能示例。file_urls = [] # 假设这里存放了500条文件的URL
# 模拟获取500条文件URL并存入file_urls列表
for i in range(500):
file_urls.append(f’http://example.com/file_{i}.txt’)
for url in file_urls:
response = requests.get(url)
if response.status_code == 200:
with open(f’downloaded_file_{url.split(“/”)[-1]}’, ‘wb’) as f:
f.write(response.content)
``
- 在上述代码中:
- 首先创建了一个包含多个文件URL的列表file_urls。
- 然后通过循环遍历每个URL,使用requests.get方法获取文件内容。
- 当响应状态码为200时,将文件内容写入本地文件,文件名使用URL中的文件名部分。
3. **多种解决方案的优缺点**:
- **Python + requests库**:
- **优点**:简单易用,对于网络请求和文件处理有丰富的库函数支持,代码可读性高。
- **缺点**:如果要处理大量文件且网络不稳定时,可能会出现下载中断等问题,需要额外处理重试机制。
- **使用专业的下载工具如wget(在命令行环境)**:
- **优点**:在命令行下操作方便,对于批量下载有较好的支持,有一些参数可以方便地控制下载行为,如限速等。
- **缺点**:需要在命令行环境下使用,对于不熟悉命令行的用户不太友好,且在复杂的网络环境配置等方面相对Python代码灵活性稍差。
4. **总结**:
- 批量下载功能可以通过多种方式实现。Python结合requests`库是一种较为便捷的方法,能满足一般的批量下载需求。在实际应用中,还可以根据具体需求进一步优化,比如添加进度显示、错误处理等功能。同时,要注意下载的文件来源合法性等问题。
需要注意的是,由于提问者未提供具体的const相关代码问题,以上解答主要围绕批量下载功能展开。如果能提供更多关于const问题的详细信息,能给出更针对性的解答。
希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。
分享 创建了问题
8月26日
创建了问题
8月26日


