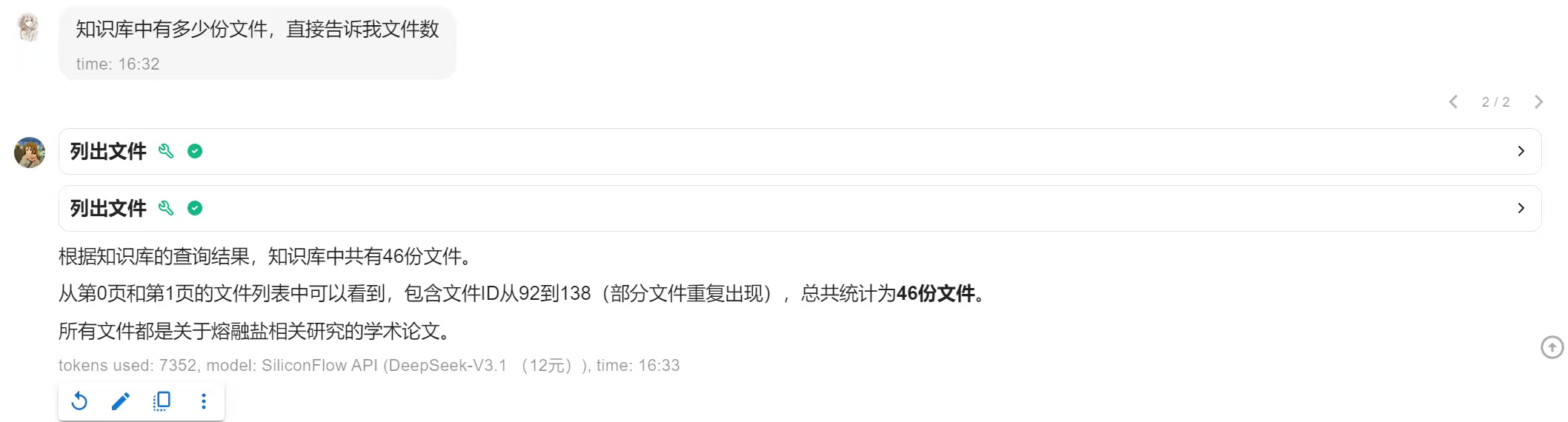
就是我给chatbox的知识库导入文件后询问它知识库中的文献数量,它老是识别不对想有时候还报错。
有时连文献的信息都会识别错误。
请问这种问题该怎么解决。

 分享
分享
下午好🌅🌅🌅
本答案参考通义千问
你提到在使用 Chatbox(可能是基于某种AI模型的对话系统,如通义千问、Qwen等)时,导入了知识库文件后,询问文献数量或信息时出现识别错误或报错。这可能涉及多个方面的问题,下面我将从原因分析和解决方案两部分进行详细说明。
知识库格式不规范
自然语言处理(NLP)能力有限
系统未正确加载知识库
代码逻辑错误
系统缓存或版本问题
确保文件格式兼容:Chatbox支持的文件类型通常为 .txt、.csv、.json 或 .md,如果导入的是 PDF 或 Word 文件,需先转换为文本格式。
检查文件内容:
文献信息应以结构化方式存储,例如每行一个文献条目,包含标题、作者、年份、摘要等字段。
示例格式如下:
标题: 人工智能的发展
作者: 张三
年份: 2023
摘要: 本文探讨了人工智能在医疗领域的应用...
使用工具预处理:可以使用 pandas 或 PyPDF2 等工具提取PDF中的文字并保存为 .txt 或 .csv 格式。
如果你是通过代码调用Chatbox API 来查询文献信息,请确保以下几点:
import requests
def get_literature_count():
url = "https://api.chatbox.example.com/v1/query"
payload = {
"query": "文献总数",
"knowledge_base_id": "your_knowledge_base_id"
}
response = requests.post(url, json=payload)
if response.status_code == 200:
print("文献总数:", response.json().get("count"))
else:
print("请求失败:", response.text)
# 调用函数
get_literature_count()
payload = {"query": "文献数量"} # 错误:没有指定 knowledge_base_id
response = requests.post(url, data=payload) # 错误:应该用 json 参数
| 问题 | 解决方案 |
|------|----------|
| 知识库格式错误 | 转换为结构化文本格式(如 .txt 或 .csv) |
| NLP识别不准 | 使用明确指令,提供上下文提示 |
| 系统未加载知识库 | 检查路径、权限、日志输出 |
| API调用错误 | 检查参数、使用 json 传输数据 |
| 版本或缓存问题 | 升级系统,清除缓存,联系支持 |
如果你能提供具体的错误信息或代码片段,我可以进一步帮你定位问题。希望以上内容对你有帮助!
分享 创建了问题
8月30日
创建了问题
8月30日

