

问题遇到的现象和发生背景
本人想本地部署大模型用于学生学习,设计采用VLLM框架作为推理后段(满足并发),openweb-ui作为前端让用户有网页图形界面进行访问,本来是想采用docker部署,电脑配置如下

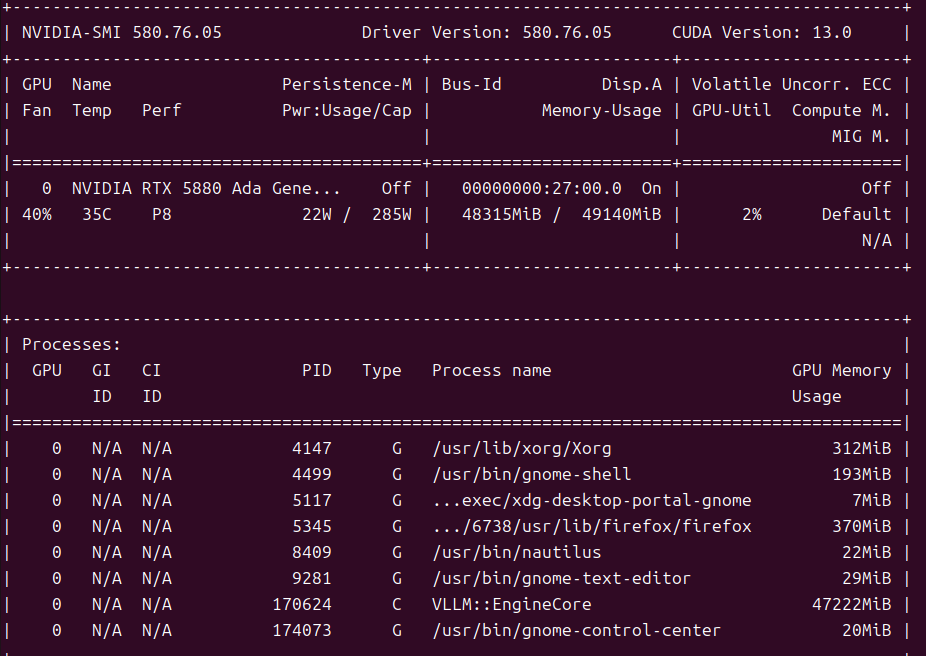
ubuntu 版本24.04 LTS,显存48GB,内存1024GB
已成功安装Nvidia驱动,驱动版本580.76.05,Cuda版本13.0
在终端输入
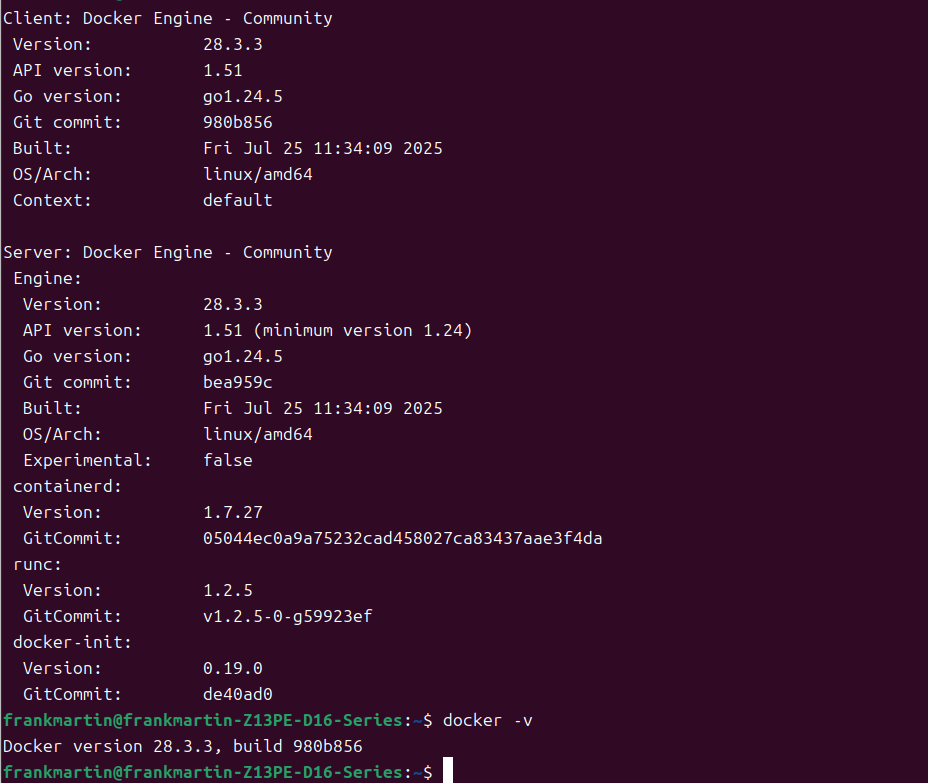
docker -v
可以看到docker版本28.3.3
首先进入虚拟环境,输入
conda activate CQUPT
进入环境了

此时输入命令安装VLLM
pip install vllm
显示如图
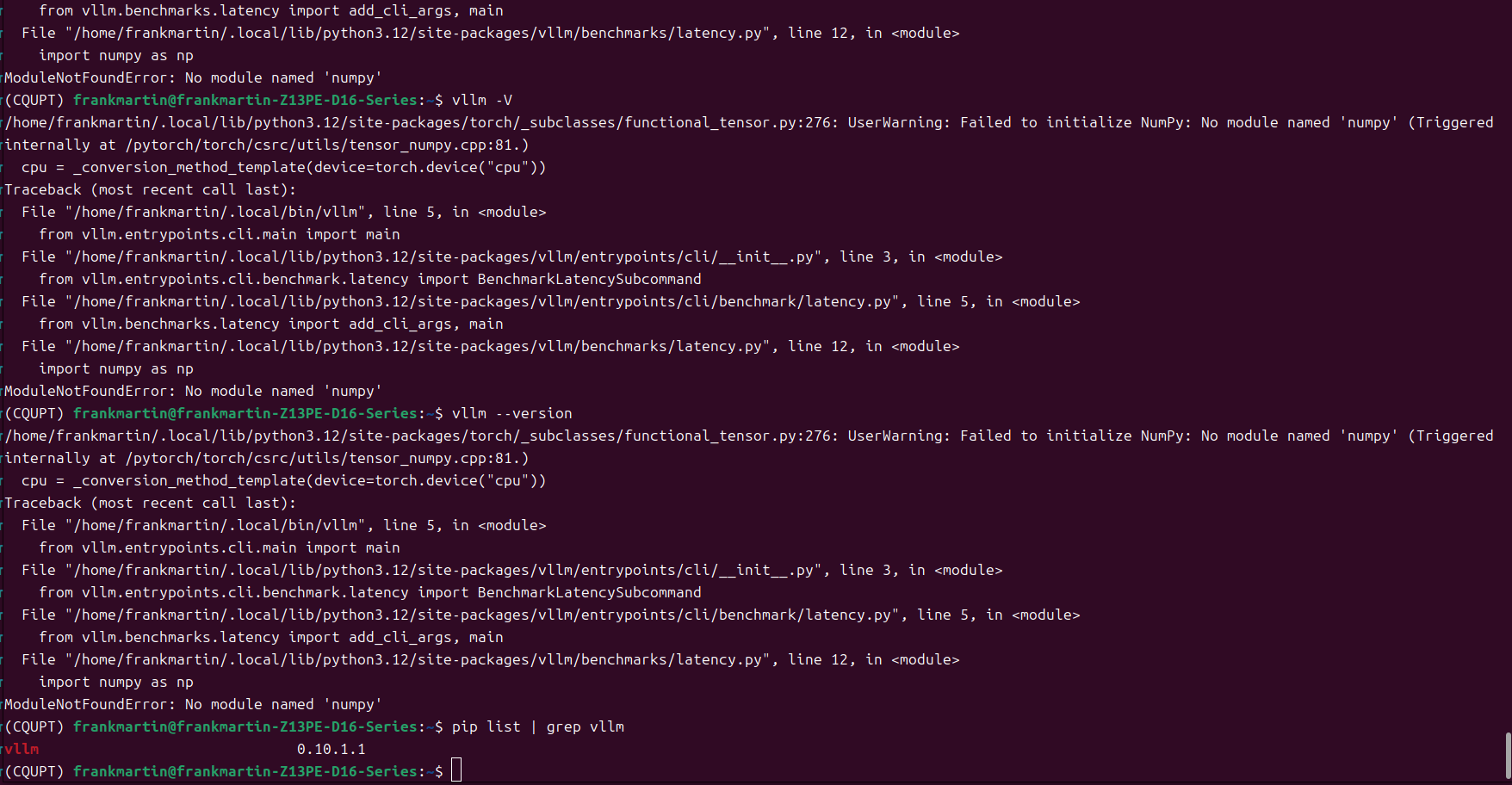
输入命令查看VLLM版本
pip list | grep vllm
可以看到输出如图,版本号是0.10.0.1
因为前面已经设置了docker的镜像源和拉取镜像,直接可以查看已经有的openweb-ui镜像
输入命令
docker images
可看到目前仓库显示如图

遇到的现象和发生背景,请写出第一个错误信息
然后在开始按照教程利用docker部署vllm和openweb-ui开始,出现问题了
我本地模型下载的是Qwen3-235B-22B-2507蒸馏版,Deepseek 70B蒸馏版和14B模型
首先,我问了deepseek,采用start脚本模式,命令如下
新建start_vllm.sh脚本,并编辑
用代码块功能插入代码,请勿粘贴截图。 不用代码块回答率下降 50%
#!/bin/bash
MODEL_PATH="/home/frankmartin/home/frankmartin/Models/models/Qwen3-235B-A22B-Instruct-2507-AWQ"
NUM_GPUS=1
API_KEY="CQUPTYYX5003"
docker run --runtime nvidia --gpus all \
-v ${MODEL_PATH}:/model \
-p 8000:8000 \
--ipc=host \
--name CQEA830\
-d \
vllm/vllm-openai:latest \
--model /model \
--tensor-parallel-size ${NUM_GPUS} \
--served-model-name Qwen3-235B-A22B \
--host 0.0.0.0 \
--port 8000
--max-model-len 8192 \
--gpu-memory-utilization 0.95 \
--swap-space 128 \
--cpu-offload-gb 512 \
--quantization awq \
--api-key ${API_KEY}
运行结果及详细报错内容
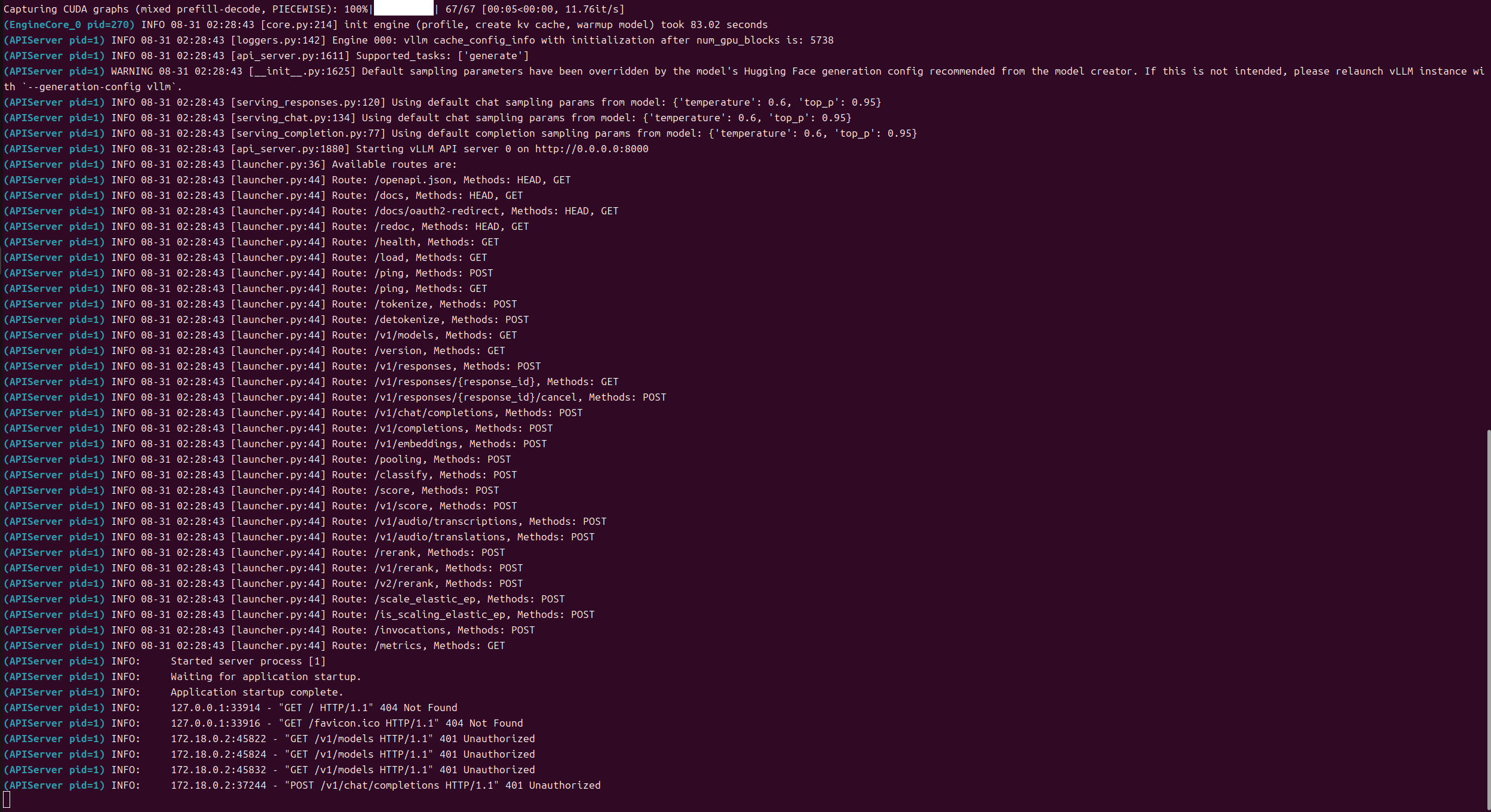
按照该脚本启动之后,屏幕报错

之后尝试调整VLLM的参数,例如加大swap-space交换空间,调高cpu-offload-gb加大内存卸载空间,要么提示swap-space 是无效命令,要么删除该字段后提示CUDA out of memory(爆显存)
我的解答思路和尝试过的方法
无奈,只有采用更小模型,并且不使用start_vllm.sh脚本尝试启动docker运行vllm,切换成14B的模型,启动命令行如下:
docker run -d \
--gpus all \
--restart unless-stopped \
--name VLLM830 \
--network host \
-v /home/frankmartin/DeepSeek-R1-Distill-Qwen-14B:/model \
vllm/vllm-openai:latest \
--model /model \
--served-model-name DSR1 1.5B \
--dtype half \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.95 \
--cpu-offload-gb 0 \
--max-model-len 8196 \
--api-key CQUPTYYX5003
--host 0.0.0.0 \
--port 8000 \
之后系统开始加载deepseek 14B模型,显示显存有占用
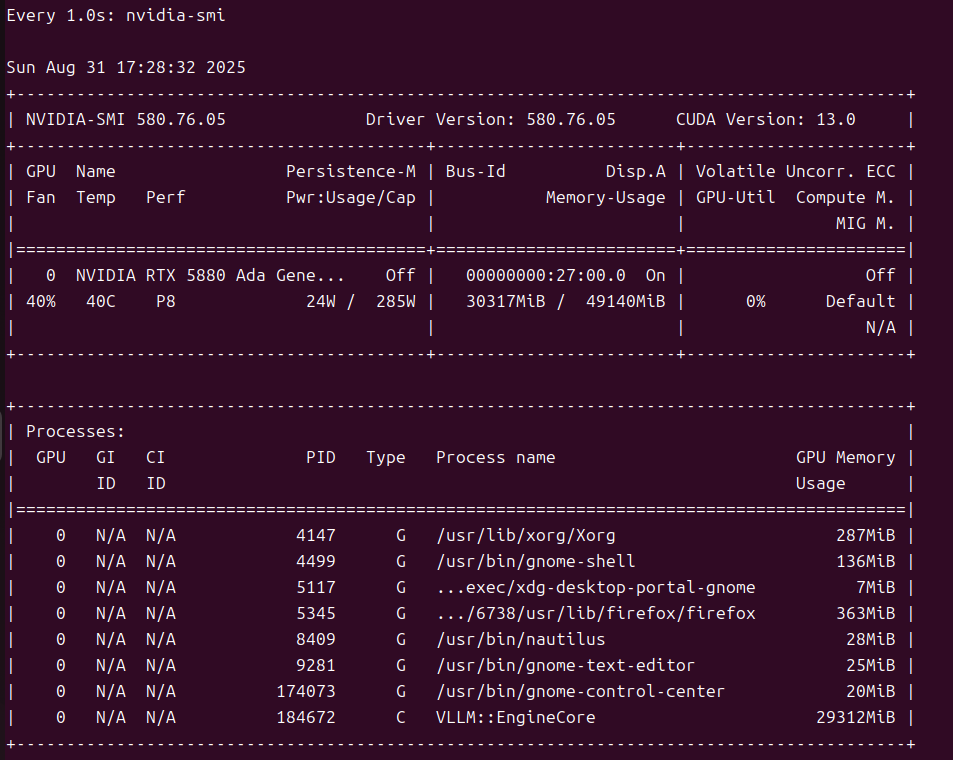
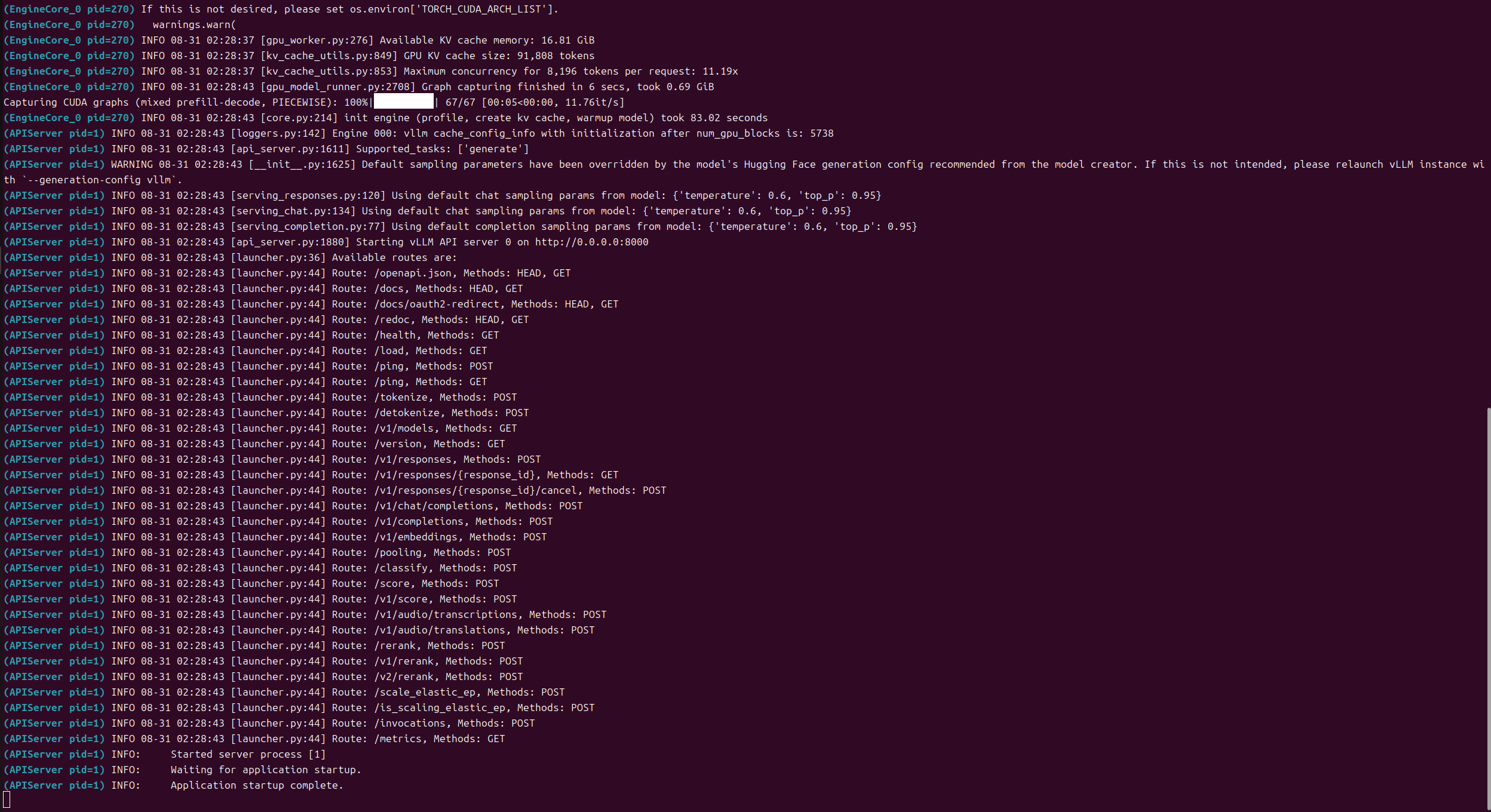
并且日志部分也显示 Application startup complete
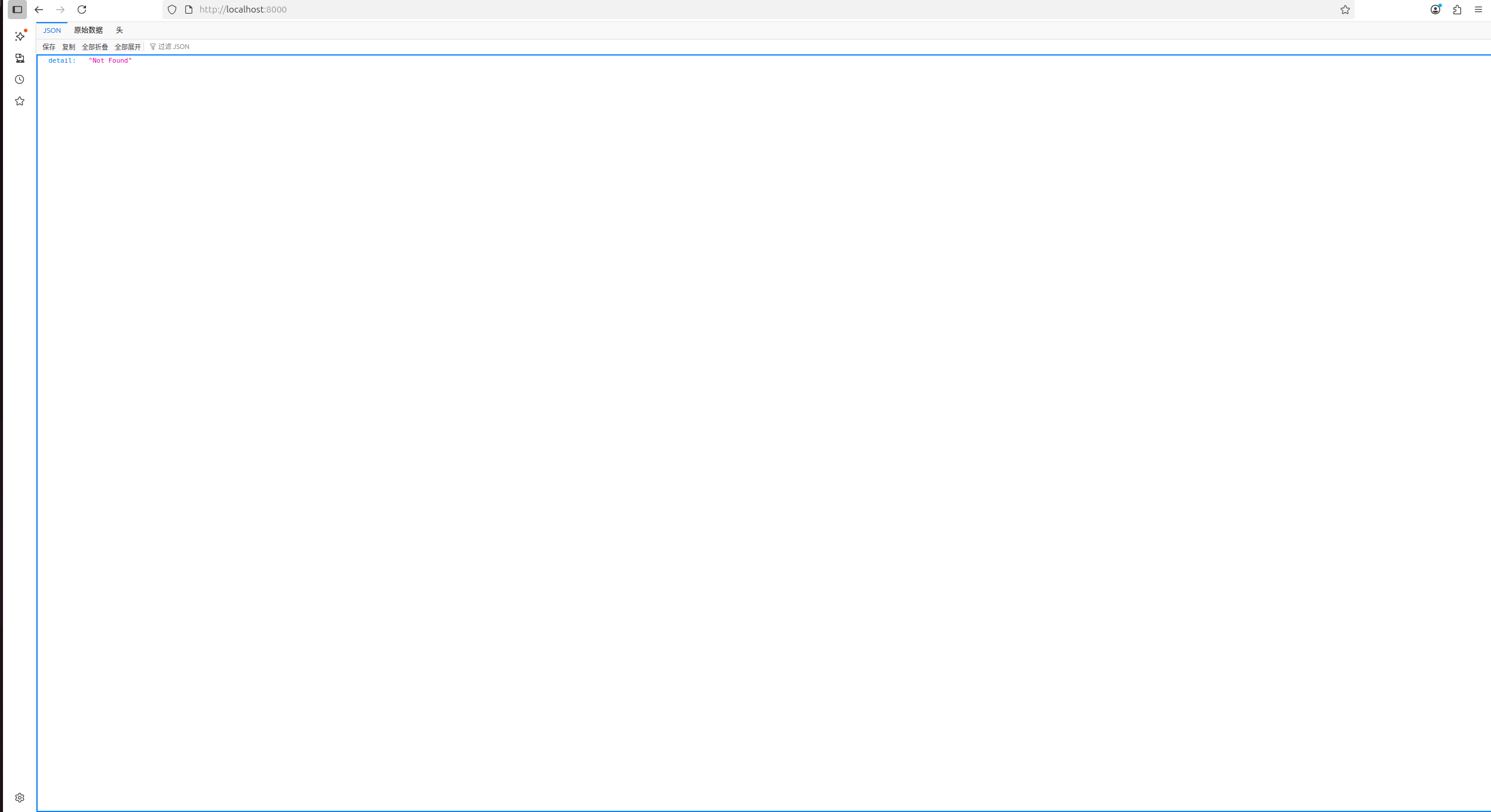
本地浏览器访问 http://localhost:8000/,看到如图
然后通过docker 启动 openweb-ui前端,采用yml脚本,输入 docker compose up -d,脚本内容如下
端口调整为3212
services:
open-webui:
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/ghcr.io/open-webui/open-webui:v0.6.25
container_name: open-webui-app
ports:
- "3212:8080" #
volumes:
- open-webui-data:/app/backend/data #
environment:
- OLLAMA_BASE_URL=http://vllm-backend:8000 #
- WEBUI_NAME=DeepSeek-70B Chat
- WEBUI_URL=http://localhost:3212
- DISABLE_SIGNUP=false #
extra_hosts:
- "host.docker.internal:host-gateway"
restart: unless-stopped
networks:
- openwebui-net
networks:
openwebui-net:
driver: bridge
volumes:
open-webui-data:
driver: local
最初我的脚本里面是没有
extra_hosts:
- "host.docker.internal:host-gateway"
这一块的,后来进入到openweb-ui设置API连接为http://localhost:8000/,或者http://localhost:8000/v1,openweb-ui都显示netweork problem,我才把那个extra的参数加入,但是仍然无效
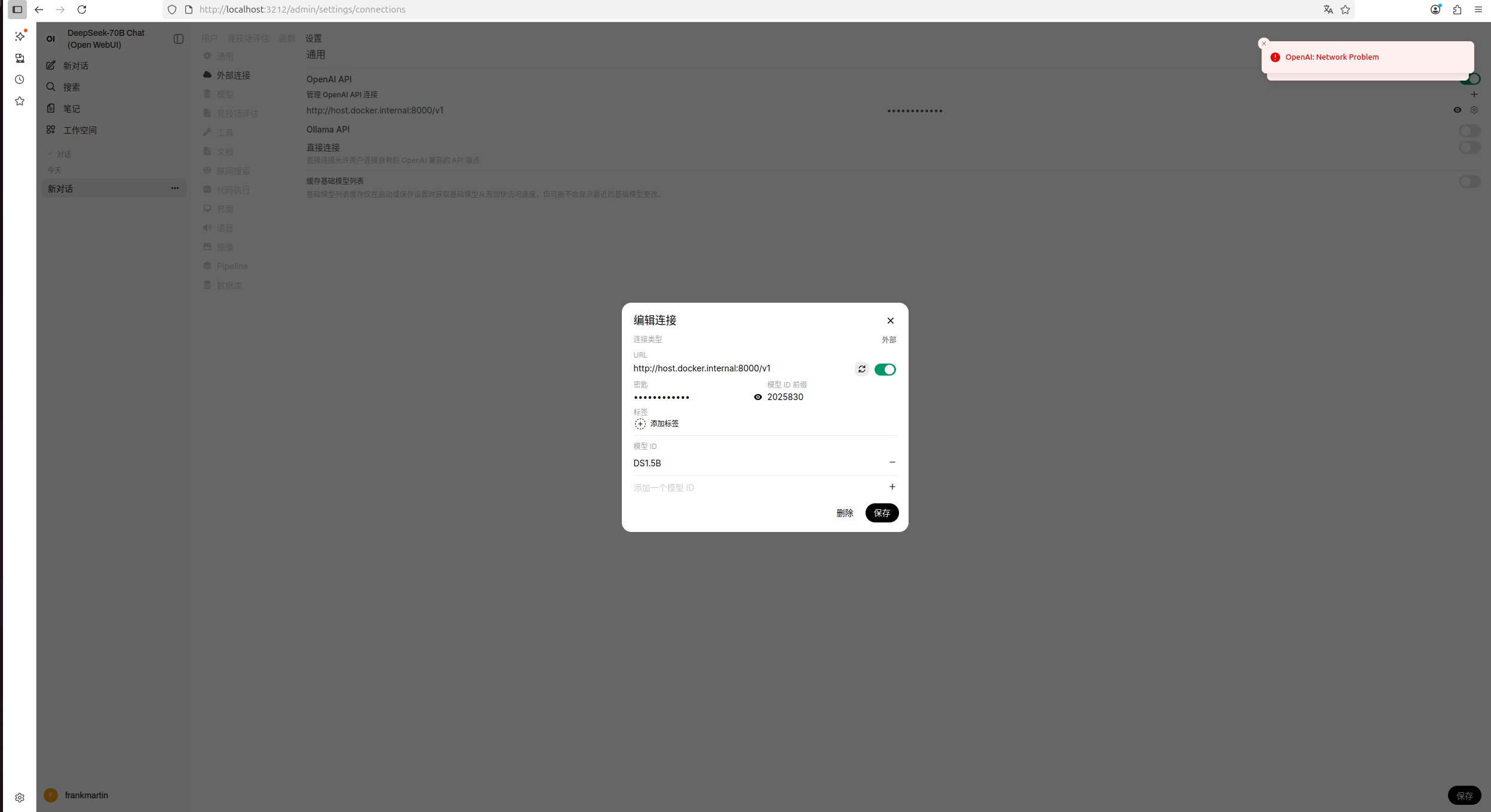
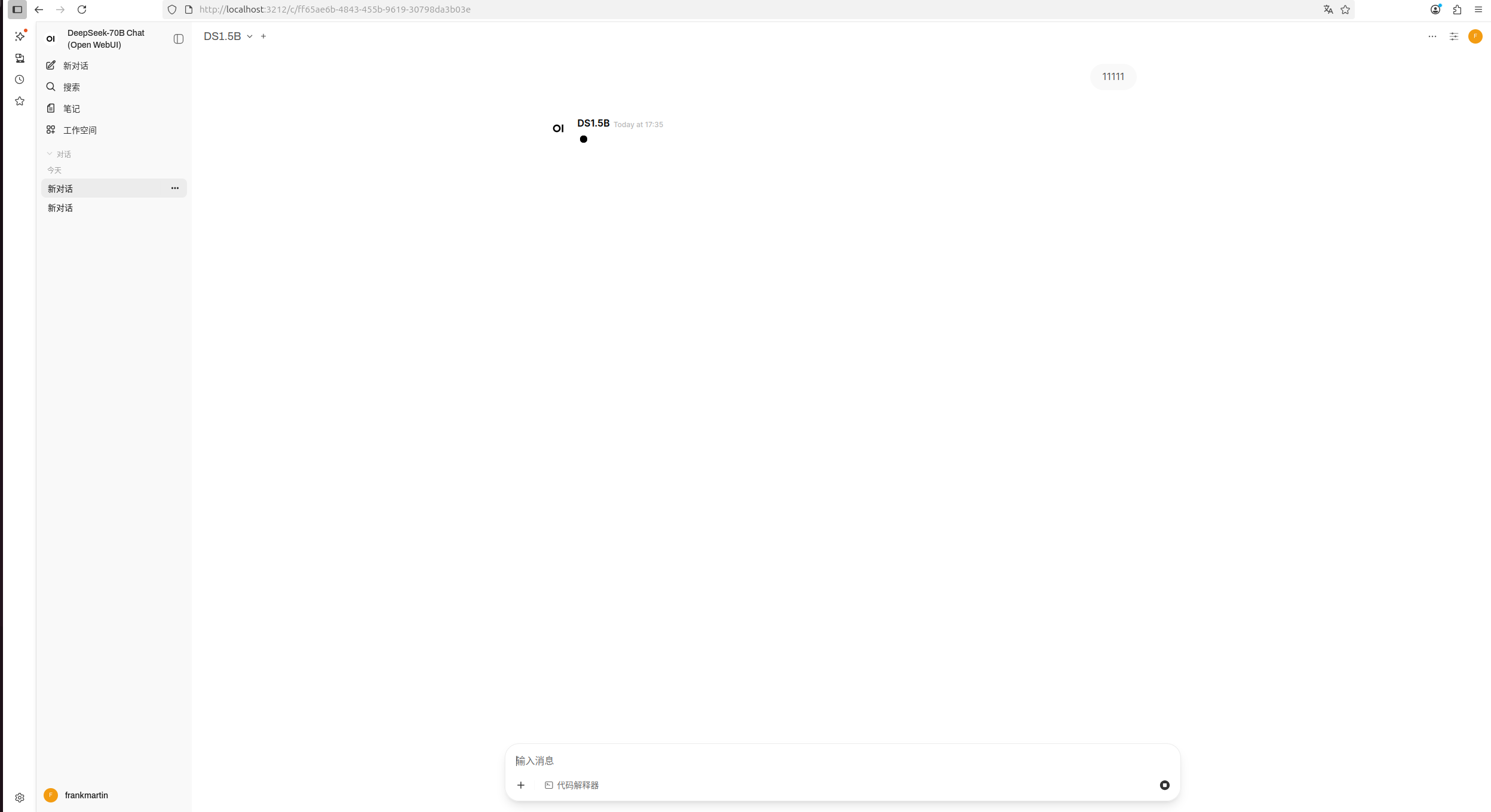
然后进入对话界面,也是无法对话,始终在转圈
终端界面显示的是这样
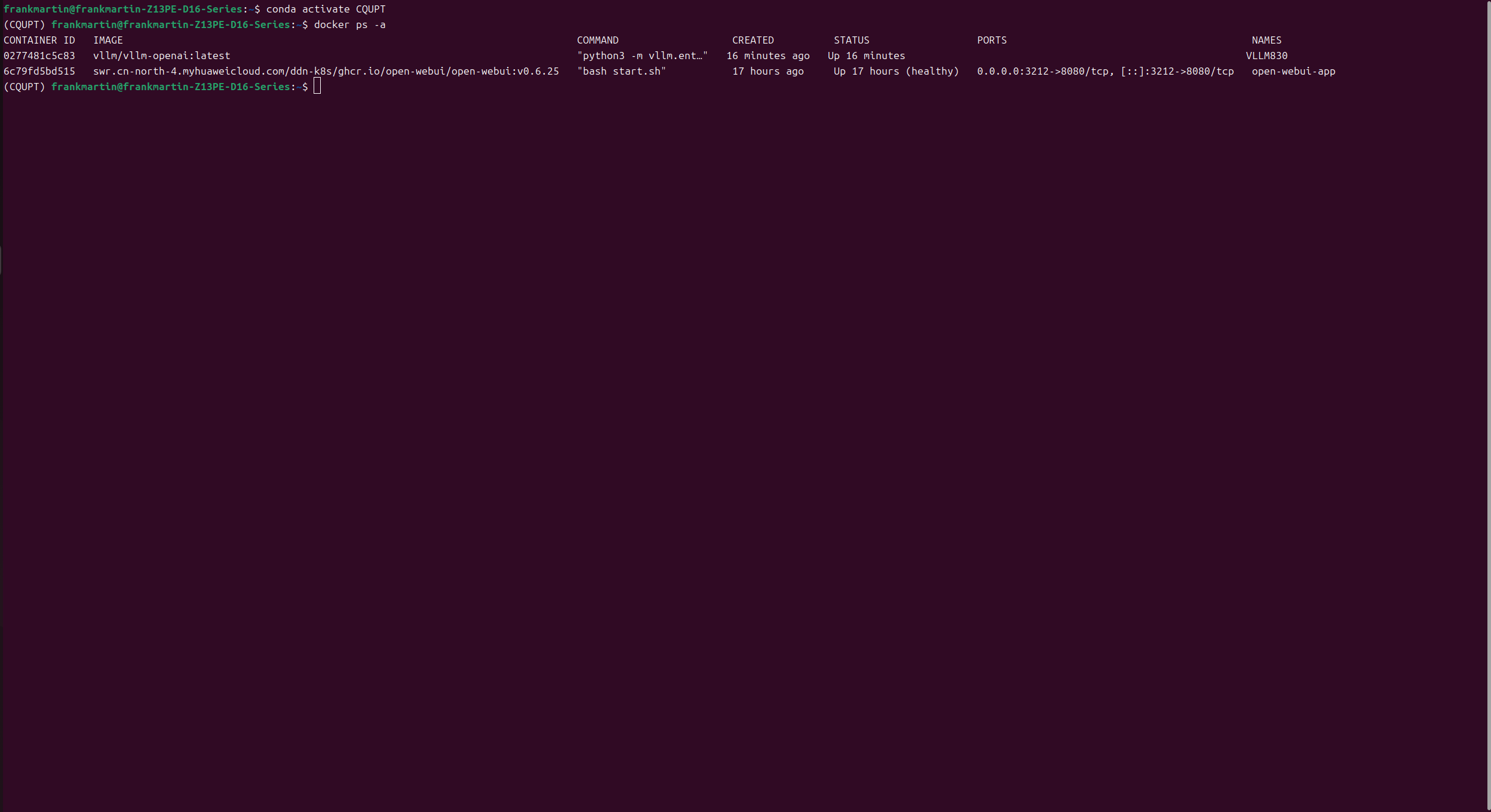
查看docker运行情况,VLLm服务没有显示端口
我想要达到的结果
按理说Qwen3模型文件有200多G,可能后期我会加卡,但目前连14B模型都无法跑通,应该是我的命令行或者docker的网络地址设置哪里出了问题?请大家帮帮我






