本人本科实习,初次接触TCIA,我按教程走的,是在下载数据集时.tcia文件时,NBIA数据检索器并没有弹出,过一段时间后桌面就弹出了上面这个报错,请问一下有什么解决方法
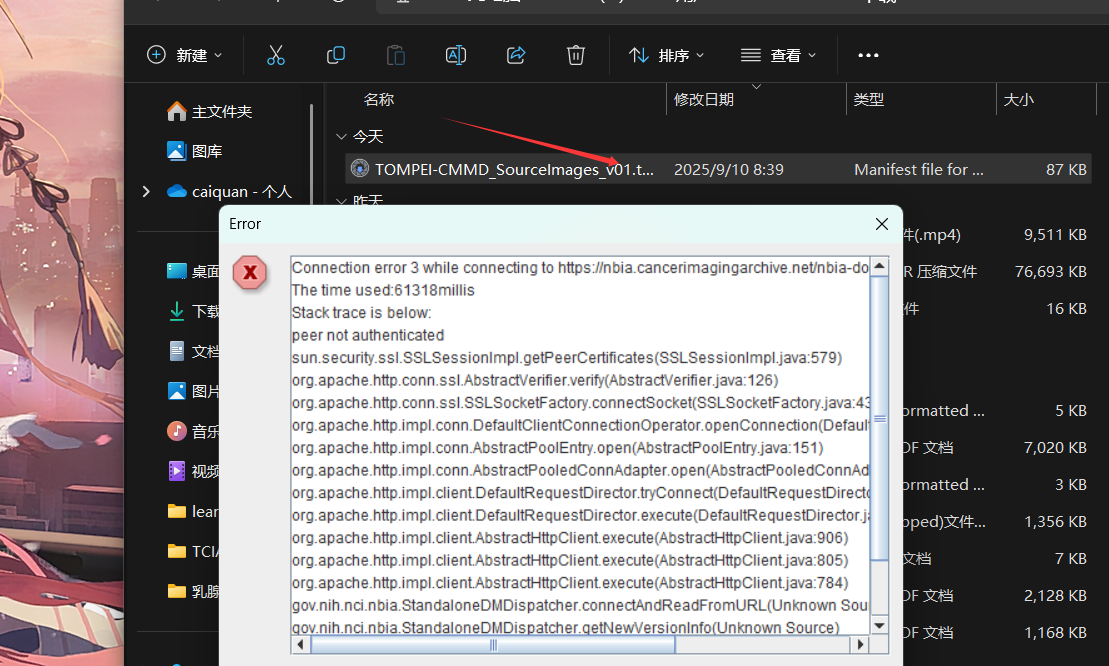

本人本科实习,初次接触TCIA,我按教程走的,是在下载数据集时.tcia文件时,NBIA数据检索器并没有弹出,过一段时间后桌面就弹出了上面这个报错,请问一下有什么解决方法
 分享
分享
上午好☀️☀️☀️️
本答案参考通义千问
你遇到的问题是在使用TCIA(The Cancer Imaging Archive)下载数据集时,NBIA数据检索器没有弹出,并且最终出现了报错。这种情况通常与浏览器兼容性、网络设置或软件配置有关。
推荐使用 Internet Explorer (IE) 或 Microsoft Edge:
禁用广告拦截插件:
重点: _建议使用 Internet Explorer 或 Edge 浏览器进行 TCIA 下载操作。
nbia.cancerimagingarchive.net),可能需要安装 Java。重点: _确保 Java 已正确安装并启用在浏览器中。
允许弹出窗口:
tcia.cancerimagingarchive.net 添加到“允许弹出窗口”的白名单中。启用 JavaScript 和 ActiveX 控件(仅限 IE):
如果上述方法仍无法解决问题,可以考虑使用 Python 脚本 或 命令行工具 来下载数据。
import requests
from bs4 import BeautifulSoup
# 替换为实际的项目 ID
project_id = "TCGA-GBM"
# 获取数据集页面
url = f"https://nbia.cancerimagingarchive.net/nbia-api/series?Project={project_id}"
response = requests.get(url)
# 解析返回的 JSON 数据
data = response.json()
for item in data:
print(item['SeriesInstanceUID'])
注意: 上述代码仅为示例,实际使用需根据 TCIA API 文档调整。
如果以上方法均无效,建议联系 TCIA 技术支持团队:
| 步骤 | 内容 | |------|------| | 1 | 使用 Internet Explorer 或 Edge 浏览器访问 TCIA | | 2 | 禁用广告拦截插件 | | 3 | 安装并启用 Java 运行环境 | | 4 | 修改浏览器安全设置,允许弹出窗口和 JavaScript | | 5 | 使用 Python 脚本替代手动下载 | | 6 | 联系 TCIA 官方技术支持 |
如有更多细节(如具体错误提示、浏览器名称等),我可以进一步帮助你定位问题。祝你顺利下载数据!
分享 创建了问题
9月10日
创建了问题
9月10日


