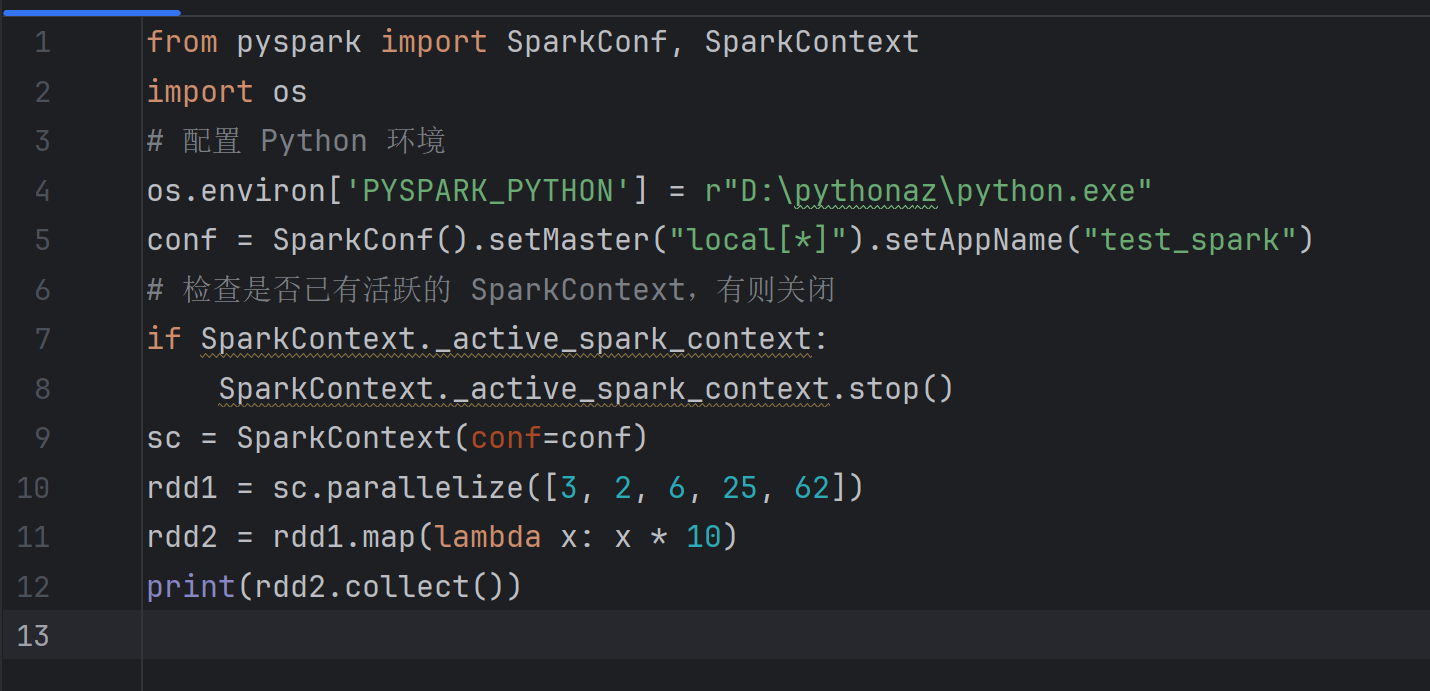
没有配置Hadoop环境,检查了Python.exe路径正确,问了ai不好使

 分享
分享
 关注
关注让【宝码香车】来帮您解答,本回答参考DeepSeek编写,并整理提供。
如果答案让您满意,请采纳、点赞、关注,非常感谢!
.
每日一句正能量,让它带给您好心情:你比你想象中更勇敢,比你看起来更强大。
.
这个错误通常与网络套接字连接有关,在PySpark本地模式下最常见的原因是Windows防火墙或网络配置问题。
从您的代码来看,主要问题可能出现在:
netsh advfirewall set allprofiles state off
运行代码后记得重新开启:
netsh advfirewall set allprofiles state on
修改您的代码,使用更基础的配置:
from pyspark import SparkConf, SparkContext
import os
# 设置Python路径
os.environ['PYSPARK_PYTHON'] = r"D:\pythonaz\python.exe"
# 简化配置
conf = SparkConf().setMaster("local").setAppName("test_spark")
# 确保先停止任何现有的SparkContext
if SparkContext._active_spark_context:
SparkContext._active_spark_context.stop()
# 创建SparkContext
sc = SparkContext(conf=conf)
# 修复代码中的拼写错误(rddl -> rdd1)
rdd1 = sc.parallelize([3, 2, 6, 25, 62])
rdd2 = rdd1.map(lambda x: x * 10) # 注意这里是rdd1不是rddl
print(rdd2.collect())
# 记得关闭
sc.stop()
Spark使用多个端口进行通信,检查是否有其他程序占用了这些端口。
对于新版本的PySpark,建议使用SparkSession:
from pyspark.sql import SparkSession
import os
os.environ['PYSPARK_PYTHON'] = r"D:\pythonaz\python.exe"
spark = SparkSession.builder \
.master("local") \
.appName("test_spark") \
.getOrCreate()
sc = spark.sparkContext
rdd1 = sc.parallelize([3, 2, 6, 25, 62])
rdd2 = rdd1.map(lambda x: x * 10)
print(rdd2.collect())
spark.stop()
rddl 应该是 rdd1如果以上方法都不能解决问题,建议:
希望这些解决方案能帮助您解决问题!
分享 创建了问题
9月21日
创建了问题
9月21日

