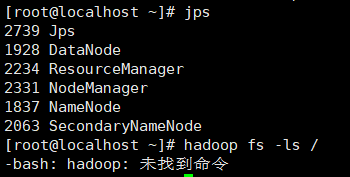
一张是/etc/profile的path配置图,另一张是启动完hadoop后却无法使用hadoop的图
收起
https://www.imooc.com/qadetail/128196
报告相同问题?


 分享
分享


