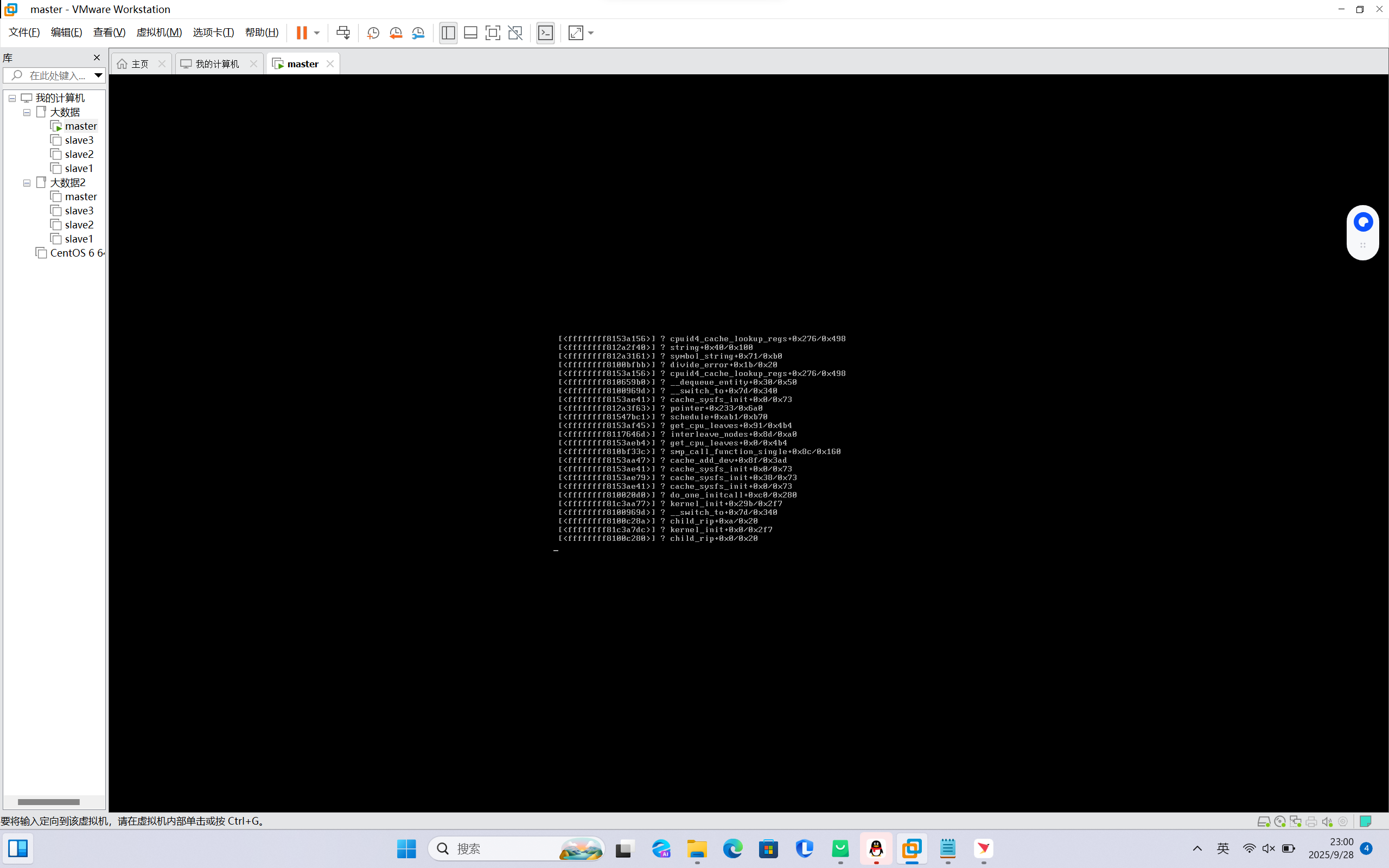
大家能帮我看看嘛?最近在学hadoop集群,然后用别人配置好的集群环境虚拟机master打不开,AI说什么内核崩溃,用他的办法修复也没弄好,排除硬件问题的话,有人能帮帮我吗?真的没办法了

 分享
分享
晚上好🌙🌙🌙
本答案参考通义千问
你提到的问题是关于 Hadoop 集群环境 中的 虚拟机(master 节点)无法启动,并提示“内核崩溃”或类似错误。这可能是由于多种原因引起的,比如:
下面我将从 排查步骤 和 解决方案 两个方面来详细说明,帮助你解决这个问题。
在开始修复之前,请先确认以下几点:
是否是虚拟机本身的问题?
是否是操作系统内核问题?
/var/log/kern.log 或 /var/log/messages)是否有内核错误信息。dmesg 命令查看内核崩溃日志。是否是网络配置问题?
是否是 Hadoop 配置问题?
core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml 等文件是否有错误。masters 和 slaves 文件中的节点名称是否正确。查看内核日志:
dmesg | tail -n 50
如果看到类似 kernel panic、out of memory、page fault 等关键字,说明是内核问题。
查看系统日志:
cat /var/log/syslog
cat /var/log/messages
重点: 如果发现 内存不足 或 磁盘空间不足 的错误,请尝试增加虚拟机内存或扩展磁盘空间。
内存不足 是导致内核崩溃的常见原因。
CPU 核心数:确保至少分配 2 核 CPU。
磁盘空间:确保 / 分区有至少 20GB 可用空间。
修改 core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
修改 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
修改 masters 文件:
master
修改 slaves 文件:
slave1
slave2
重点: 确保
masters和slaves文件中没有多余的空格或换行符。
如果你的虚拟机已经严重损坏,建议进行 重装:
下载 Hadoop 官方发行版(推荐 Apache Hadoop 3.x)
安装 Java(JDK 8 或以上)
sudo apt update
sudo apt install openjdk-8-jdk
配置 SSH 免密登录
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
解压 Hadoop 并配置环境变量
tar -zxvf hadoop-3.3.6.tar.gz -C /usr/local
echo 'export HADOOP_HOME=/usr/local/hadoop-3.3.6' >> ~/.bashrc
source ~/.bashrc
配置 hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
格式化 HDFS:
hdfs namenode -format
启动 Hadoop:
start-dfs.sh
start-yarn.sh
检查进程状态:
jps
应该看到以下进程:
| 错误类型 | 解决方案 |
|----------|----------|
| 内核崩溃 | 增加内存、检查磁盘空间、更换虚拟机镜像 |
| SSH 连接失败 | 确保 sshd_config 中允许 root 登录,关闭防火墙 |
| HDFS 启动失败 | 检查 core-site.xml 和 hdfs-site.xml 配置 |
| YARN 启动失败 | 检查 yarn-site.xml 和 mapred-site.xml |
hdfs-site.xml)<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
如果你愿意提供具体的错误日志或截图,我可以进一步帮你分析。
希望这些信息对你有帮助!如果还有疑问,欢迎继续提问。
分享 创建了问题
9月28日
创建了问题
9月28日


