在基于MSTAR SAR图像的目标识别任务中,常见问题是如何应对不同类别样本数量严重失衡的问题(如BMP2与T72坦克的不同配置样本数差异显著),导致模型偏向多数类、小样本类识别率低。该问题直接影响深度学习模型的泛化能力与分类公平性。传统数据增强方法对SAR图像特有的斑点噪声和视角敏感性适应性有限,如何结合合成少数类过采样技术(SMOTE)、生成对抗网络(GAN)或知识蒸馏等策略,在保持SAR物理特性的同时有效平衡样本分布,成为提升分类性能的关键技术挑战。


1条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以“评论”。如果答案让您满意,请“采纳”,非常感谢!
针对MSTAR SAR数据集中的类别不平衡问题,这是一个在目标识别任务中常见的挑战,尤其由于SAR图像特有的斑点噪声和视角敏感性,传统数据增强方法(如旋转、缩放)可能无法有效保持物理特性,导致模型泛化能力下降。以下将结合合成少数类过采样技术(SMOTE)、生成对抗网络(GAN)和知识蒸馏等策略,提供一套综合解决方案。解决方案优先考虑保持SAR图像的物理特性(如散射特征和纹理),同时平衡样本分布,提升小样本类的识别率。
问题分析
MSTAR SAR数据集包含多种军事目标(如BMP2和T72坦克),但不同类别的样本数量差异显著(例如,BMP2的某些配置样本多,而T72的变体样本少)。这种不平衡会导致深度学习模型偏向多数类,降低小样本类的分类精度。SAR图像的斑点噪声和视角变化进一步加剧了问题,因为传统增强方法可能引入不真实的伪影。
解决方法概述
解决类别不平衡的方法可分为数据层面和算法层面:
- 数据层面:通过重采样增加少数类样本或减少多数类样本,例如SMOTE及其变体(如Borderline-SMOTE)生成合成样本。
- 生成模型:使用GAN生成逼真的SAR图像,确保新样本保留原始数据的物理特性(如散射分布)。
- 知识蒸馏:利用在平衡数据上预训练的教师模型,指导学生模型处理不平衡数据,提升泛化能力。
- 混合策略:结合多种方法,例如先用GAN生成样本,再用代价敏感学习训练模型。
以下将详细说明关键方法,并提供代码示例和可视化。
关键方法详解
1. 合成少数类过采样技术(SMOTE)
SMOTE通过插值在少数类样本间生成新样本,适用于SAR图像,但需注意避免放大噪声。建议使用改进版本(如SMOTE-ENN)来清理噪声样本。
- 步骤:对每个少数类样本,找到其k近邻,随机选择邻居并生成线性插值样本。
- 适配SAR:在应用前,对SAR图像进行去噪预处理(如使用Lee滤波),以确保生成样本的物理合理性。
Python代码示例(使用imbalanced-learn库):
from imblearn.over_sampling import SMOTE from sklearn.model_selection import train_test_split import numpy as np # 假设X和y是预处理后的SAR图像特征和标签(numpy数组) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 应用SMOTE过采样 smote = SMOTE(random_state=42) X_resampled, y_resampled = smote.fit_resample(X_train, y_train) print("原始训练集样本分布:", np.bincount(y_train)) print("过采样后样本分布:", np.bincount(y_resampled))2. 生成对抗网络(GAN)
GAN能生成高质量SAR图像,但需要设计条件GAN(cGAN)以控制类别,并加入约束(如梯度惩罚)来保持物理特性。训练时,使用真实SAR图像的 patches 作为输入,确保生成样本的纹理和噪声分布与原始数据一致。
- 步骤:训练生成器生成少数类样本,判别器区分真实与生成样本;通过对抗过程优化。
- 适配SAR:在损失函数中加入感知损失或物理约束(如散射一致性),以保持SAR特性。
Python代码示例(使用TensorFlow/Keras):
import tensorflow as tf from tensorflow.keras.layers import Dense, Reshape, Conv2D, LeakyReLU from tensorflow.keras.models import Sequential # 简单GAN生成器示例(针对SAR图像) def build_generator(): model = Sequential([ Dense(128 * 8 * 8, input_dim=100), Reshape((8, 8, 128)), Conv2D(64, kernel_size=4, strides=2, padding='same'), LeakyReLU(alpha=0.2), Conv2D(1, kernel_size=4, strides=2, padding='same', activation='tanh') # 输出SAR图像 ]) return model # 注意:实际应用中需使用条件GAN,并加载MSTAR数据集进行训练 generator = build_generator() # 训练代码略(需结合判别器和优化器)3. 知识蒸馏
通过教师-学生框架,教师模型在平衡数据(如过采样后)上训练,学生模型在不平衡数据上学习教师的软标签,从而提升小样本类性能。
- 步骤:先使用SMOTE或GAN创建平衡数据集训练教师模型;然后,学生模型在原始不平衡数据上蒸馏学习。
- 适配SAR:在蒸馏损失中加入特征对齐项,以保留SAR特有的空间特征。
Python代码示例(使用PyTorch):
import torch import torch.nn as nn # 定义知识蒸馏损失 class DistillationLoss(nn.Module): def __init__(self, temperature=3): super().__init__() self.temperature = temperature self.kl_loss = nn.KLDivLoss() def forward(self, student_logits, teacher_logits): student_probs = torch.log_softmax(student_logits / self.temperature, dim=1) teacher_probs = torch.softmax(teacher_logits / self.temperature, dim=1) return self.kl_loss(student_probs, teacher_probs) # 假设teacher_model和student_model已定义 distillation_loss = DistillationLoss() # 训练循环中结合蒸馏损失和原始交叉熵损失整体解决方案流程
为了直观展示从数据预处理到模型评估的完整流程,以下使用mermaid图形描述关键步骤。该流程强调在保持SAR物理特性的前提下,综合应用多种方法。
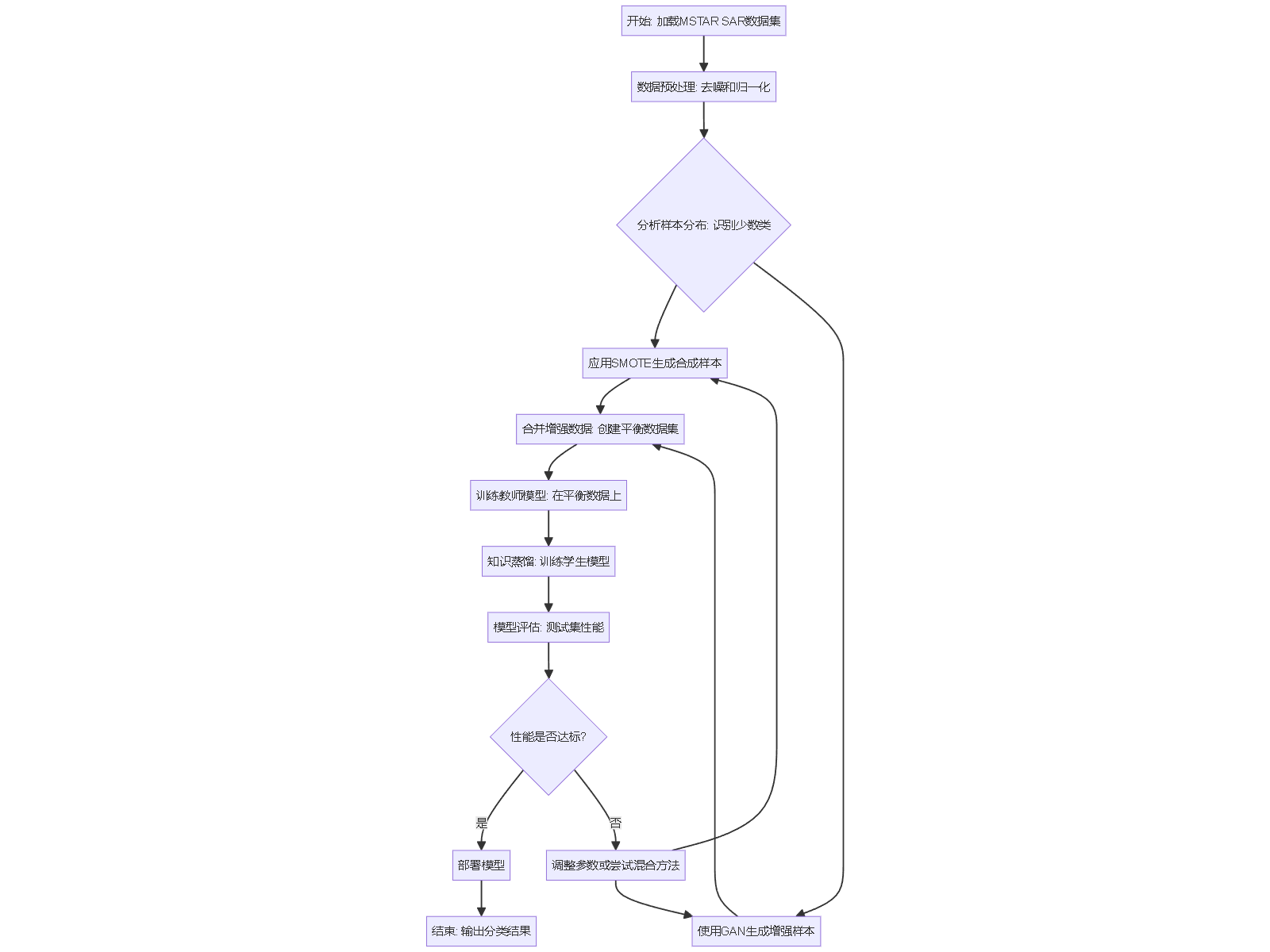
最佳实践与注意事项
- 验证生成样本质量:使用定量指标(如FID分数)评估GAN生成样本的逼真度,或通过可视化检查纹理一致性。
- 避免过拟合:在应用SMOTE或GAN后,使用交叉验证评估模型,并结合正则化技术。
- 混合方法优先:例如,先使用SMOTE快速平衡数据,再用GAN细化生成样本,最后通过知识蒸馏提升鲁棒性。
- SAR特性保持:在所有步骤中,确保数据增强不破坏斑点噪声模式,可通过物理启发式约束实现。
通过上述方法,能有效缓解MSTAR SAR数据集的类别不平衡问题,提升模型在少数类上的识别率,同时维护分类公平性。实际应用中,建议根据具体数据分布调整参数,并持续监控模型性能。
解决 无用评论 打赏举报 分享
分享
- 2022-07-14 04:42《MSTAR官方数据集:深度探索SAR图像识别与分类》 SAR(Synthetic Aperture Radar)合成孔径雷达图像是一种重要的遥感图像类型,它不受天气和光照条件限制,能在夜间和恶劣天气下获取地表信息。MSTAR(Maneuvering ...
- 2021-10-03 11:06《SAR数据集详解——以MSTAR-10-test为例》 SAR(Synthetic Aperture Radar)合成孔径雷达是一种遥感技术,它利用雷达波进行地球表面的探测,不受光照条件限制,能获取全天候、全天时的高分辨率图像。在军事、地质...
- 2019-05-11 09:33史上最全MSTAR数据集,百度网盘永久有效,2.28Gb整。
- 2021-10-02 17:52与光学遥感相比,SAR不受天气条件和光照影响,能在夜间或云雾天气下工作,具有全天时、全天候的特点。在军事、地质勘探、环境监测等领域有着广泛的应用。 **MSTAR项目与MSTAR数据集** MSTAR(Microstrip Array ...
- 2018-11-29 22:00【只能在Linux下用】MSTAR数据集中的tool中包含了雷达的二进制格式转JPEG的编译文件,mstar2jpeg.为了方便处理图像,采用Python语言,调用Linux下的shell命令,整个1万多雷达二进制格式文件转为JPEG仅用了1分30秒。
- 2025-05-27 03:00MSTAR数据集是专门用于合成孔径雷达(SAR)图像识别的重要资源,在机器学习和计算机视觉领域扮演着关键角色。它由美国国防高级研究计划局(DARPA)创建,全称为“Moving and Stationary Target Acquisition and ...
- 2021-11-27 22:40MSTAR目标检测SAR数据集汇总,内涵2G数据,baidu网盘下载
- 2020-04-04 16:37由于SAR图像的复杂性,它们通常包含多种纹理、形状和反射特性,这使得对SAR图像的分析和理解成为一项挑战,因此,MSTAR数据集的建立对于解决这个问题提供了宝贵的训练和验证数据。 在【描述】中提到,MSTAR数据集被...
- 2022-07-14 23:34该实验数据采用美国国防高等研究计划署(DARPA)支持的MSTAR计划所公布的实测SAR地面静止目标数据,无论是在国内还是国际上,针对SAR图像目标识别的研究基本上是基于该数据集而展开的。采集该数据集的传感器为高分辨率...
- 2025-04-26 14:37常韧晏Zane的博客 MSTAR SAR 数据集详细介绍 【下载地址】MSTARSAR数据集详细介绍 “MSTAR SAR 数据集”是史上最全的MSTAR数据集,包含2.28Gb的高质量资源,覆盖多种场景和目标,满足不同研究需求。数据集经过严格筛选,确保...
- 2025-11-22 16:14为了提高模型对新图像的泛化能力,作者还应用了图像增强技术,例如对原始图像进行旋转、缩放和裁剪等处理,从而在不改变图像类别的情况下增加数据集的多样性。 文章中详细记录了网络的构建过程,包括每层的设计选择...
- 2023-09-06 17:05MSTAR(Mobile Synthetic Aperture Radar Target)数据集,是合成孔径雷达(SAR)领域内广泛使用的大型数据集,由美国桑迪亚国家实验室通过SAR传感器平台采集。这个数据集的创建是为了支持国防高级研究计划局和空军...
- 2018-09-11 15:17MSTAR数据集,用于检验SAR图像目标识别算法的效果,内附转换JPG,TIFF代码
- 2018-11-13 20:01MSTAR 数据集是由美国国防高等研究计划署(Defense Advanced Research Projects Agency, DARPA)支持的 MSTAR 计划所发布的实测合成孔径雷达(Synthetic Aperture Radar, SAR)地面静止目标数据集。该数据集主要应用...
- 2022-06-28 00:15用于SAR ATR的标准数据集,MSTAR数据集(百度网盘);完整数据集
- 2022-09-25 00:13**MSTAR数据集详解** MSTAR(Multiple Sensor Target Recognition)数据集是计算机视觉领域中一个重要的多传感器目标识别资源,主要用于研究目标检测、识别和跟踪技术。这个数据集由美国空军研究实验室(AFRL)发布...
- 2026-04-12 02:00适配MSTAR标准数据集,包含1476×1784尺寸原始场景图,所有嵌入目标均来自同源机载SAR系统(0.3m分辨率),确保成像一致性。资源包内置完整工具链:region_grow.py用于区域生长辅助标注,Binary_image.py生成二值掩...
- 2023-04-13 15:35该实验数据采用美国国防高等研究计划署(DARPA)支持的MSTAR计划所公布的实测SAR地面静止目标数据,无论是在国内还是国际上,针对SAR图像目标识别的研究基本上是基于该数据集而展开的。采集该数据集的传感器为高分辨率...
- 没有解决我的问题, 去提问


问题事件
创建了问题 10月9日