要求创建一个名叫normalized的函数
输入score之后每个人的平均分和科目平均分会出来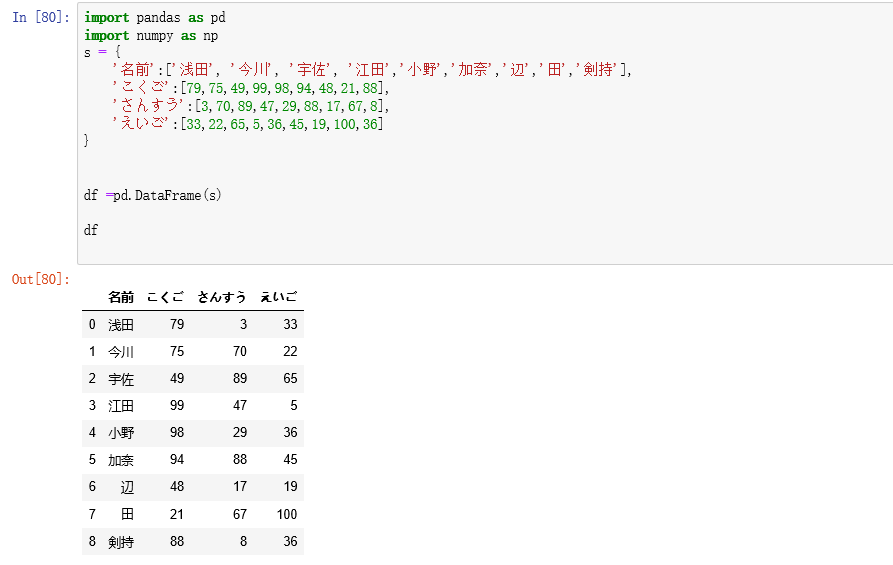

没有学过python 所以不是很能理解函数和Dataframe的用法

要求创建一个名叫normalized的函数
输入score之后每个人的平均分和科目平均分会出来
没有学过python 所以不是很能理解函数和Dataframe的用法
 分享
分享
# Import
import pandas as pd
# Specify Info
data = {'姓名':['周杰伦','林俊杰','陈信宏','丁彦仪','杜兰特'],
'语文':[79,65,64,54,24],
'数学':[75,54,65,58,67],
'英语':[56,46,87,45,95]}
df = pd.DataFrame(data)
'''
第一步是导入数据,导入数据的方式有很多种。
1. 我们这里采用的是数据导入的形式是我们自己手动输入生成一个【字典】,这个字典当中
包含了四个key-value对,他们分别是‘姓名’、‘语文’、‘数学’、‘英语’,这些就是
他们的key,而value以列表的形式呈现分别表明了这五位同学在每一科上的得分
2. 你也可以通过导入文件的形式导入数据,形如 pd.read_csv('file.csv')
总之,都是要将数据规整好,随后放入我们的DataFrame
'''

上图显示了我们创建的这个DataFrame的格式
# Def
def normalized(df):
subject_list = df.columns.to_list()
subject_list.remove('姓名')
for subject in subject_list:
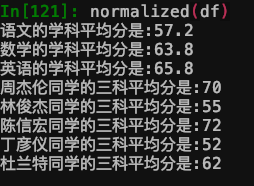
print(f'{subject}的学科平均分是:{df[subject].mean()}')
for name in df['姓名'].to_list():
print(f'{name}同学的三科平均分是:'+str(int(df[df['姓名']==name].mean(1))))
'''
第二步我们来定义你提到的normalized函数。
在这个函数中我们只需要输入一个参数,也就是指定你所要分析DataFrame
针对于输入的df,该函数会首先遍历每一个学科,打印每一学科的平均分;接着会遍历每一位同学,
打印每一位同学的三科的平均分
对于Python的基本知识以及DataFrame知识的组合运用是数据分析当中的关键,如果你想进一步
了解Pandas的使用可以随时与我交流,希望帮助到你。
'''
分享




