问题描述:我希望爬取一个网站上的数据,数据量较大,希望获得较为方便的方法。
网址:http://43.143.27.63/
问题具体描述:
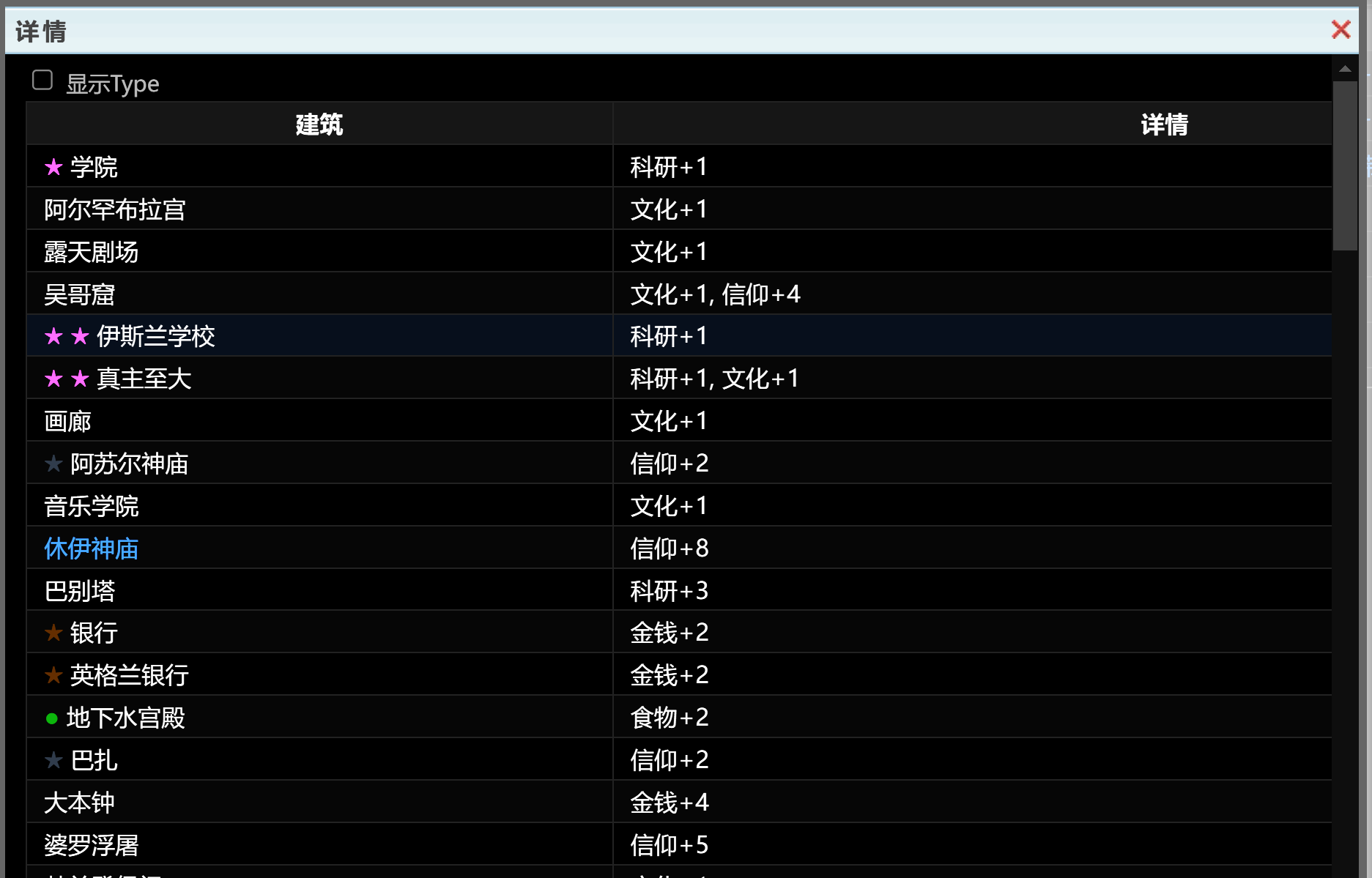
进入网页后,点击蓝色字体弹出一个表格
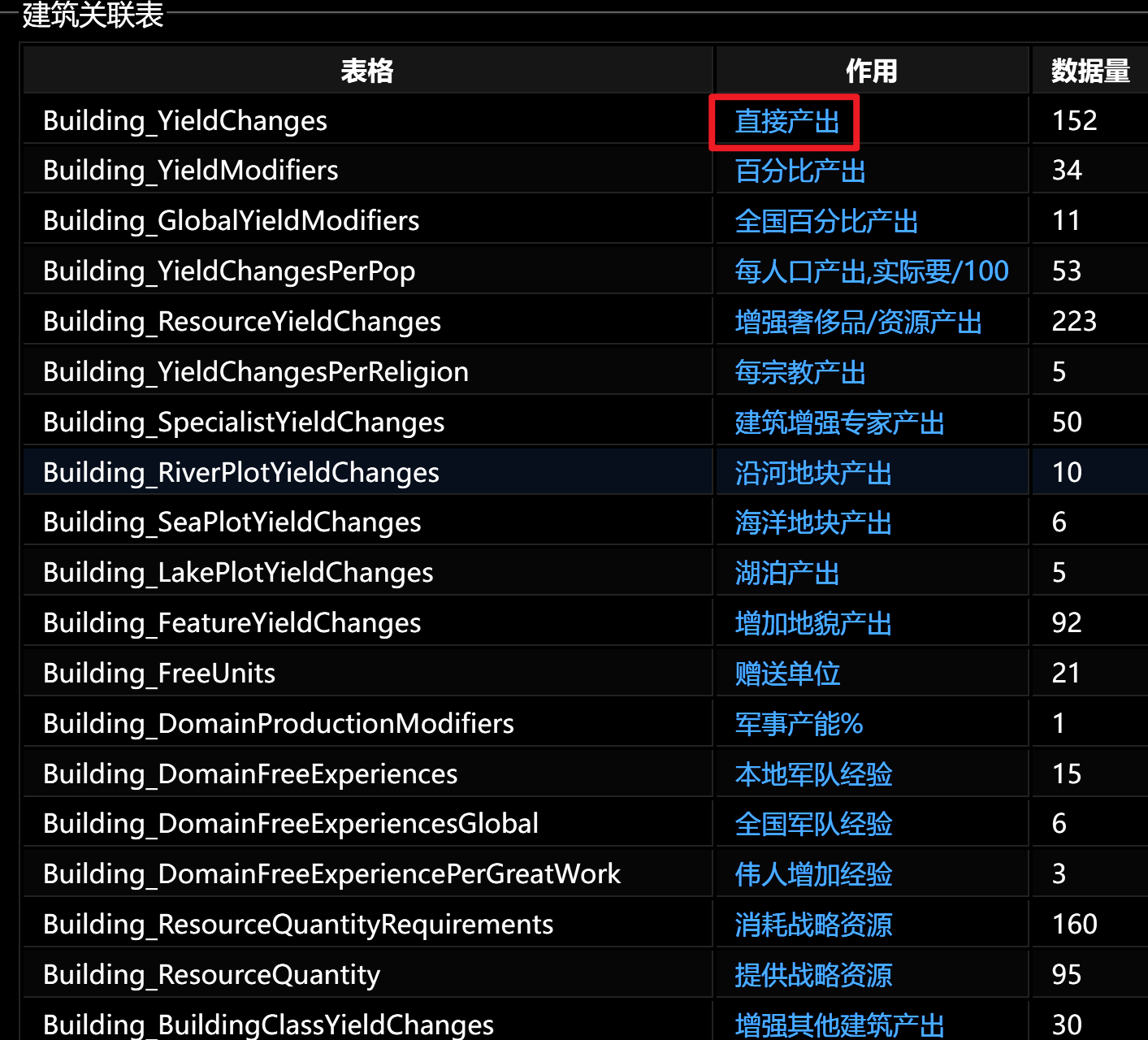
表格如图,如何才能批量爬取所有表格的内容呢?

问题描述:我希望爬取一个网站上的数据,数据量较大,希望获得较为方便的方法。
网址:http://43.143.27.63/
问题具体描述:
进入网页后,点击蓝色字体弹出一个表格
表格如图,如何才能批量爬取所有表格的内容呢?
 分享
分享
阿里嘎多学长整理AIGC生成,因移动端显示问题导致当前答案未能完全显示,请使用PC端查看更加详细的解答过程
解决方案
根据你的描述,似乎你需要使用爬虫技术来批量爬取网站上的数据。具体来说,你需要解决以下几个问题:
推荐解决方案
import scrapy
from scrapy_splash import SplashRequest
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = [
'http://43.143.27.63/',
]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url, self.parse, args={'wait': 0.5})
def parse(self, response):
# 模拟点击蓝色字体弹出表格的操作
# ...
# 获取表格数据
# ...
import scrapy
from bs4 import BeautifulSoup
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = [
'http://43.143.27.63/',
]
def parse(self, response):
# 解析HTML页面并提取表格数据
soup = BeautifulSoup(response.body, 'html.parser')
table = soup.find('table') # 找到表格
rows = table.find_all('tr') # 找到表格中的行
for row in rows:
# 提取表格中的数据
# ...
注意
分享 创建了问题
10月22日
创建了问题
10月22日


