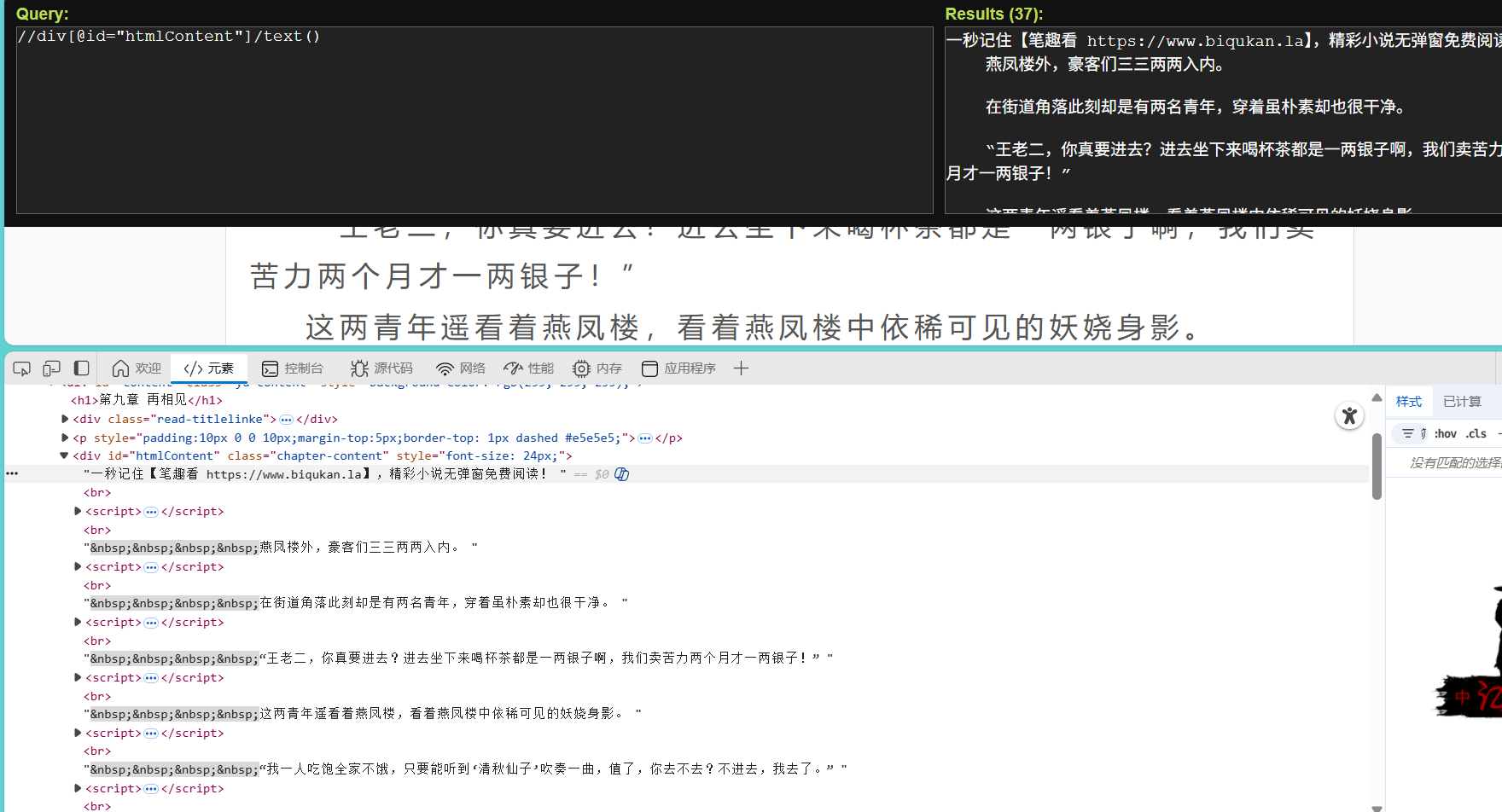
在python中 获取div标签下方的文本信息,在xpath中显示是可以的,有内容,但是写到代码里运行却没有内容,是为什么?
import requests #导入requests模块
from lxml import etree #导入etree模块
#定义字符串chapter_url
chapter_url = 'https://www.biqukan.la/book/4273/3062821.html'
r = requests.get(chapter_url) #发送请求,并将返回结果赋值给r
html = etree.HTML(r.text) #创建HTML对象html
print(r.text)
#选择h1节点并提取文本,将返回的列表第一项赋值给title
title = html.xpath('//h1/text()')[0]
print(title) #输出标题
#选择id属性值为“htmlContent”的div节点并提取文本
contents = html.xpath('//div[@id="htmlContent"]/text()')
for i in contents: #遍历列表
#移除字符串头尾的空格,并赋值给content
content = i.strip()
print(content) #输出正文