
我有一个由3台服务器组成的Flink集群,用的standalone模式,每个服务器开启了5个slot,一共15个slot
Flink集群用来处理试验大数据任务,整个任务时先接收来自Kafka的数据,然后进行数据处理。数据处理首先会先对数据进行识别,然后通过mysql的数据连接池到数据库查询计算参数,如果计算参数不变则根据已有的计算类中的静态变量进行数据计算,如果计算参数改变了,则将计算参数重新存入计算类的静态变量,然后继续计算。整个集群就处理这一个任务。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
String topicName="lkcan1";
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, ConfigConstant.KAFKA_BOOTSTRAP_SERVERS);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test-group1");
properties.setProperty("flink.partition-discovery.interval-millis","30000");
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,ConfigConstant.KAFKA_AUTO_OFFSET_RESET);
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(topicName, new SimpleStringSchema(), properties);
DataStream<String> stream = env.addSource( consumer);
stream.flatMap(new FlatMapFunction<String, ArrayList<Put>>(){
@Override
public void flatMap(String value, Collector<ArrayList<Put>> out) throws Exception {
log.info("已接收到数据;{}","lkcan1");
LkCommonHandler.handler(topicName,value);
}
}).setParallelism(ConfigConstant.parallelism);
当我把任务的算子平行度设置为1时(只使用到服务器1的slot),计算的速度很快,每一组流数据处理差不多10S左右
2025-11-01 16:45:24,551 INFO flink.handler.lk.LkSensorHandler [] - 数据写入数据库完成,时长:1
2025-11-01 16:45:24,552 INFO flink.handler.lk.LkCommonHandler [] - 数据处理完毕,时长:11
当我把任务的算子平行度设置为5时(只使用到服务器1的slot),计算的速度就很慢了,每一组流数据处理差不多90S左右
25-11-01 16:56:57,449 INFO flink.handler.lk.LkSensorHandler [] - 数据写入数据库完成,时长:1
2025-11-01 16:56:57,449 INFO flink.handler.lk.LkCommonHandler [] - 数据处理完毕,时长:90
当我把任务的算子平行度设置为15时(占用所有slot),计算的速度更慢,每一组流数据处理差不多110S左右
025-11-01 17:17:43,955 INFO flink.handler.lk.LkSensorHandler [] - 数据写入数据库完成,时长:2
2025-11-01 17:17:43,956 INFO flink.handler.lk.LkCommonHandler [] - 数据处理完毕,时长:116
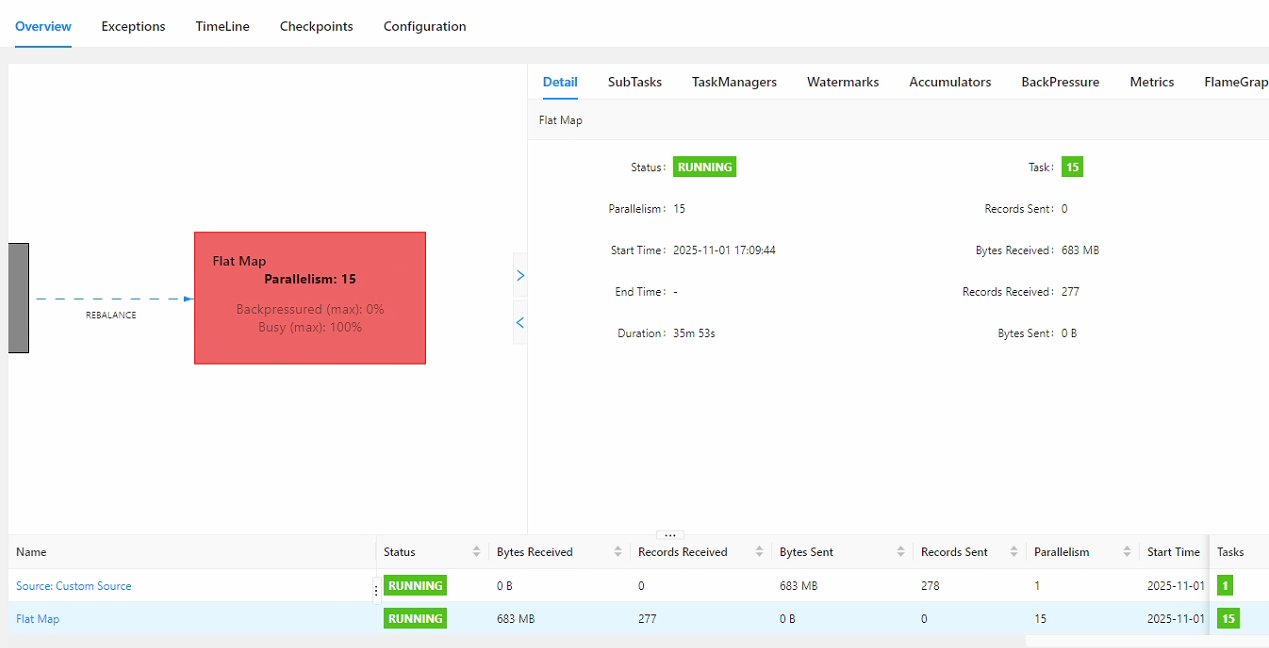
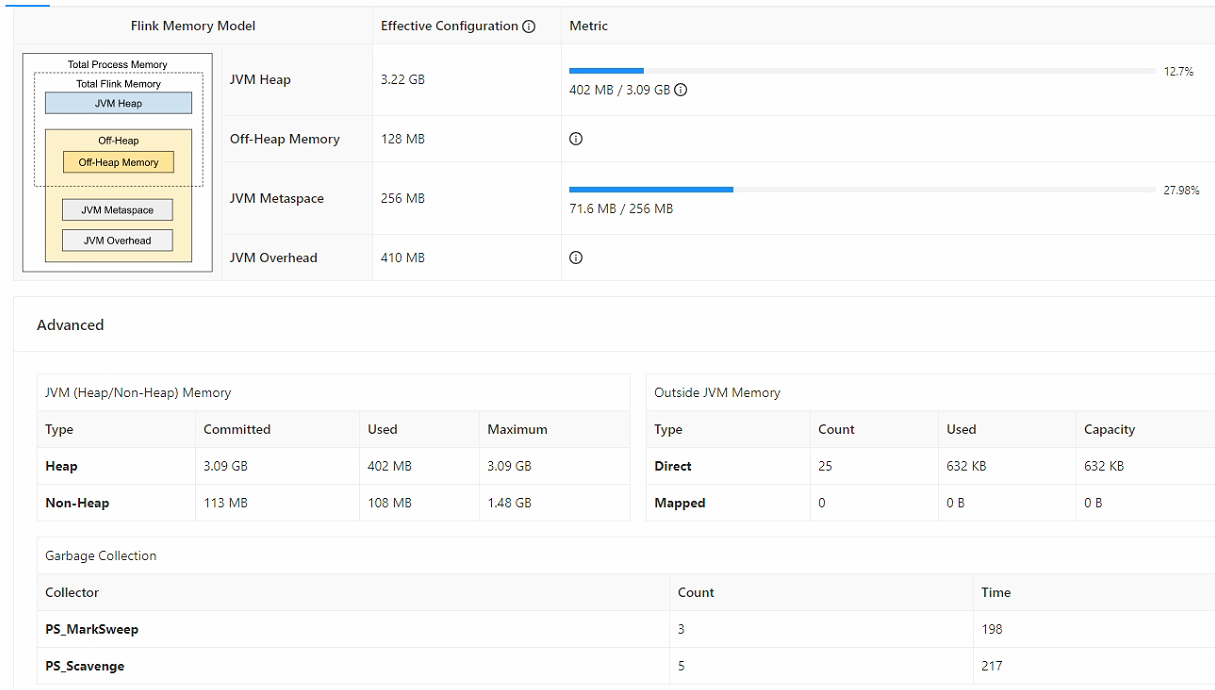
如果我把整个任务拆分为15个任务,对应分别接收15个kafka的topic进行数据处理,则单个数据的处理时间大约为30S左右
请教下应该如何解决整个速度慢的问题?谢谢!






