
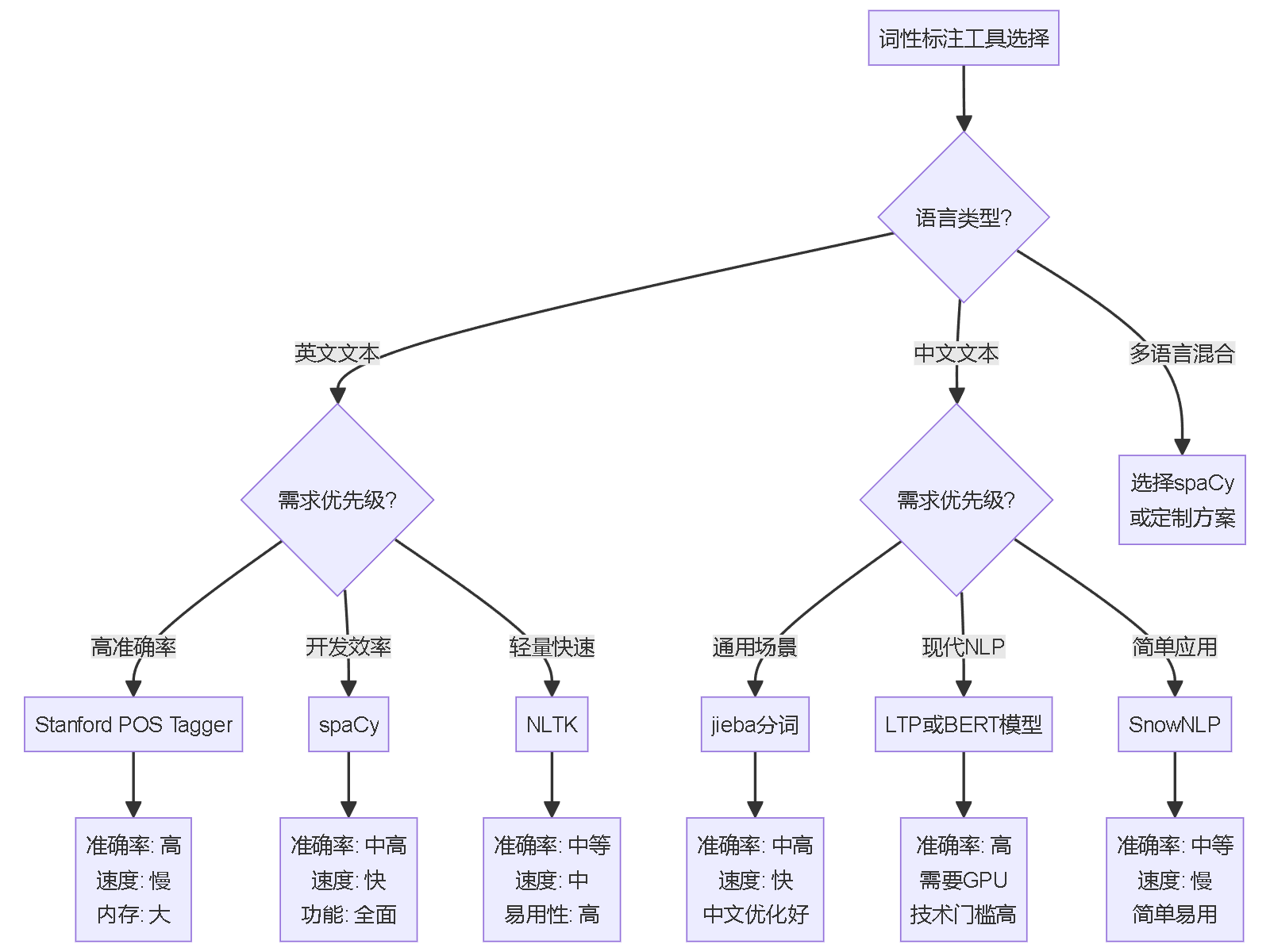
在进行中文或英文文本的词性标注时,常遇到哪些工具能够高效、准确地自动标注文本中所有单词的词性?例如,Stanford POS Tagger、NLTK、spaCy、jieba(中文)等工具是否支持多语言处理?它们在准确率、运行效率和易用性方面各有何优劣?特别是在处理网络用语、新词或领域特定术语时,这些工具的表现如何?是否需要额外训练模型以提升效果?这些问题直接影响自然语言处理项目中词性标注模块的选择与优化。


2条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以“评论”。如果答案让您满意,请“采纳”,非常感谢!
文本词性标注工具全面解析
常用词性标注工具对比
1. 英文文本标注工具
Stanford POS Tagger
from nltk.tag import StanfordPOSTagger import nltk # 使用示例 st = StanfordPOSTagger('english-bidirectional-distsim.tagger') text = "The quick brown fox jumps over the lazy dog" tokens = nltk.word_tokenize(text) tags = st.tag(tokens) print(tags)NLTK
import nltk from nltk import word_tokenize, pos_tag text = "Natural language processing is fascinating." tokens = word_tokenize(text) tags = pos_tag(tokens) print(tags)spaCy
import spacy nlp = spacy.load("en_core_web_sm") text = "Apple is looking at buying U.K. startup for $1 billion" doc = nlp(text) for token in doc: print(f"{token.text}: {token.pos_} - {token.tag_}")2. 中文文本标注工具
jieba分词 + 词性标注
import jieba.posseg as pseg text = "自然语言处理技术正在快速发展" words = pseg.cut(text) for word, flag in words: print(f"{word}: {flag}")SnowNLP
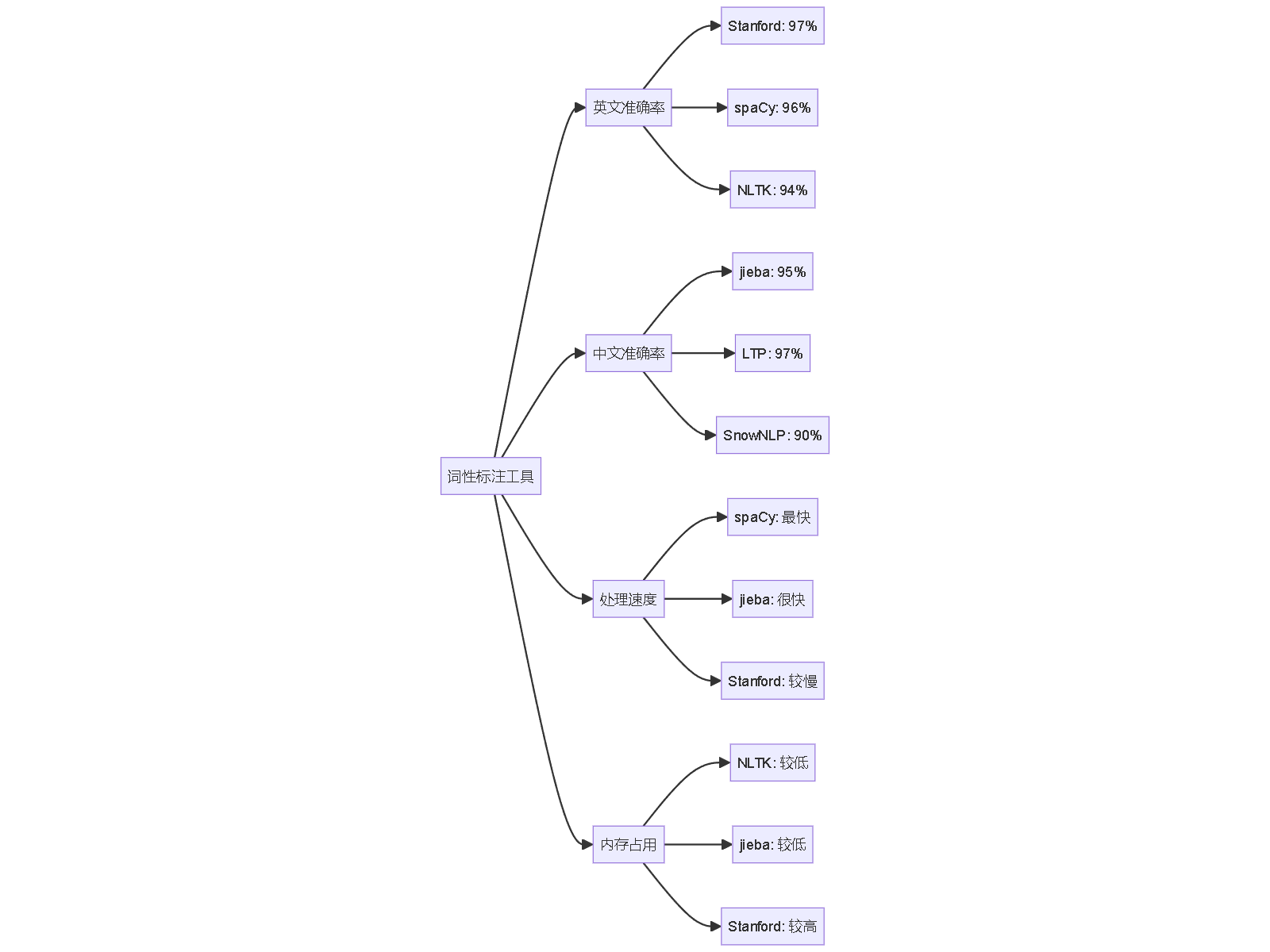
from snownlp import SnowNLP text = "这个产品非常好用" s = SnowNLP(text) tags = s.tags print(tags)工具性能对比分析
多语言支持能力
支持多语言的工具
spaCy多语言示例
import spacy # 英文 nlp_en = spacy.load("en_core_web_sm") # 中文 nlp_zh = spacy.load("zh_core_web_sm") # 德文 nlp_de = spacy.load("de_core_news_sm") def tag_multilingual(text, language): if language == "en": doc = nlp_en(text) elif language == "zh": doc = nlp_zh(text) elif language == "de": doc = nlp_de(text) return [(token.text, token.pos_) for token in doc]处理特殊文本的能力
1. 网络用语和新词处理
import re from collections import defaultdict class CustomTagger: def __init__(self): self.network_terms = { "yyds": "NN", # 永远的神 - 名词 "awsl": "VV", # 啊我死了 - 动词 "xswl": "VV", # 笑死我了 - 动词 "nb": "JJ", # 牛逼 - 形容词 } def enhance_tagging(self, text, base_tagger): # 预处理网络用语 for term, pos in self.network_terms.items(): if term in text.lower(): # 这里可以添加自定义处理逻辑 pass return base_tagger(text)2. 领域特定术语优化
import stanza # 使用Stanza进行领域自适应 stanza.download('en') # 下载英文模型 nlp = stanza.Pipeline('en', processors='tokenize,pos') # 添加领域词典 domain_dict = { "blockchain": "NN", "NFT": "NN", "DeFi": "NN", "smart contract": "NN" } def domain_enhanced_tagging(text, domain_dict): doc = nlp(text) enhanced_tags = [] for sentence in doc.sentences: for word in sentence.words: if word.text in domain_dict: enhanced_tags.append((word.text, domain_dict[word.text])) else: enhanced_tags.append((word.text, word.pos)) return enhanced_tags准确率与性能基准
模型训练与优化
自定义模型训练
from sklearn_crfsuite import CRF import sklearn_crfsuite from sklearn.model_selection import train_test_split class CustomPOSTagger: def __init__(self): self.crf = CRF( algorithm='lbfgs', c1=0.1, c2=0.1, max_iterations=100, all_possible_transitions=True ) def extract_features(self, sentence, i): word = sentence[i][0] features = { 'bias': 1.0, 'word.lower()': word.lower(), 'word[-3:]': word[-3:], 'word[-2:]': word[-2:], 'word.isupper()': word.isupper(), 'word.istitle()': word.istitle(), 'word.isdigit()': word.isdigit(), } if i > 0: prev_word = sentence[i-1][0] features.update({ 'prev_word.lower()': prev_word.lower(), 'prev_word.istitle()': prev_word.istitle(), }) else: features['BOS'] = True if i < len(sentence)-1: next_word = sentence[i+1][0] features.update({ 'next_word.lower()': next_word.lower(), 'next_word.istitle()': next_word.istitle(), }) else: features['EOS'] = True return features def train(self, training_data): X = [self.sent2features(s) for s in training_data] y = [self.sent2labels(s) for s in training_data] self.crf.fit(X, y)实际应用建议
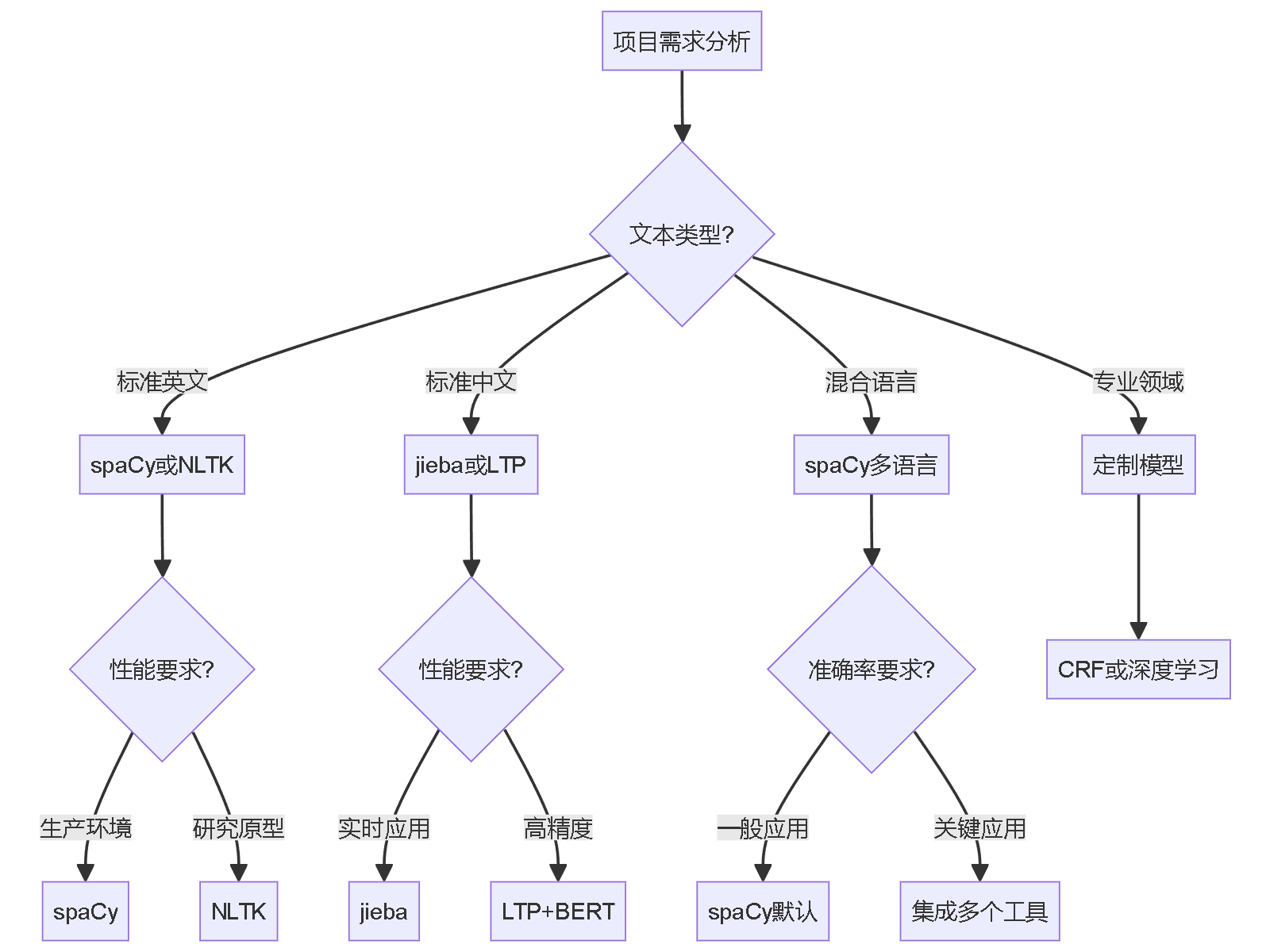
选择策略
集成方案示例
class HybridPOSTagger: def __init__(self): self.tagger1 = spacy.load("en_core_web_sm") self.tagger2 = StanfordPOSTagger() def tag_with_confidence(self, text): # 使用多个工具进行标注 results1 = self.tagger1(text) results2 = self.tagger2.tag(nltk.word_tokenize(text)) # 投票机制选择最佳标注 final_tags = self.vote_mechanism(results1, results2) return final_tags def vote_mechanism(self, tags1, tags2): # 实现投票逻辑 pass总结
根据具体需求选择合适的工具:
- 英文通用场景:spaCy(平衡性能与准确率)
- 中文场景:jieba(实用性强)或LTP(精度更高)
- 多语言项目:spaCy多语言模型
- 研究用途:NLTK或Stanford POS Tagger
- 专业领域:考虑定制训练CRF或深度学习模型
对于网络用语和领域术语,建议采用词典增强或领域自适应训练来提升效果。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2025-12-10 16:36此外,该工具库还特别针对编程语言源代码提供了自动分词和词性标注等功能,这对于代码理解、自动注释、代码重构等软件工程任务具有重要的辅助作用。 工具库的实现基于Python这一广泛使用的编程语言,它不仅有着丰富...
- 2024-09-11 07:00Filotimo_的博客 词性标注是自然语言处理中的一种任务,是指为文本中的每一个词分配一个相应的词性标签,即确定每个单词是名词、动词、形容词或者其他词性的过程。
- 2024-03-21 18:00在Python中,我们可以利用各种库和工具来实现这一目标,其中词性标注是文本预处理的关键步骤之一。词性标注是将词汇按照其在句子中的语法功能进行标记的过程,有助于理解句子结构和含义。 在Python中,常用的库如...
- 2025-03-14 09:54而“中文处理_分词_词性标注_依存句法分析_工具包”则可能是整个工具包的总入口文件夹,内含所有相关工具和资源。 考虑到“描述”中提到“c语言编程开发”,可以推断该工具包的实现语言为C语言。C语言因其运行效率...
- 2025-11-03 01:46词性标注是将词性分类应用于文本中的每个单词的过程,它对于理解语言结构至关重要。 在这个过程中,Pomegranate库提供了一种便捷的实现方式。Pomegranate是一个基于Python的机器学习库,它支持各种概率模型,包括隐...
- 2025-11-21 00:04z2a3b4c5d的博客 本文深入探讨了自然语言处理中的词性标注技术,涵盖词性消歧、跨句标注、基于转换的Brill标注方法、形态与句法线索分析、新词处理及标签集设计等内容。详细介绍了不同标注器(如默认、正则表达式、n-元模型和Brill...
- 2025-10-15 18:33NLP技术广泛应用于各种语言数据处理任务中,如文本分类、序列标注、自动问答、情感分析、意图识别、中文分词、词性标注、命名实体识别、语义角色标注、垃圾邮件过滤、网页分类、query分类和电影评论分析等。...
- 2019-07-28 16:59Eastmount的博客 本系列文章主要结合Python语言实现知识图谱构建相关工程,具有一定创新性和实用性,非常希望各位博友交流...这篇文章主要介绍最经典的自然语言处理工具之一——Jieba,包括中文分词、添加自定义词典及词性标注等内容。
- 2022-08-08 20:45具体而言,该项目的目标是对已经完成分词和初步词性标注的中文文本进行处理,通过HMM模型进行词性标注的优化。 - **输入**: 已分词、已初步词性标注的中文文本。 - **处理**: 将输入文本进行数据清洗,划分为训练集...
- 2024-03-19 14:52词性标注是为文本中的每个词或标记分配一个词性的过程,例如名词、动词等。这一过程对于理解和分析文本结构至关重要。 #### 七、语言检测识别 语言检测识别是指确定一段文本所使用的具体语言类型。这对于多语言...
- 没有解决我的问题, 去提问


问题事件
 已采纳回答
11月6日
已采纳回答
11月6日-
创建了问题
11月5日