
在字节跳动收购Musical.ly后,如何实现TikTok与Musical.ly的技术架构融合成为关键挑战。两大平台分别基于不同的技术栈和数据中心部署:Musical.ly主要面向欧美用户,架构集中于AWS云环境;而字节跳动国内系统则依赖自建IDC和私有云体系。融合过程中,常见的技术问题是如何统一数据存储与同步机制,特别是在用户行为数据、内容推荐模型和实时互动功能上实现跨区域、低延迟的数据一致性。此外,推荐算法系统的整合也面临挑战——如何将字节跳动成熟的Feed流引擎适配到原Musical.ly的用户画像体系中,在保障性能的同时提升海外用户的内容匹配精准度?


2条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以“评论”。如果答案让您满意,请“采纳”,非常感谢!
字节跳动收购Musical.ly后的技术架构融合方案
作为资深开发者,我来分析字节跳动收购Musical.ly后实现技术架构融合的关键策略。这个融合过程涉及多个技术层面,我将从数据存储同步、推荐算法整合和系统架构设计三个方面进行详细解答。
1. 数据存储与同步机制
跨区域数据一致性解决方案
核心技术栈选择:
- 分布式数据库:Cassandra、CockroachDB
- 消息队列:Apache Kafka、AWS Kinesis
- 数据同步:Debezium、Airbyte
- 缓存层:Redis Cluster
统一数据同步实现:
import json import boto3 from kafka import KafkaProducer from datetime import datetime class DataSyncManager: def __init__(self): self.kafka_producer = KafkaProducer( bootstrap_servers=['kafka-cluster:9092'], value_serializer=lambda v: json.dumps(v).encode('utf-8') ) self.dynamodb = boto3.resource('dynamodb', region_name='us-east-1') def sync_user_behavior(self, user_id, action, metadata): """同步用户行为数据""" sync_data = { 'user_id': user_id, 'action': action, 'metadata': metadata, 'timestamp': datetime.utcnow().isoformat(), 'source': 'musically_legacy', 'target': 'tiktok_unified' } # 发送到Kafka进行实时处理 self.kafka_producer.send('user-behavior-sync', sync_data) # 同时写入DynamoDB作为备份 table = self.dynamodb.Table('user_behavior_backup') table.put_item(Item=sync_data) def batch_sync_content_data(self, content_batch): """批量同步内容数据""" # 实现分片同步逻辑 for content in content_batch: self._sync_single_content(content) def _sync_single_content(self, content): # 数据转换和标准化 standardized_content = self._standardize_content_format(content) # 发送到统一数据管道 self.kafka_producer.send('content-sync', standardized_content)跨区域数据同步流程:
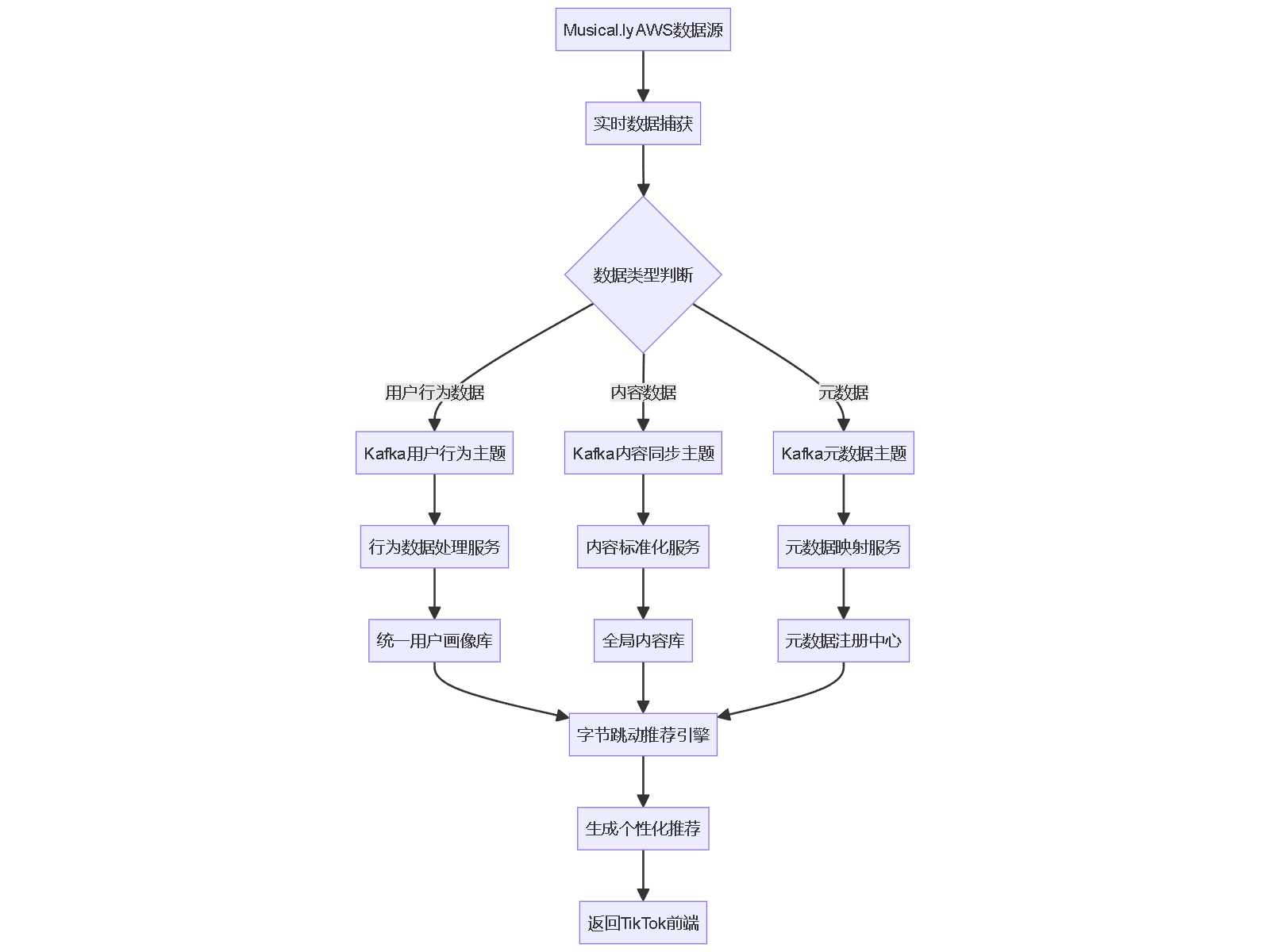
2. 推荐算法系统整合
算法融合策略
技术架构升级:
import tensorflow as tf import pandas as pd from sklearn.preprocessing import StandardScaler import joblib class UnifiedRecommendationEngine: def __init__(self): self.user_profile_model = self._load_user_profile_model() self.content_embedding_model = self._load_content_embedding_model() self.fusion_predictor = self._load_fusion_predictor() def _load_user_profile_model(self): """加载字节跳动用户画像模型""" # 迁移学习:适配海外用户特征 return tf.keras.models.load_model('byte_dance_user_model.h5') def _load_content_embedding_model(self): """加载内容嵌入模型""" return tf.keras.models.load_model('content_embedding_model.h5') def adapt_for_global_users(self, user_features, region_weight=0.7): """为全球用户适配推荐算法""" # 融合地域特征权重 base_prediction = self.user_profile_model.predict(user_features) regional_adjustment = self._calculate_regional_adjustment(user_features) # 加权融合 final_prediction = (base_prediction * (1 - region_weight) + regional_adjustment * region_weight) return final_prediction def generate_recommendations(self, user_id, context_features): """生成融合推荐结果""" # 获取用户画像 user_profile = self._get_unified_user_profile(user_id) # 获取候选内容 candidate_contents = self._retrieve_candidates(user_profile) # 计算推荐分数 scores = self._calculate_recommendation_scores( user_profile, candidate_contents, context_features ) # 多样性重排序 final_recommendations = self._diversify_recommendations(scores) return final_recommendations def _get_unified_user_profile(self, user_id): """获取统一用户画像""" # 合并Musical.ly和TikTok用户数据 musically_data = self._query_musically_profile(user_id) tiktok_data = self._query_tiktok_profile(user_id) return self._merge_profiles(musically_data, tiktok_data)推荐算法交互流程:

3. 系统架构融合设计
混合云架构实现
基础设施代码示例:
# kubernetes部署配置 apiVersion: apps/v1 kind: Deployment metadata: name: recommendation-service namespace: tiktok-global spec: replicas: 10 selector: matchLabels: app: recommendation template: metadata: labels: app: recommendation spec: containers: - name: recommender image: byte-dance/recommendation-engine:2.1.0 ports: - containerPort: 8080 env: - name: AWS_REGION value: "us-east-1" - name: REDIS_CLUSTER value: "redis-global-cluster" - name: KAFKA_BROKERS value: "kafka-global:9092" resources: requests: memory: "2Gi" cpu: "1000m" limits: memory: "4Gi" cpu: "2000m" --- apiVersion: v1 kind: Service metadata: name: recommendation-service spec: selector: app: recommendation ports: - protocol: TCP port: 80 targetPort: 8080 type: LoadBalancer数据库迁移脚本:
-- 用户数据迁移和融合 CREATE TABLE unified_users ( user_id VARCHAR(64) PRIMARY KEY, musically_legacy_id VARCHAR(64), tiktok_global_id VARCHAR(64), merged_profile JSONB, created_at TIMESTAMP, updated_at TIMESTAMP, region VARCHAR(32), preferences JSONB ); -- 创建跨区域数据同步触发器 CREATE OR REPLACE FUNCTION sync_user_behavior() RETURNS TRIGGER AS $$ BEGIN -- 实时同步到Kafka PERFORM pg_notify('user_behavior_channel', json_build_object( 'user_id', NEW.user_id, 'action', NEW.action, 'timestamp', NEW.timestamp )::text); RETURN NEW; END; $$ LANGUAGE plpgsql; CREATE TRIGGER user_behavior_sync AFTER INSERT ON user_behavior FOR EACH ROW EXECUTE FUNCTION sync_user_behavior();系统架构融合视图:
C4Context title 字节跳动与Musical.ly技术架构融合 Person(全球用户, "全球用户", "使用融合后的TikTok应用") System(tiktok_global, "TikTok全球平台", "统一的短视频服务平台") System_Ext(aws_infrastructure, "AWS云基础设施", "原Musical.ly技术栈") System_Ext(byte_idc, "字节跳动IDC", "国内私有云体系") System_Ext(cdn_global, "全球CDN网络", "内容分发加速") System(db_unified, "统一数据层", "融合的用户数据和内容库") System(rec_engine, "智能推荐引擎", "适配全球的推荐算法") System(sync_service, "数据同步服务", "跨区域实时数据同步") 全球用户 --> tiktok_global: 使用应用 tiktok_global --> aws_infrastructure: 海外服务部署 tiktok_global --> byte_idc: 国内服务支持 tiktok_global --> cdn_global: 内容加速 aws_infrastructure --> sync_service: 数据迁移 byte_idc --> sync_service: 算法模型同步 sync_service --> db_unified: 统一数据存储 db_unified --> rec_engine: 提供训练数据 rec_engine --> tiktok_global: 返回推荐结果4. 关键实施策略
渐进式迁移方案
class MigrationOrchestrator: def __init__(self): self.phase = 1 self.metrics_collector = MetricsCollector() def execute_migration_phase(self): """执行分阶段迁移""" if self.phase == 1: self._phase1_data_sync() elif self.phase == 2: self._phase2_algorithm_testing() elif self.phase == 3: self._phase3_full_cutover() def _phase1_data_sync(self): """第一阶段:数据同步和备份""" # 建立双向数据同步通道 self._setup_cross_region_sync() # 验证数据一致性 self._validate_data_consistency() def _phase2_algorithm_testing(self): """第二阶段:算法A/B测试""" # 部署融合推荐算法到部分用户 self._deploy_hybrid_algorithm() # 收集性能指标 self._collect_ab_test_metrics() def _phase3_full_cutover(self): """第三阶段:全面切换""" if self._validate_migration_success(): self._complete_cutover() self._decommission_legacy_systems()总结
字节跳动成功融合Musical.ly技术架构的关键在于:
- 数据层面:建立实时、双向的数据同步机制,确保跨区域数据一致性
- 算法层面:采用迁移学习和权重融合策略,将字节跳动成熟的推荐算法适配到全球用户画像
- 架构层面:设计混合云架构,充分利用AWS云服务的弹性优势和字节跳动自建IDC的计算能力
- 实施策略:采用渐进式迁移,通过A/B测试验证效果,确保系统稳定性和用户体验
这种技术架构融合不仅解决了眼前的整合挑战,还为TikTok的全球扩张奠定了坚实的技术基础。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2022-08-02 13:07历史上的今天的博客 8 月 2 日,历史上的今天,美国科学促进会第一位女性主席 Mina Rees 出生;PlayStation 之父 Ken Kutaragi 出生;字节跳动收购 Musical.ly。
- 2022-08-02 15:03CSDN资讯的博客 资料来源:维基百科 2018 年 8 月 2 日:字节跳动收购 Musical.ly 图源:维基百科 Musical.ly,是一个 2014 年 4 月上线的短视频社群手机应用程序,最初是上海闻学网络科技有限公司旗下的产品,且最早是一款视频...
- 2023-08-02 14:30CSDN资讯的博客 历史上的今天,字节跳动收购 Musical.ly Musical.ly 在活跃期间积累了超过 2 亿用户,每天收到数百万视频上传。Musical.ly 并不是一家失败的初创公司——它并没有因为做错了什么而关闭。事实上,Musical.ly 是一家...
- 2023-08-02 08:00历史上的今天的博客 历史上的今天,字节跳动收购 Musical.ly Musical.ly 在活跃期间积累了超过 2 亿用户,每天收到数百万视频上传。Musical.ly 并不是一家失败的初创公司——它并没有因为做错了什么而关闭。事实上,Musical.ly 是一家...
- 2017-11-11 00:00商业价值的博客 在双十一前夕,今日头条突然宣布了一条重磅消息,以估值10亿美元的价格收购musical.ly,这让抖音和musical.ly原本的中国市场对垒消失在无形之中,而今日头条也就此进一步加速国际化。从自建到加速并购投资,今日头条...
- 2024-07-25 11:17
 【社交应用技术】musical.ly基于社交关系的Smart Feed架构优化:提升短视频分发效率与用户体验设计总结 业务系统架构的蜕变与进化 musical.ly基于社交关系的Smart Feed架内容概要:本文详细介绍了短视频社交应用musical.ly基于社交关系的Smart Feed架构的发展历程与技术细节。文章首先概述了musical.ly的业务背景,指出随着用户基数和内容生产数量的增长,提高内容分发效率成为关键目标...
【社交应用技术】musical.ly基于社交关系的Smart Feed架构优化:提升短视频分发效率与用户体验设计总结 业务系统架构的蜕变与进化 musical.ly基于社交关系的Smart Feed架内容概要:本文详细介绍了短视频社交应用musical.ly基于社交关系的Smart Feed架构的发展历程与技术细节。文章首先概述了musical.ly的业务背景,指出随着用户基数和内容生产数量的增长,提高内容分发效率成为关键目标... - 2024-07-18 19:03当VIP用户发布新内容后,会立即将其内容分发给所有的“VipZealot”,而“VipZealot”在拉取Feed时,则无需拉取VIP的Outbox,这样不仅解决了内容丢失的问题,同时也保证了在线接口的访问性能。 这些改进措施不仅大幅...
- 2019-07-23 07:18标题中的“***微服务化之路”揭示了文档的核心内容,即将传统的单体应用架构向微服务架构转型的实践过程。***作为一款面向海外市场的短视频社交应用,其技术团队在转型过程中遇到了许多问题和挑战,文档详细地介绍了...
- 2017-12-01 16:30weixin_34416649的博客 嘉宾|Wood(张木喜)编辑|薛梁1 写在前面11 月 10 日,今日头条正式与北美知名短视频社交产品 musical.ly 签署协议,将全资收购 musical.ly,在此之前,musical.ly 的全球 DAU 超过 2000 万,但国内鲜有人知道这家...
- 2019-07-24 11:33《musical.ly微服务化之路》是一本深入探讨微服务架构在实际业务场景中应用的专业书籍,特别是针对musical.ly这个流行的音乐社交平台。在这个过程中,java技术扮演了至关重要的角色,因为它是最常用于构建微服务的...
- AWS_Device_Farm_Android_Sample(Android消息应用程序) 此存储库包含适用于Android的AWS Device Farm启用的测试用例 这是为AWS Device Farm 示例应用程序编写的示例Appium TestNG测试的集合。...
- 2019-08-14 17:43在收购 Musical.ly 之后,TikTok(抖音海外版)承载了字节跳动出海的野心,但是弱点和强项同样明显。 战略进攻方向是搜索、直播、电商带货 :与外界想象的相反,字节跳动没有把主要资源投入社交和游戏,不急于与...
- 2017-11-10 00:00商业价值的博客 钛媒体来自今日头条官方的消息,今日头条正式与北美知名短视频社交产品musical.ly签署协议,将全资收购musical.ly。 据今日头条称,musical.ly的市场估值接近10亿美金。交易完成后,今日头条旗下音乐短视频...
- 2022-06-24 01:32"商业编程-源码-音频技术源代码 midi_src.zip"这个文件包显然包含了一组与音频处理相关的源代码,特别是涉及到MIDI(Musical Instrument Digital Interface)技术。 MIDI是一种数字音乐标准,它允许各种音乐设备,...
- 2022-06-24 01:30在本压缩包“商业编程-源码-音频技术源代码 midi_demo.zip”中,我们重点关注的是音频技术的源代码,特别是与MIDI(Musical Instrument Digital Interface)相关的实现。MIDI是一种广泛应用于音乐制作和电子乐器间的...
- 2022-06-24 01:34《商业编程-源码-音频技术源代码 MidiPlayer_src.zip》是一个包含音频处理技术源代码的压缩包,其中的核心项目是MidiPlayer_src。这个项目主要用于解析和播放MIDI(Musical Instrument Digital Interface)文件,这...
- 2021-04-23 22:41通过一系列的战略决策,包括2017年收购Musical.ly,抖音不仅在国内市场取得了巨大成功,还在海外市场取得了显著成绩,特别是其国际版TikTok在全球范围内吸引了大量用户。抖音的成功不仅体现在用户数量的增长上,更...
- 2025-05-09 10:39在当前技术领域中,MIDI(Musical Instrument Digital Interface)作为一种重要的音乐技术标准,广泛应用于音乐软件和硬件的连接与交互。而VB.NET作为微软推出的一种面向对象的编程语言,凭借其强大的功能和良好的...
- 2023-07-28 16:43同时,收购Musical.ly并发展TikTok,显示了字节跳动的全球化野心,但其在海外市场面临的挑战和内部的弱点也同样突出。 在战略方向上,字节跳动并未将主要精力放在与腾讯的社交或游戏领域竞争,而是聚焦于搜索、直播...
- 2022-06-16 12:08《MIDI程序源码集锦》是一个包含商业源码的压缩包,主要涉及的是与MIDI(Musical Instrument Digital Interface)相关的编程技术。MIDI是一种通信协议,它允许电子乐器、计算机和其他设备之间交换音乐数据。这个源码...
- 没有解决我的问题, 去提问

问题事件
 已采纳回答
11月6日
已采纳回答
11月6日-
创建了问题
11月5日