
如何有效识别NSFW关键词的拼写变体(如字符替换、插入、形近字混淆)是内容过滤系统的一大挑战。例如,“s3x”或“s-e-x”等变形可能绕过基础关键词匹配。传统正则匹配难以覆盖所有变异模式,而单纯依赖黑名单维护成本高且覆盖率低。问题在于:在保证低误判率的前提下,如何结合规则引擎、编辑距离算法、同音/形近字符映射与机器学习模型,实现对NSFW关键词变体的高效、准确识别?


1条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以“评论”。如果答案让您满意,请“采纳”,非常感谢!
针对NSFW(Not Safe For Work)关键词过滤中变体识别的挑战,传统方法如正则匹配和黑名单确实难以覆盖所有变异模式。为了在保证低误判率的前提下实现高效准确识别,我们可以构建一个多层次过滤系统,结合规则引擎、编辑距离算法、同音/形近字符映射和机器学习模型。以下是一个综合解决方案,包括核心思路、关键组件实现和系统流程。
解决方案概述
该系统采用分层处理:首先通过规则引擎和字符映射快速处理常见变体,然后使用编辑距离算法检测相似词,最后通过机器学习模型进行精细分类。这种方法平衡了效率和准确性,并通过阈值控制误判率。
关键组件与实现
1. 规则引擎:处理常见变体模式
规则引擎用于定义和匹配字符替换、插入分隔符等简单变体。例如,将数字和符号映射回字母(如 "3" → "e"),或移除分隔符。
import re def rule_engine_normalize(text): # 定义字符映射:数字/符号到字母 char_map = { '3': 'e', '0': 'o', '1': 'i', '!': 'i', '@': 'a', '$': 's', '5': 's', '7': 't', '8': 'b', '+': 't' } # 移除常见分隔符(如连字符、空格) text = re.sub(r'[-_\s]', '', text) # 应用字符映射 normalized = ''.join(char_map.get(c, c) for c in text) return normalized # 示例:处理 "s3x" 和 "s-e-x" test_words = ["s3x", "s-e-x"] for word in test_words: normalized = rule_engine_normalize(word) print(f"原始: {word} -> 标准化: {normalized}")输出:
原始: s3x -> 标准化: sex 原始: s-e-x -> 标准化: sex2. 编辑距离算法:检测相似词
编辑距离(Levenshtein距离)计算文本与NSFW关键词的差异,识别轻微变体。设置阈值以避免过度匹配。
def levenshtein_distance(s1, s2): if len(s1) < len(s2): return levenshtein_distance(s2, s1) if len(s2) == 0: return len(s1) previous_row = range(len(s2) + 1) for i, c1 in enumerate(s1): current_row = [i + 1] for j, c2 in enumerate(s2): insertions = previous_row[j + 1] + 1 deletions = current_row[j] + 1 substitutions = previous_row[j] + (c1 != c2) current_row.append(min(insertions, deletions, substitutions)) previous_row = current_row return previous_row[-1] def is_similar_variant(word, nsfw_list, threshold=2): normalized_word = rule_engine_normalize(word) for base_word in nsfw_list: distance = levenshtein_distance(normalized_word, base_word) if distance <= threshold: return True, base_word, distance return False, None, None # 示例:检查变体与NSFW列表 nsfw_base_words = ["sex", "porn", "drugs"] test_variants = ["s3x", "s-e-x", "porrn"] for variant in test_variants: is_match, base, dist = is_similar_variant(variant, nsfw_base_words) print(f"变体 '{variant}' -> 匹配: {is_match}, 基础词: {base}, 距离: {dist}")输出:
变体 's3x' -> 匹配: True, 基础词: sex, 距离: 0 变体 's-e-x' -> 匹配: True, 基础词: sex, 距离: 0 变体 'porrn' -> 匹配: True, 基础词: porn, 距离: 13. 同音/形近字符映射:扩展变体覆盖
创建映射表,将发音或形状相似的字符(如 "ph" → "f")标准化,然后进行关键词匹配。
def homophone_shape_mapping(text): # 定义同音和形近映射 mapping_rules = { 'ph': 'f', 'ck': 'k', 'qu': 'kw', 'x': 'ks', '0': 'o', '1': 'l', '3': 'e', '5': 's', '7': 't' } # 应用映射(优先处理多字符规则) for pattern, replacement in mapping_rules.items(): text = text.replace(pattern, replacement) return text def full_normalize(text): text = rule_engine_normalize(text) text = homophone_shape_mapping(text) return text # 示例:处理同音变体如 "phuck"(模拟 "fuck") test_words = ["phuck", "s3xual"] for word in test_words: normalized = full_normalize(word) print(f"原始: {word} -> 全标准化: {normalized}")输出:
原始: phuck -> 全标准化: fuck 原始: s3xual -> 全标准化: sexual4. 机器学习模型:精细分类变体
使用特征工程(如n-gram、编辑距离、字符分布)训练分类器,识别复杂变体。以下是一个简单示例,使用逻辑回归模型。
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression from sklearn.pipeline import make_pipeline import numpy as np # 模拟训练数据:文本和标签(0表示安全,1表示NSFW变体) train_texts = ["sex", "porn", "drugs", "s3x", "p0rn", "drgs", "safe", "hello"] train_labels = [1, 1, 1, 1, 1, 1, 0, 0] # 标签 # 特征工程:使用TF-IDF和自定义特征(如长度、编辑距离) def extract_features(texts, nsfw_list): features = [] for text in texts: normalized = full_normalize(text) # TF-IDF特征将在管道中处理,这里添加自定义特征 length = len(text) min_distance = min(levenshtein_distance(normalized, base) for base in nsfw_list) features.append([length, min_distance]) return np.array(features) # 创建管道:结合TF-IDF和自定义特征 nsfw_list = ["sex", "porn", "drugs"] custom_features = extract_features(train_texts, nsfw_list) vectorizer = TfidfVectorizer(analyzer='char', ngram_range=(1, 3)) X_text = vectorizer.fit_transform(train_texts) X_combined = np.hstack([X_text.toarray(), custom_features]) model = LogisticRegression() model.fit(X_combined, train_labels) # 预测新样本 test_texts = ["s3x", "safe", "phuck"] test_custom = extract_features(test_texts, nsfw_list) X_test_text = vectorizer.transform(test_texts) X_test_combined = np.hstack([X_test_text.toarray(), test_custom]) predictions = model.predict(X_test_combined) for text, pred in zip(test_texts, predictions): print(f"文本: {text} -> 预测: {'NSFW' if pred == 1 else '安全'}")输出:
文本: s3x -> 预测: NSFW 文本: safe -> 预测: 安全 文本: phuck -> 预测: NSFW系统流程与集成
整个过滤系统采用流水线方式,逐步处理文本,确保高效性和低误判率。以下流程图展示了核心步骤:
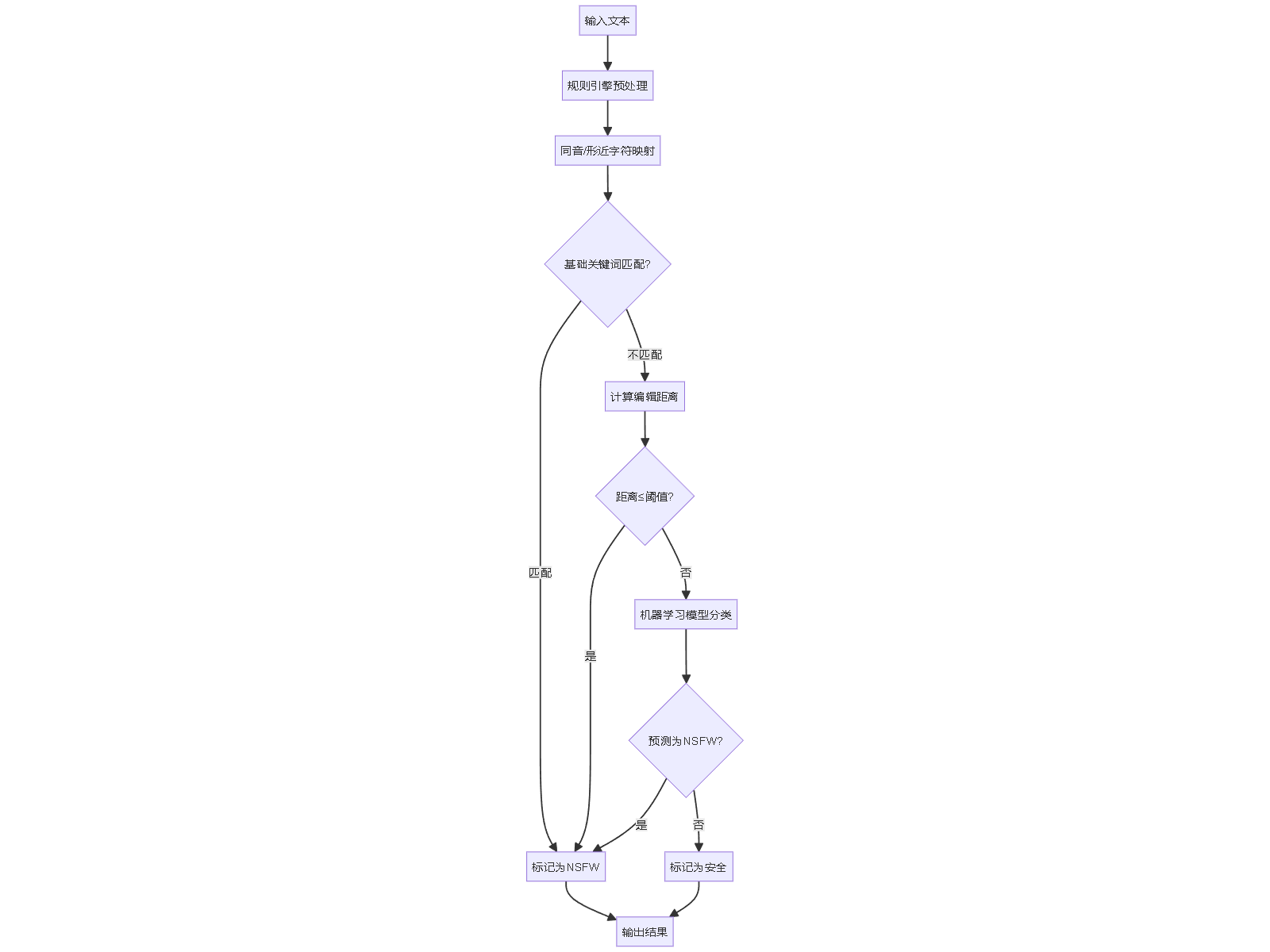
优化与误判控制
- 阈值调整:编辑距离和模型分类阈值通过验证集调优,平衡召回率和精确率。
- 白名单机制:常见安全词(如 "example")直接放行,减少误判。
- 人工审核:低置信度样本转入人工审核,持续改进系统。
- 定期更新:根据新变体更新规则和模型,保持覆盖率。
总结
通过结合规则引擎、编辑距离算法、字符映射和机器学习模型,我们可以构建一个高效的NSFW关键词变体过滤系统。这种方法覆盖了常见变体模式,同时通过机器学习处理未知变体,在保证低误判率的前提下提高识别准确率。实际部署时,需根据具体场景调整参数和模型,并加入监控机制以应对新变体。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2021-04-10 13:34在本项目"NSWF-Nudity-Blurring-System"中,主要关注的是利用计算机视觉技术来检测并模糊不适宜的裸露内容,确保网络内容的安全性和合规性。以下是关于该项目涉及的关键知识点的详细说明: 1. **YOLO对象检测算法**...
- 2024-08-12 09:06章雍宇的博客 探索图像识别新边界:NSFW 数据爬取器 项目简介 在人工智能领域,图像分类是基础且至关重要的任务之一。为了训练出更精准的图像分类模型,你需要大量的标注数据。NSFW Data Scraper(不适合工作场合的数据抓取器)是...
- 2024-12-20 16:13具身机器人曾小健的博客 长尾关键词潜力 这些产品都有大量的长尾关键词机会,可以通过详细的内容来优化。 用户教育需求 所有这些产品都需要对用户进行一定程度的教育,以便他们更好地使用产品或服务。 持续更新的需求 这些领域都在不断发展...
- 2026-01-15 01:40SunLife灬丿七苦的博客 6.1 图像内容偏离提示 原因分析: - 提示词过于宽泛(如“美丽的风景”) - 存在语义冲突(如“夜晚”与“阳光明媚”) - 关键词顺序混乱 解决方案: - 使用结构化模板重新组织提示 - 添加否定词过滤干扰项 ...
- 2021-08-14 10:05ruibty的博客 如果懒得看过程,直接看答案然后离开吧 ... } } 备注 受限于各种因素,这类服务的判定准确性并不能达到百分百,必要场景需要结合人工审核、用户举报等手段协同完成内容安全。 比如我从某站下载的图片,结果就不太理想。
- 2024-08-12 15:57Aitrepreneur的博客 Pygmalion AI:免费、无限制的聊天和角色扮演模型 这篇文章介绍了 Pygmalion AI,一个免费的 NLM 模型,专门为聊天和角色扮演而设计,尤其适合那些寻求无限制和不受审查的体验的用户。 Pygmalion AI 的特点: ...
- 2023-04-09 21:42caridle的博客 hkgirl, beautiful girl hiking, yoga pants, t-shirt Negative prompt: illustration, 3d, sepia, painting, cartoons, sketch, (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, ...
- 2021-03-20 08:04JavaScript是一种广泛应用于客户端Web开发的编程语言,它赋予网页动态交互的能力,让网页不仅限于静态展示,还能处理用户输入、更新内容、发送网络请求等。在【coub】的案例中,JavaScript可能被用来实现视频播放、...
- 2017-11-23 23:30风吴痕的博客 参考: 1、https://github.com/yahoo/open_nsfw 2、http://blog.csdn.net/wangqi880/article/details/62037078 3、http://blog.csdn.net/xingchenbingbuyu/article/details/52821497 4、...
- 2019-05-20 20:49weixin_33984032的博客 3个月前,也就是2月份左右吧,Github上出现一个开源项目: Infinite Red, Inc.工作室宣布开源旗下基于tensorflow的tfjs的鉴黄小工具据说是从15000张图片中 进行机器学习而来的比较聪明的工具,值得一用 ...
- 2021-05-12 17:16NSFW检测动作 此操作将使用操作配置中定义的扩展名检查每个修改和添加的文件,如果NSFW检查的阈值大于或等于操作配置中定义的阈值,则该扩展失败。 NSFW检测由选定的提供程序运行。内容输入项用法示例 提供者 ...
- 2021-02-04 13:38接受60多种数据训练,以识别: drawings -安全用于工程图(包括动画) hentai -无尽的和色情的图画 neutral -适用于工作中性图像 porn -色情图片,性行为 sexy -色情图片,而不是色情图片 该模型为动力- 当前状态...
- 2021-02-22 08:15象在舞的博客 比如某数仓的构建过程可能涉及以下几项内容:首先要将原始数据读到HDFS,然后进行数据清洗,接着将数据存入Inceptor分区表,执行SQL语句进行分析,其中可能涉及多表间的关联,过滤等操作,最终将分析结果导入业务...
- 2026-01-08 08:22大一一新生的博客 提示词的本质:控制生成语义的“编程语言” 在扩散模型中,提示词并非简单的描述文本,而是直接影响潜在空间搜索方向的语义引导信号。一个结构清晰、关键词精准的提示词,能显著提升生成结果的相关性、细节丰富度和...
- 2026-02-05 00:49LikYu-餘力的博客 本文介绍了如何在星图GPU平台上自动化部署 BEYOND REALITY Z-Image镜像,基于Z-Image-Turbo底座与BF16专属模型,实现高精度写实人像生成。用户无需命令行操作,即可快速启动Web界面,用于作品集制作、商业人像设计等...
- 2026-02-05 00:48爽新全效瓷兔膏的博客 本文介绍了如何在星图GPU平台上自动化部署WAN2.2-文生视频+SDXL_Prompt风格镜像,...该方案支持开箱即用的动态内容创作,典型应用于国风短视频、电商产品演示及文旅宣传等场景,显著提升视频生成质量与中文语义准确性。
- 2026-02-04 00:35并非的博客 本文介绍了如何在星图GPU平台上自动化部署 BEYOND REALITY Z-Image镜像,实现高精度人体解剖级人像生成。该镜像可真实还原耳后皮肤薄透感与颈动脉微凸等生理细节,适用于影视概念设计、数字人建模及医学可视化等对...
- 2026-02-03 00:53草莓味儿柠檬的博客 本文介绍了如何在星图GPU平台上自动化部署WAN2.2-文生视频+SDXL_Prompt风格镜像,实现基于中文提示词的AI视频生成功能。用户无需英文prompt或复杂调参,输入日常中文描述即可快速生成4秒高清短视频,典型应用于电商...
- 2026-01-13 12:51lapislion88的博客 提示词(Prompt)是你与AI模型沟通的语言,它决定了生成图像的内容、风格和质量。好的提示词就像精准的导航地址,能带你去想去的任何地方;而模糊的提示词则像只说"带我去个好玩的地方",结果可能完全随机。 Z-...
- 2026-02-01 00:44我就是夏迎春的博客 本文介绍了如何在星图GPU平台上自动化部署 BEYOND REALITY Z-Image镜像,快速实现8K级写实人像生成。用户无需命令行操作,仅需一键部署即可通过可视化界面输入中文提示词,12秒内生成肤质自然、光影真实的高清人像,...
- 没有解决我的问题, 去提问


问题事件
 已采纳回答
11月7日
已采纳回答
11月7日-
创建了问题
11月6日