
在W8A8与W4A16混合精度训练中,如何协同优化不同层的量化策略以平衡模型精度与计算效率?由于权重和激活的位宽不一致,低精度路径(W8A8)可能引入较大误差,而高精度路径(W4A16)虽提升表征能力但增加内存带宽压力。常见问题是:如何动态分配W8A8与W4A16策略到不同网络层?如何设计统一的梯度更新机制以避免精度错配导致的训练不稳定?此外,硬件对不同精度组合的支持差异也带来部署难题。


2条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以“评论”。如果答案让您满意,请“采纳”,非常感谢!
针对W8A8(权重8位、激活8位)与W4A16(权重4位、激活16位)混合精度训练的协同优化问题,我将从动态策略分配、梯度更新机制和硬件部署三个方面进行详细解答。混合精度训练旨在平衡模型精度与计算效率,但不同位宽的量化路径会引入误差和内存压力,需要系统化的优化方法。
1. 动态分配W8A8与W4A16策略到不同网络层
动态分配量化策略的核心是根据网络层的敏感性和计算特征,自动选择最优的位宽组合。通常,卷积层和全连接层对量化误差的容忍度不同,因此需要分层处理:
- 高敏感层(如输入层、输出层):优先使用W4A16,以保留更多信息,避免误差累积。
- 低敏感层(如中间隐藏层):使用W8A8,减少计算和内存开销。
- 自适应方法:通过监控每层的梯度幅值或激活分布,动态调整量化策略。例如,如果某层的激活值变化剧烈,则切换到更高精度。
实现时,可以使用启发式规则或强化学习自动搜索最优分配。以下是一个简单的Python伪代码示例,使用PyTorch框架演示动态分配逻辑:
import torch import torch.nn as nn def dynamic_quantization_policy(layer, input_sensitivity): """ 根据层的敏感性动态选择量化策略。 :param layer: 神经网络层 :param input_sensitivity: 输入敏感性评分(基于梯度或激活统计) :return: 量化配置 """ if input_sensitivity > 0.5: # 高敏感性层 return {"weight_bits": 4, "activation_bits": 16} # W4A16 else: # 低敏感性层 return {"weight_bits": 8, "activation_bits": 8} # W8A8 # 示例:遍历网络层并应用策略 model = nn.Sequential( nn.Linear(100, 50), nn.ReLU(), nn.Linear(50, 10) ) for name, layer in model.named_children(): sensitivity = compute_sensitivity(layer) # 假设的敏感性计算函数 policy = dynamic_quantization_policy(layer, sensitivity) print(f"层 {name}: 使用策略 W{policy['weight_bits']}A{policy['activation_bits']}")2. 设计统一的梯度更新机制
梯度更新机制必须处理不同精度路径导致的精度错配问题,避免训练不稳定(如梯度爆炸或消失)。关键点包括:
- 梯度量化与缩放:在反向传播时,对梯度进行动态缩放和量化,以匹配各层的位宽。例如,W8A8路径的梯度可能需要8位量化,而W4A16路径的梯度保持16位。
- 统一优化器:使用共享的优化器(如Adam或SGD),但对不同精度的梯度应用不同的学习率调整或裁剪策略。
- 精度转换桥接:在层间传递梯度时,插入精度转换操作(如16位到8位),确保数据一致性。
以下是一个梯度统一更新的示例代码,展示如何在不同精度层间处理梯度:
import torch import torch.optim as optim class MixedPrecisionOptimizer: def __init__(self, model, lr=0.01): self.model = model self.optimizer = optim.Adam(model.parameters(), lr=lr) def step(self): # 遍历所有参数,根据量化策略调整梯度 for name, param in self.model.named_parameters(): if param.grad is not None: # 假设根据层的量化位宽调整梯度精度 if "weight_bits" in name and "4" in name: # W4A16层 param.grad = param.grad.to(torch.float16) # 保持16位 else: # W8A8层 param.grad = param.grad.to(torch.int8) # 量化为8位 # 应用梯度裁剪防止不稳定 torch.nn.utils.clip_grad_norm_(param, max_norm=1.0) self.optimizer.step() # 使用示例 optimizer = MixedPrecisionOptimizer(model) loss = model(input_data).sum() loss.backward() optimizer.step()3. 硬件部署考虑
硬件对不同精度组合的支持差异(如GPU对INT8和FP16的加速程度不同)可能导致部署效率下降。解决方案包括:
- 硬件感知量化:在训练时考虑目标硬件的特性,例如使用NVIDIA TensorRT或Intel OpenVINO的量化工具进行校准。
- 动态编译:在推理时根据硬件能力动态选择量化策略,例如通过AutoML框架搜索最优部署配置。
- 内存带宽优化:针对W4A16的高内存压力,使用缓存或批处理技术减少带宽瓶颈。
整体优化流程
以下是一个mermaid图形,展示W8A8与W4A16混合精度训练的协同优化流程,包括动态分配和梯度更新:
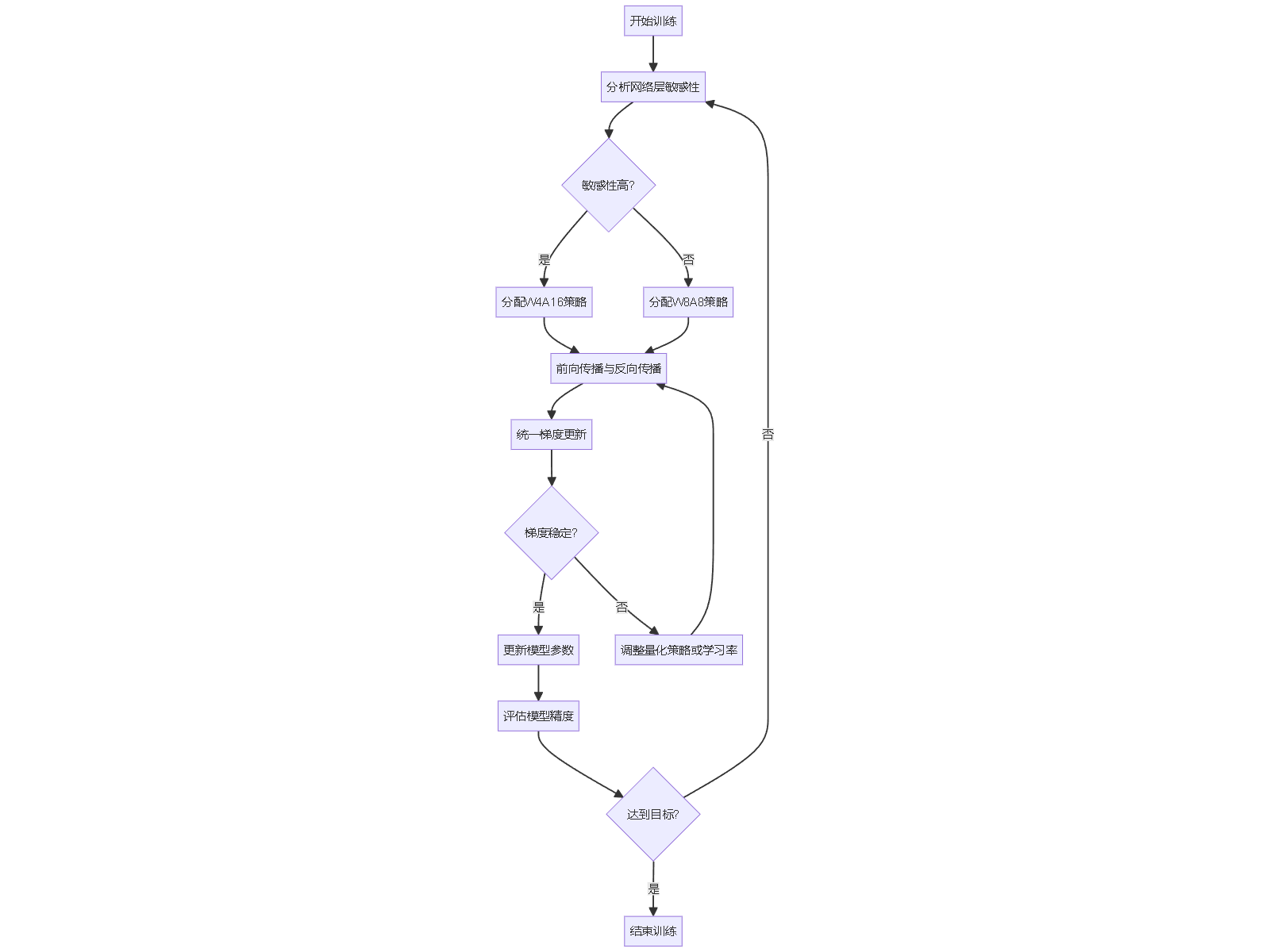
总结
W8A8与W4A16混合精度训练的协同优化需要结合动态策略分配、统一的梯度更新和硬件感知部署。通过分层量化、梯度精度桥接和硬件适配,可以有效平衡模型精度与计算效率。实际应用中,建议使用现有框架(如PyTorch的量化模块或TensorFlow的MixedPrecision)作为基础,并根据具体任务进行调整。如果遇到特定问题,如梯度不稳定,可进一步细化监控机制(如梯度直方图记录)。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2026-01-10 10:25叶庭云的博客 一文了解 W8A8、W4A8、稀疏量化、FlashAttention-3、KV Cache 量化
- 2025-12-23 20:59倔强的石头_的博客 本文详细介绍了使用昇腾...通过实测数据表明,W8A8量化可使显存占用降低42%,推理时延提升33%,而精度损失仅1.3%。文章还提供了常见问题解决方案,展示了ModelSlim在昇腾生态中实现模型轻量化和推理加速的有效性。
- 2025-08-29 23:54鲍瑛嫚的博客 随着大语言模型(LLM)参数规模不断增长,模型推理时的显存占用和计算开销...PaddleNLP推出的W8A8C8量化技术,通过**激活、权重、缓存全面协同**的联合优化方案,实现了真正意义上的端到端8位量化。 > **读完本文你...
- 2026-05-21 09:33一起养小猫的博客 昇腾NPU上W8A8量化比W4A16更实用的原因:W8A8在Llama2-70B模型上实现2倍压缩(4卡即可运行),精度损失仅0.1-0.5%,且利用NPU的int8 GEMM算力优势,解码速度比fp16提升16%。而W4A16虽然压缩比达4倍,但反量化开销大...
- 2025-09-15 10:49卢红梓的博客 在深度学习模型(尤其是大语言模型,LLM)的实际应用中,显存占用和计算效率是企业级部署的核心挑战。...**W8A8量化技术(Weight 8-bit, Activation 8-bit)** 通过将权重和激活值同时压缩至8位...
- 2025-03-28 15:31顺其自然~的博客 ATB Models公共能力支持以下量化方式: W8A8、W8A16、W8A8SC稀疏量化、KV Cache int8、Anti-Outlier离群值处理、Attention量化 量化脚本说明 MindIE LLM中提供统一的脚本${ATB_SPEED_HOME_PATH}/examples/convert/...
- 2024-05-04 09:45LLM教程的博客 随着模型在各种场景中的落地实践,模型的推理加速早已成为...而近年基于Transformer架构的大模型继而成为主流,在各项任务中取得SoTA成绩,它们在训练和推理中的昂贵成本使得其在合理的成本下的部署实践显得愈加重要。
- 2026-05-16 22:30项羽欧大哥的博客 之前用 LoRA 微调了 Qwen3-VL-8B,做工地场景的图像理解与安全风险分析。...把主流方案都过了一遍,最后落在 GPTQ W4A16 + LLM Compressor 上。中间踩了几个不算明显的坑,写下来给后面要做同样事情的人省点时间。
- 2025-10-15 17:16饮马长城窟的博客 离群值抑制(AntiOutlier) 可优化参数——anti_method m1:SmoothQuant算法 m2:SmoothQuant升级版 m3:AWQ算法(适用于W8A16/W4A16) m4:SmoothQuant优化算法 m5:CBQ算法 m6:Flex smooth量化算法 w8a8适用m1、m2、...
- 2026-05-07 18:11Mininglamp_2718的博客 Cider 推理加速 SDK 详解:W8A8 激活量化原理与 Apple Silicon 适配
- 2025-10-24 00:21sprite的博客 本文深入解析了MNN-LLM框架的W4A8量化技术,揭秘其如何通过4位权重和8位激活值的整数计算,结合ARM平台的smmla指令级优化与内存访问模式优化,在端侧设备上实现7B大语言模型高达3.5倍的推理加速,大幅降低内存占用,...
- 2023-05-24 19:47zhurui_xiaozhuzaizai的博客 大模型训练显存和计算量优化
- 2025-09-15 13:41姚喻蝶Kerry的博客 本文通过实测对比W4A16(INT4)和W8A8(INT8/FP8)两种量化方案的能效表现,帮你找到性能与能耗的最佳平衡点。 读完本文你将了解: - 不同量化精度下的推理速度差异 - W4A16与W8A8的实际功耗对比 -
- 2025-01-18 07:45E的工程笔记的博客 一、关于 VILA ...四、训练 步骤1:对齐 步骤-1.5: 第二步:预训练 步骤3:监督微调 五、评估 六、推理 七、量化和部署 1、在桌面GPU和边缘GPU上运行VILA 2、在笔记本电脑上运行VILA 3、运行VILA API服务器
- 2026-03-04 20:43AI大模型入门学习教程的博客 本文探讨了大语言模型部署面临的计算密集性和内存消耗挑战,从...提升效率的方法分为算法创新(如非自回归解码、投机解码)和系统优化(如并行计算、内存管理)两类,旨在平衡性能与资源消耗,为研究者提供理论参考。
- 2024-07-06 23:24seetimee的博客 支持加载时自动量化 GPTQ、AWQ、SqueezeLLM、FP8 KV 缓存 INT4/INT8 Weight-Only Quantization (W4A16 & W8A16)SmoothQuantGPTQAWQFP8 INT4 权重量化K/V 量化W8A8 量化 INT8, INT4 高性能Cuda Kernal ✓ ✓ ✓ ✓ ✓...
- 2026-04-30 09:52笨zhu的博客 本文深入探讨了RK3576开发板在运行大语言模型时,w4a16与w8a8量化对推理速度和精度的影响。通过实测Qwen-1.8B模型,对比了两种量化方案在模型大小、内存占用、推理速度及生成质量等方面的表现,为边缘计算设备上的大...
- 2025-11-25 01:18app77的博客 本文详细介绍了使用TensorRT-...通过Llama 3 8B模型的完整示例,展示了环境搭建、模型量化、TensorRT引擎构建及性能对比的全过程,旨在帮助开发者在精度损失与推理速度之间找到最佳平衡点,实现高效的大模型推理部署。
- 2025-11-28 01:02hope8的博客 本文深入剖析了LLM推理精度测试中的5个常见陷阱,从CEval数据集配置到NPU卡优化,揭示了大语言模型在训练推理过程中易被忽视的技术细节。特别针对推理精度测试中的内存管理、多卡并发、量化误差等关键问题,提供了...
- 2026-03-01 20:50Yeats_Liao的博客 量化技术概论:INT8/INT4量化对模型精度与速度的影响
- 没有解决我的问题, 去提问

问题事件
 已采纳回答
11月7日
已采纳回答
11月7日-
创建了问题
11月6日