在使用NCCL进行多GPU通信时,常遇到“NCCL backend initialization failed”错误。该问题通常出现在基于CUDA的分布式训练中,尤其是在PyTorch或TensorFlow等框架下。其根本原因可能是CUDA环境未正确配置、GPU驱动版本不兼容,或NCCL无法识别可用的CUDA设备。此外,当CUDA_VISIBLE_DEVICES设置不当,或跨节点通信时网络接口绑定错误,也会导致NCCL初始化失败。由于NCCL依赖于CUDA实现高效的GPU间通信(如AllReduce、Broadcast等),因此任何CUDA运行时异常都会直接影响NCCL功能。如何确保NCCL与CUDA版本匹配,并正确初始化上下文,是解决此类问题的关键。


2条回答 默认 最新

 关注
关注让【宝码香车】来帮你解答,本回答参考DeepSeek编写,并整理提供。
如果还有疑问可以“评论”。如果答案让您满意,请“采纳”,非常感谢!
CUDA与NCCL的关系及NCCL初始化失败解决方案
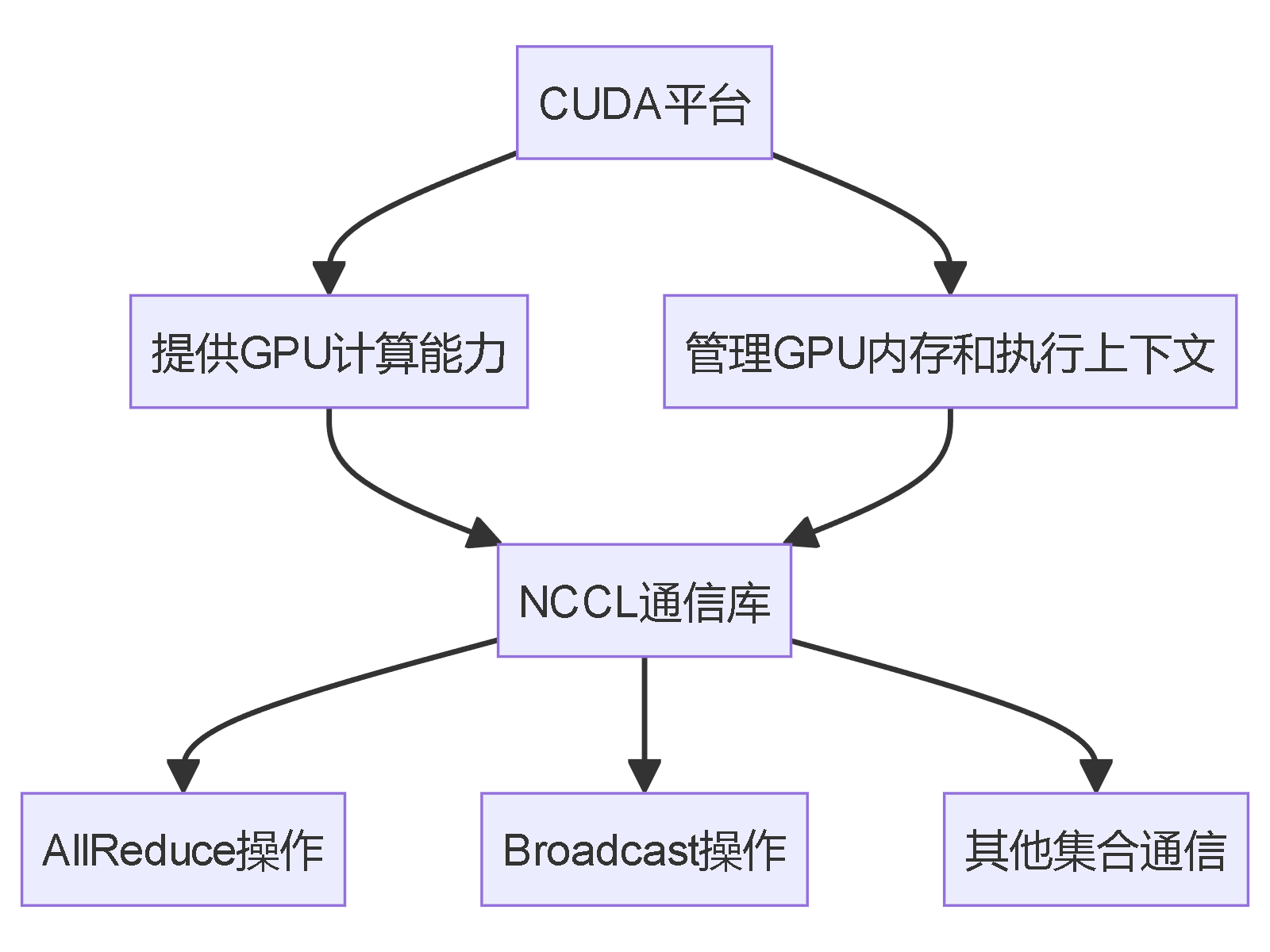
CUDA与NCCL的关系
CUDA(Compute Unified Device Architecture)是NVIDIA推出的并行计算平台和编程模型,而NCCL(NVIDIA Collective Communications Library)是建立在CUDA之上的多GPU通信库。
核心关系:
- 依赖关系:NCCL完全依赖于CUDA,使用CUDA提供的API进行GPU内存管理和核函数执行
- 功能互补:CUDA负责单GPU计算,NCCL负责多GPU间通信
- 性能优化:NCCL利用CUDA的流、事件等机制实现通信与计算的流水线并行
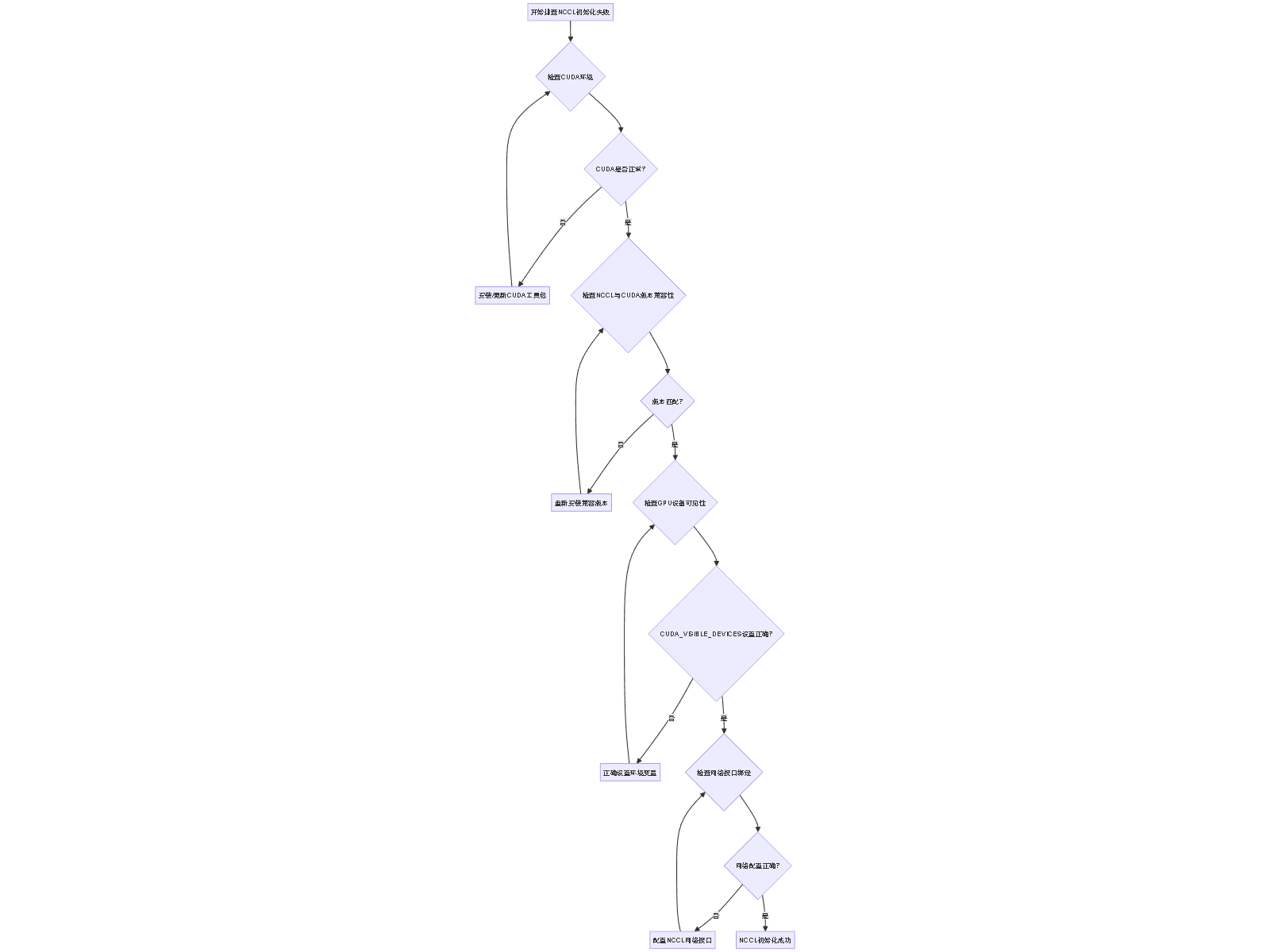
NCCL初始化失败排查流程
详细解决方案
1. 验证CUDA环境
# 检查CUDA安装 nvidia-smi nvcc --version # 验证CUDA运行时 python -c "import torch; print(torch.cuda.is_available())"2. 检查版本兼容性
import torch import subprocess def check_versions(): print(f"PyTorch版本: {torch.__version__}") print(f"CUDA版本: {torch.version.cuda}") # 检查NCCL try: result = subprocess.run(['nccl-config', '--version'], capture_output=True, text=True) print(f"NCCL信息: {result.stdout}") except: print("NCCL配置工具未找到") check_versions()3. 环境变量配置
# 设置正确的GPU设备 export CUDA_VISIBLE_DEVICES=0,1,2,3 # NCCL调试信息 export NCCL_DEBUG=INFO export NCCL_DEBUG_SUBSYS=INIT,ENV # 网络接口绑定(多节点环境) export NCCL_SOCKET_IFNAME=eth0 # 根据实际网络接口调整 export NCCL_IB_DISABLE=1 # 如果InfiniBand不可用4. 完整的NCCL初始化检查脚本
import os import torch import torch.distributed as dist def check_nccl_environment(): """检查NCCL环境配置""" print("=== NCCL环境检查 ===") # 检查CUDA if not torch.cuda.is_available(): print("❌ CUDA不可用") return False print(f"✅ CUDA可用,设备数量: {torch.cuda.device_count()}") # 检查环境变量 cuda_visible = os.getenv('CUDA_VISIBLE_DEVICES', '未设置') print(f"CUDA_VISIBLE_DEVICES: {cuda_visible}") # 尝试初始化NCCL try: dist.init_process_group(backend='nccl', init_method='env://') print("✅ NCCL初始化成功") # 清理 dist.destroy_process_group() return True except Exception as e: print(f"❌ NCCL初始化失败: {e}") return False def test_multi_gpu_communication(): """测试多GPU通信""" if torch.cuda.device_count() < 2: print("⚠️ 需要至少2个GPU进行通信测试") return print("\n=== 多GPU通信测试 ===") try: # 初始化进程组 dist.init_process_group(backend='nccl') # 在每个GPU上创建张量并执行AllReduce local_rank = dist.get_rank() torch.cuda.set_device(local_rank) tensor = torch.ones(10).cuda() * (local_rank + 1) dist.all_reduce(tensor) print(f"Rank {local_rank}: AllReduce结果 {tensor[:5]}") dist.destroy_process_group() print("✅ 多GPU通信测试成功") except Exception as e: print(f"❌ 多GPU通信测试失败: {e}") if __name__ == "__main__": if check_nccl_environment(): test_multi_gpu_communication()5. Docker环境配置
如果使用Docker,确保正确的运行时和权限:
# Dockerfile示例 FROM nvidia/cuda:11.8-devel-ubuntu20.04 # 安装NCCL RUN apt-get update && apt-get install -y \ libnccl2=2.16.2-1+cuda11.8 \ libnccl-dev=2.16.2-1+cuda11.8 # 设置环境变量 ENV NCCL_VERSION=2.16.2 ENV CUDA_VISIBLE_DEVICES=0,1,2,36. 版本兼容性参考
# NCCL与CUDA版本兼容性参考 compatible_versions: "CUDA 11.x": - "NCCL 2.8.x - 2.18.x" "CUDA 12.x": - "NCCL 2.16.x - 2.20.x" recommended_combinations: - "CUDA 11.8 + NCCL 2.16.2" - "CUDA 12.1 + NCCL 2.18.5"常见错误及解决方案
- NCCL版本不匹配:重新安装与CUDA版本兼容的NCCL
- GPU权限问题:确保用户有GPU访问权限
- 网络配置错误:在多节点环境中正确设置NCCL_SOCKET_IFNAME
- 内存不足:减少每个进程的GPU内存使用
通过系统性地按照上述流程排查,大多数NCCL初始化问题都能得到解决。
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2025-03-09 15:30bandaoyu的博客 NCCL (NVIDIA Collective Communications Library) 是 NVIDIA 推出的一个用于 GPU 之间高性能通信的库。深度学习模型规模巨大,单个 GPU 无法满足训练需求,需要将模型或数据分割到多个 GPU 上进行并行训练,NCCL ...
- Rust是一种系统编程语言,以其安全性和性能著称,但在此之前,Rust对CUDA的支持并不像C或C++那样成熟。这一环境的出现,极大地扩展了Rust语言的应用领域,尤其是在科学计算、机器学习、图形处理等需要高性能计算的...
- 2025-03-18 15:00己见明的博客 本文深入探讨了并行编程语言和模型,特别是CUDA和OpenCL在高性能计算中的应用。通过对比分析,揭示了CUDA与OpenCL在编程模型上的相似性,以及如何将CUDA中学习的概念应用到OpenCL编程中。文章还强调了并行编程的宏观...
- 2020-05-15 21:23cxu0262的博客 CUDA是Nvidia开发的一种并行计算平台和编程模型,用于在其自己的GPU(图形处理单元)上进行常规计算。 CUDA使开发人员能够利用GPU的能力来实现计算的可并行化部分,从而加快计算密集型应用程序的速度。 虽然还有...
- 2024-12-17 23:56小陈phd的博客 CUDA(Compute Unified Device Architecture)是由 NVIDIA 提供的一种并行计算平台和编程模型。它允许开发者利用 NVIDIA GPU 的并行计算能力,编写可以在 GPU 上高效运行的代码,从而加速计算密集型任务。CUDA 通过...
- 2025-12-29 15:21悦闻闻的博客 基于PyTorch-CUDA预配置镜像,实现开箱即用的多GPU...集成NCCL通信库,自动优化NVLink拓扑与梯度同步,显著提升训练效率。结合Docker与DDP,简化环境部署,支持高效数据加载与跨节点扩展,助力从实验到生产的无缝迁移。
- 2025-12-30 01:59来自日本的亮仔的博客 PyTorch-CUDA镜像是专为NVIDIA生态设计的,无法在Intel GPU上运行。根本原因在于CUDA是NVIDIA专属技术,而Intel GPU依赖oneAPI和IPEX扩展来实现加速,两者技术栈互不兼容。要在Intel显卡上运行PyTorch,需构建独立的...
- 2024-07-17 00:57黑不溜秋的的博客 这就是为什么英伟达™(NVIDIA®)公司在2007年推出的计算统一设备架构(CUDA)编程模型旨在支持CPU和GPU联合执行应用程序。 同样重要的是要注意,速度并不是应用程序开发人员选择处理器运行其应用程序时的唯一决定...
- 2025-12-30 04:02秦道衍的博客 深度学习训练提速的关键在于GPU并行计算,而CUDA正是PyTorch实现高效运算的核心支撑。它连接高层框架与底层硬件,通过显存管理、内核调度和专用数学库,让矩阵运算在毫秒间完成。环境配置、版本兼容与容器化部署则是...
- 2025-12-29 14:06已退乎的博客 PyTorch-CUDA-v2.7镜像深度整合NCCL通信库,解决多GPU训练中的通信瓶颈问题。通过预配置拓扑感知、P2P访问和最优算法切换,显著提升分布式训练稳定性与效率,避免常见如NCCL超时、带宽利用率低等问题,实现开箱即用...
- 2026-04-01 09:35泰恒的博客 历经18年迭代(截至2025年已至12.x版本),CUDA构建了覆盖从边缘设备(Jetson系列)到数据中心(H100/A100)的完整生态,成为全球AI、高性能计算(HPC)领域的事实标准,全球开发者数量突破400万。随着CANN开源,...
- 2026-02-20 08:51fpcc的博客 学习路线包括掌握编程语言、数学基础、并行编程等基础知识,深入CUDA框架、库应用、代码优化,以及分布式开发。最终需形成并行编程思想,整合软硬件知识。并行编程是复杂系统工程,需要持续学习与实践才能掌握。...
- 2021-10-02 13:065. **CUDA编程接口**:CUDA编程主要通过C/C++语言,使用头文件如`cuda.h`,`cublas.h`等,以及一系列的CUDA运行时API和CUDA驱动API来实现。CUDA内核函数(Kernel Functions)是定义在设备上的并行可执行代码,可以...
- 2024-08-15 19:57Polaris北极星少女的博客 CUDA C++ 编程指南 (nvidia.com)2. 编程模型2.1. 内核CUDA C++ 扩展了 C++,允许程序员定义 C++ 函数,称为内核,当被调用时,N 个不同的CUDA 线程并行执行 N 次,而不是像常规 C++ 函数那样只执行一次。内核是使用...
- 2026-01-06 13:14BE东欲的博客 海光DCU虽不原生兼容CUDA,但凭借类CUDA编程模型和PyTorch适配,可低代价迁移现有AI推理任务。结合轻量高效、专精数学与编程的VibeThinker-1.5B模型,已在国产平台实现可行部署。实际应用中需注意精度选择、提示词...
- 2025-03-13 00:58北冥的备忘录的博客 在 k 个等级之间的 sum allreduce作中,每个等级将提供一个包含 N 个值的数组,并在 N 个值的数组中接收相同的结果,其中 out[i] = in0[i]+in1[i]+…+in(k-1)[i]Reduce作执行与 AllReduce 相同的操作(操作是跨...
- 2025-03-29 09:22AI专题精讲的博客 其他计算设备(如 FPGA)虽然能效也很高,但其编程灵活性远不及 GPU。GPU 与 CPU 的能力差异源于它们的设计目标不同。CPU 旨在以最快速度执行单个线程(即一系列操作),并可并行执行数十个线程;而 GPU 则专为并行...
- 2016-07-08 13:59wishfly的博客 通用计算新锐OpenCL CUDA来助阵 GPU经过多年的发展,从功能单一的3D计算逐步扩充了视频解码、通用计算等,而且值得一提的是通用计算这个目前最璀璨的技术新星被科研单位及个人消费者普遍关注。 众所周知,...
- 2025-12-29 00:33诡道荒行的博客 通过Conda安装PyTorch时,需显式指定pytorch-cuda版本以启用GPU支持。...正确做法是在独立环境中使用-c pytorch和-c nvidia通道,结合pytorch-cudax.x虚拟包精确控制CUDA版本,避免pip与conda混用引发的依赖冲突。
- 2025-12-30 06:33深渊号角�~~~的博客 利用PyTorch-CUDA-v2.9容器镜像,可快速稳定地部署CodeLlama等大型编程模型。该方案解决了GPU驱动、框架与依赖库的版本兼容难题,结合4-bit量化和自动设备映射,使消费级显卡也能高效运行7B级以上模型,显著提升AI...
- 没有解决我的问题, 去提问


问题事件
已采纳回答 11月7日
创建了问题 11月6日