
遇到问题的现象描述
在使用 Selenium 爬取网页时,始终无法定位到目标元素,先后出现 NoSuchElementException 和 TimeoutException 异常,即使尝试了调整 XPath,仍无法成功获取元素。
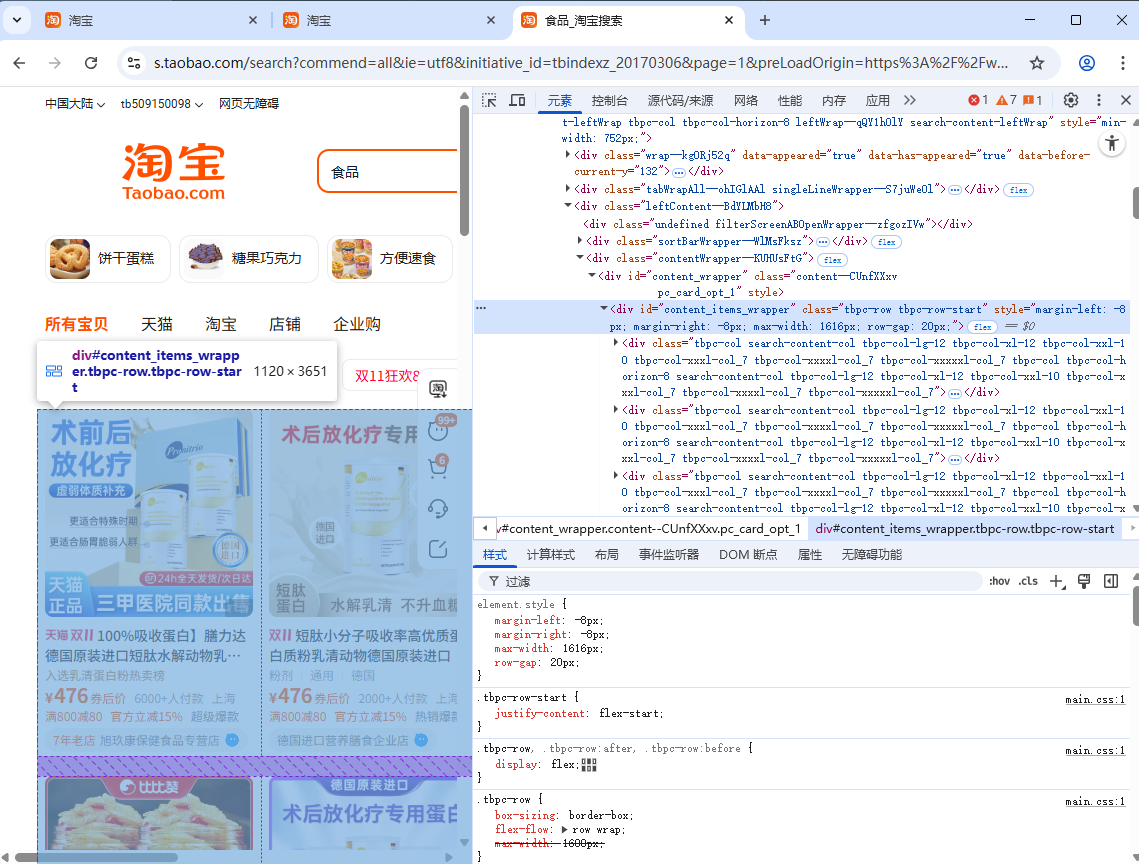
def get_product():
items = brower.find_element(By.XPATH, '//*[@class="tbpc-row tbpc-row-start"]/div')
print(items)
运行后报错:
selenium.common.exceptions.TimeoutException: Message:
Stacktrace:
Symbols not available. Dumping unresolved backtrace:...
操作环境、软件版本等相关信息
操作系统:Windows
Python 版本:3.13
浏览器:Chrome 142.0.7444.135
浏览器驱动:ChromeDriver 匹配浏览器版本
还望各位好人帮帮忙,不胜感激






