为什么爬取京东商品评论时总是显示爬取异常啊?有没有大拿可以说说问题出在哪里了?应该怎么改啊orz
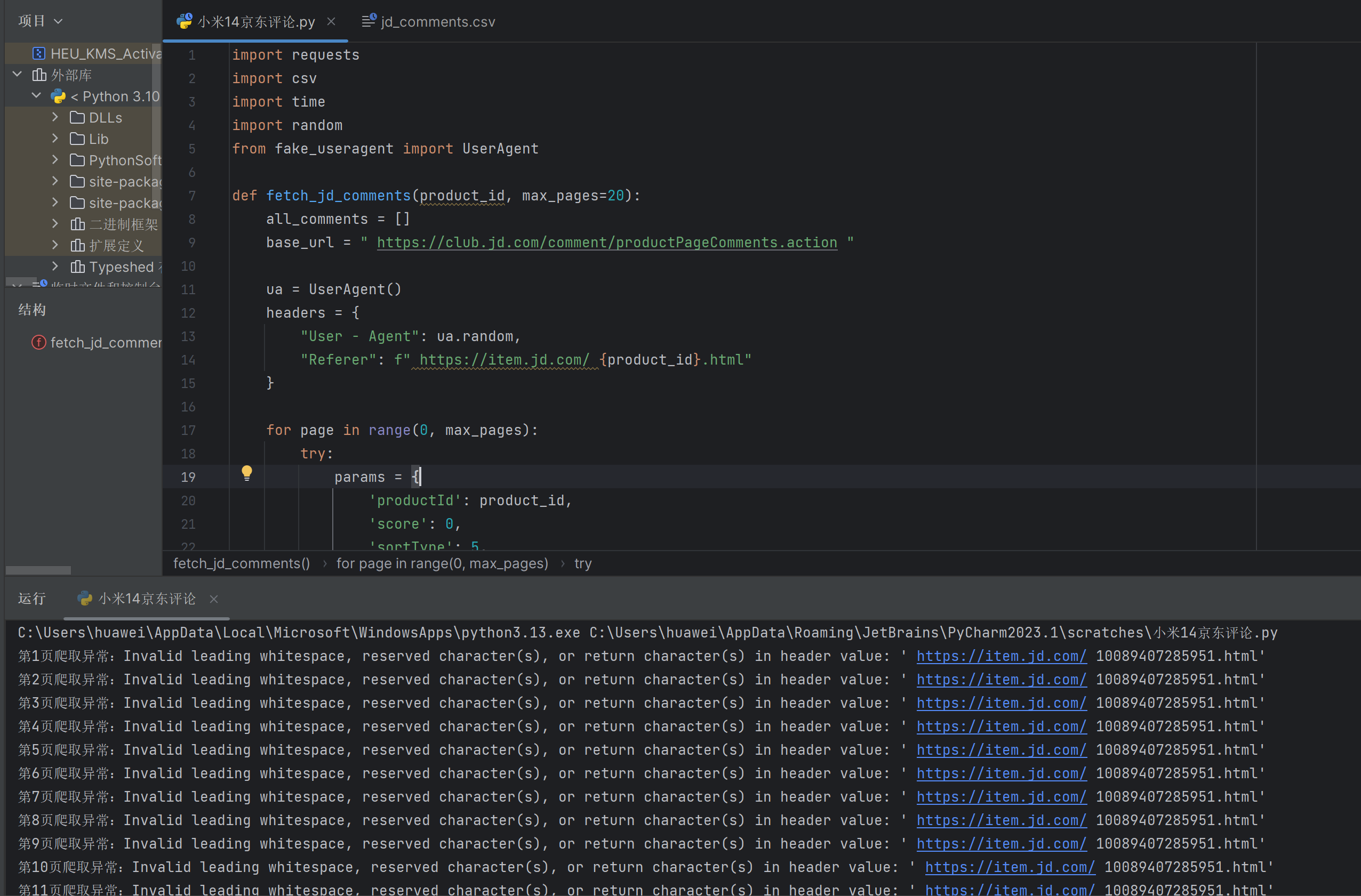

为什么爬取京东商品评论时总是显示爬取异常啊?有没有大拿可以说说问题出在哪里了?应该怎么改啊orz
 分享
分享
 关注
关注让 “紫雾凌寒” 来帮你回答,本回答结合 DeepSeek
如果还有问题,请评论或点击头像私信,如果有帮助到您, 请关注、采纳、点赞
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get('https://example.com', headers = headers)
import time
# 爬取一次后等待1秒
time.sleep(1)
from bs4 import BeautifulSoup
html = """网页内容"""
soup = BeautifulSoup(html, 'html.parser')
comments = soup.find_all('div', class_='comment-content')
for comment in comments:
print(comment.text)
希望以上解答对您有所帮助。如果您有任何疑问,欢迎在评论区提出。
分享 创建了问题
11月13日
创建了问题
11月13日

