
创建docker的指令:docker run -d -v /usr/src:/usr/src -v /lib/modules:/lib/modules -v /dev:/dev -v /data:/data --privileged --cap-add=ALL --pid=host --net host --shm-size=32gb --name vllm_distributed --entrypoint /bin/bash vllm_infer:0805 -c "sleep infinity"
当前使用的是国产的GPU:Iluvatar MR-V100,vllm版本是0.6.3,cuda版本是10.2,ray启动命令为ray start --block --head --port=6379 --num-gpus=1 --object-store-memory=10000000000。配置是双机单卡,ray status能够显示两个节点和2个GPU资源。
启动vllm的server指令为vllm serve /data/models/Qwen2.5-14B-Instruct-GPTQ-Int8 --served-model-name Qwen2.5-14B-Instruct-GPTQ-Int8 --tensor-parallel-size 2 --trust-remote-code --max-model-len 10240 \,但是运行的时候却迟迟不能加载上模型,日志不显示错误,终端返回的是
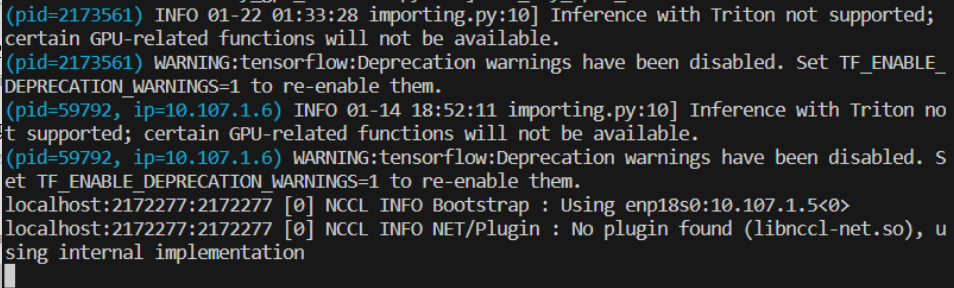
同时查看显存占用,发现占用率异常的低
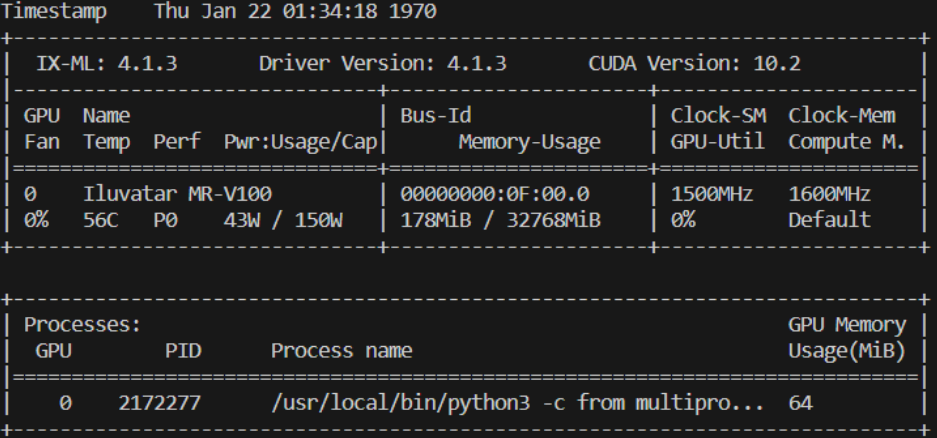
但是把tensor_parallel改成1,单卡的时候能够加载成功并正常运行。请问这是什么原因,求帮助






